На этом шаге рассмотрим еще один пример использования хеш-таблиц.
Хеш-таблицы можно использовать для поиска соответствий в гораздо большем масштабе.
Пример 1. Вы хотите перейти на веб-сайт - допустим http://kgsu.ru. Ваш компьютер должен преобразовать символическое имя kgsu.ru в IР-адрес:
Для любого посещаемого веб-сайта его имя преобразуется в IР-адрес. Идеальная задача для хештаблиц! Этот процесс называется преобразованием DNS. Хеш-таблицы - всего лишь один из способов реализации этой функциональности.
Пример 2. Исключение дубликатов. Предположим, вы руководите избирательным участком. Естественно, каждый избиратель может проголосовать всего один раз. Как проверить, что он не голосовал ранее? Когда человек приходит голосовать, вы узнаете его полное имя, а затем проверяете по списку уже проголосовавших избирателей.
Если имя входит в список, значит, этот человек уже проголосовал. В противном случае вы добавляете имя в список и разрешаете ему проголосовать. Теперь предположим, что желающих проголосовать много и список уже проголосовавших достаточно велик.
Каждый раз, когда кто-то приходит голосовать, вы вынуждены просматривать этот гигантский список и проверять, голосовал он или нет. Однако существует более эффективное решение: воспользоваться хешем!
Сначала создадим хеш для хранения информации об уже проголосовавших людях:
voted = {}Когда кто-то приходит голосовать, проверьте, присутствует ли его имя в хеше:
value = voted.get("Иванов")Функция get возвращает значение, если ключ "Иванов" присутствует в хештаблице. В противном случае возвращается None. С помощью этой функции можно проверить, голосовал избиратель ранее или нет!
Код выглядит так:
voted = {}
def check_voter (name):
if voted.get(name):
print "Не голосует!"
else:
voted[name] = True
print "Голосует!"Протестируем его на нескольких примерах:
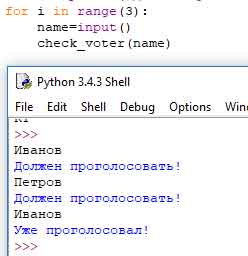
Когда Иванов приходит на участок в первый раз, программа разрешает ему проголосовать. Потом приходит Петров который тоже допускается к голосованию. Но потом Иванов делает вторую попытку, и на этот раз у него ничего не получается.
Если бы имена проголосовавших хранились в списке, то выполнение функции со временем замедлилось бы, потому что функции пришлось бы проводить простой поиск по всему списку. Но имена хранятся в хештаблице, а хеш-таблица мгновенно сообщает, присутствует имя избирателя в списке или нет. Проверка дубликатов в хеш-таблице выполняется очень быстро.
Пример 3. Использование хеш-таблицы как кэша. Если вы работаете над созданием веб-сайтов, вероятно, вы уже слышали о пользе кэширования. Общая идея кэширования такова: допустим, вы заходите на сайт facebook.com:
- Вы обращаетесь с запросом к серверу Facebook.
- Сервер ненадолго задумывается, генерирует веб-страницу и отправляет ее вам.
- Вы получаете веб-страницу.
Например, на Facebook сервер может собирать информацию о действиях всех ваших друзей, чтобы представить ее вам. На то, чтобы собрать всю информацию и передать ее вам, требуется пара секунд. С точки зрения пользователя, пара секунд - это очень долго. С другой стороны, серверам Facebook приходится обслуживать миллионы людей, и эти пары секунд для них суммируются. Серверы Facebook трудятся в полную силу, чтобы сгенерировать все эти страницы. Нельзя ли как-то ускорить работу Facebook при том, чтобы серверы выполняли меньше работы?
Представьте, что к вам обращаются с вопросами о планетах: "Сколько километров от Земли до Марса?", "А сколько километров до Луны?", "А до Юпитера?" Каждый раз вы вводите запрос в Google и сообщаете ответ. На это уходит пара минут. А теперь представьте, что вас всегда спрашивает: "Сколько километров от Земли до Луны?" Довольно быстро вы запоминаете, что Луна находится на расстоянии 384 400 километров от Земли. Искать информацию в Google не нужно ... Вы просто запоминаете и выдаете ответ. Вот так работает механизм кэширования: сайт просто запоминает данные, вместо того чтобы пересчитывать их заново.
Если вы вошли на Facebook, то весь контент, который вы видите, адаптирован специально для вас. Каждый раз, когда вы заходите нa facebook.com, серверам приходится думать, какой контент вас интересует. Если же вы не ввели учетные данные на Facebook, то вы видите страницу входа. Все пользователи видят одну и ту же страницу входа. Facebook постоянно получает одинаковые запросы: "Я еще не вошел на сайт, выдайте мне домашнюю страницу". Сервер перестает выполнять лишнюю работу и генерировать домашнюю страницу снова и снова. Вместо этого он запоминает, как выглядит домашняя страница, и отправляет ее вам.
Такой механизм хранения называется кэшированием. Он обладает двумя преимуществами:
- вы получаете веб-страницу намного быстрее, как и в том случае, когда вы запомнили расстояние от Земли до Луны. Когда в следующий раз вам зададут подобный вопрос, вам не придется гуглить. Вы можете выдать ответ мгновенно;
- Facebook приходится выполнять меньше работы.
Кэширование - стандартный способ ускорения работы. Все крупные вебсайты применяют кэширование. А кэшируемые данные хранятся в хеше! Facebook не просто кэширует домашнюю страницу. Также кэшируются страницы "О нас", "Условия использования" и многие другие. Следовательно, необходимо создать связь URL-aдpeca страницы и данных страницы.

Когда вы посещаете страницу на сайте Facebook, сайт сначала проверяет, хранится ли страница в хеше.
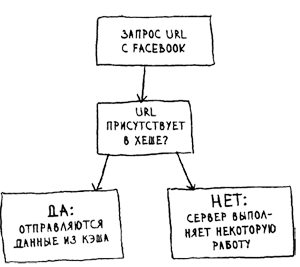
Вот как это выглядит в коде:
cache = {}
def get_page(url):
if cache.get(url):
return cache [url]
else:
data = get_data_from_server(url)
cache[url] = data
return dataЗдесь сервер выполняет работу только в том случае, если URL не хранится в кэше. Однако перед тем, как возвращать данные, вы сохраняете их в кэше. Когда пользователь в следующий раз запросит тот же URL-aдpec, данные можно отправить из кэша (вместо того чтобы заставлять сервер выполнять работу).
Архив с примером на языке Python можно взять здесь.
На следующем шаге рассмотрим понятие коллизии.
