На этом шаге мы рассмотрим использование рекурсии для построения дерева.
В структурах возможна рекурсия, т. е. структуры могут ссылаться сами на себя. Допустим, у нас имеется списковая структура типа:
"Слово (строка символов)", "Счетчик количества каждого искомого слова в тексте", "Указатель на предыдущую структуру, в которой встречается данное слово", "Указатель на последующую структуру, в которой встречается данная строка".
Такая структура может быть представлена в виде рекурсивного шаблона с указателем на такую же структуру:
struct tnod // (***) { char *word; int count; tnod *left; tnod *right; } t, *p;
Если, например, p=&t, то доступ к элементам структуры будет таким:
p->word, p->left, p->right
Приведем пример программы, подсчитывающей количество встречающихся в некотором тексте слов. Эта программа передает введенные с клавиатуры слова специальной функции, которая по ним строит в памяти так называемое "двоичное дерево".
Примечание. Двоичное дерево - это такая конструкция, которая отображает связь между данными исходя из того, что данные находятся в так называемых узлах. Под узлом понимается переменная типа "структура" (ее еще называют записью). Первая запись двоичного дерева (его корень) содержит один узел. В узле содержится некая полезная информация, для обработки которой мы и строим само дерево, а также два указателя на нижестоящие узлы. Из корневого узла "вырастают" всего две "веточки": левый нижний узел (первый указатель) и правый нижний узел (второй указатель). Из каждого из этих узлов тоже "вырастают" по две "веточки" и т. д. Можно сказать, что в такой конструкции каждый узел - это тоже двоичное дерево (корень, из которого выходят две "веточки").
Рассмотрим правила построения двоичного дерева в нашем случае.
Никакой узел этого дерева не содержит более двух ближайших потомков (детей).
В корневом узле слова нет.
Первое поступившее слово записывается в корневой узел, а остальные поступающие будут распределяться так: если поступившее слово меньше первого, то оно записывается в левое поддерево, если больше корневого - в правое.
Каждое слово будет находиться в структуре типа (***).
Адрес слова помещается в переменную word, а счетчик count в данной структуре устанавливается в единицу: слово пока что встретилось (в нашем случае введено) один раз.
Если встретится еще такое же слово, то к счетчику count в данной структу добавится единица. При этом в корневой структуре в переменной left формируется указатель на структуру, в которую записалось слово меньшее, чем слово в корневой структуре. Если же поступило слово, которое больше слова в корневой структуре, то оно записывается, как уже говорилось, в отдельную структуру (узел), а указатель на этот узел записывается в переменную right корневой структуры.
Потом вводится третье слово. Оно опять сравнивается со словами, наход щимися в структурах дерева (***), начиная с корневой структуры и далее по тем же принципам, что описаны ранее. Если поступившее слово меньше корневого, то дальнейшее сравнение идет в левой части дерева. Это означает, что из корневой структуры выбирается указатель, хранящийся в переменной left, по нему отыскивается следующее (меньшее, чем в данном узле) слово, с которым и станет сравниваться поступившее. Если поступившее слово меньше, то из нового узла извлекается указатель, хранящийся в переменной left, и по нему выбирается следующий "левый" узел и т. д.
Если же больше узла нет (в последнем узле left будет ноль), то поступивше слово записывается в новый формируемый узел, в обе части left и right которого записываются нули (признак того, что этот узел последний). Если же на каком-то этапе поступившее слово оказывается больше, чем слово в левом узле, то рассматривается указатель right этого узла и по нему определяется структура (узел), где находится следующее (меньшее этого) слово, с которым станет сравниваться поступившее. Если оно окажется больше, то дальше пойдет проверка следующей "правой" структуры и сравнение с ее данными, если же меньше, то процесс перейдет на левую часть поддерева: движение по сравнению пойдет по "левым" структурам.
В итоге получим двоичное дерево: от каждого узла будут выходить не более двух подузлов и таких, что в левом подузле всегда будет слово, меньшее, чем в самом узле, а в правом подузле всегда будет находиться слово большее, чем в самом узле. Так как физически каждое слово будет находиться в отдельной структуре типа (***), то в этой же структуре в переменных left и right будут располагаться указатели на структуры, где хранятся подузлы данной структуры. И все это дерево располагается в памяти.
Программа, реализующая рекурсию в структурах, приводится ниже. На рисунке 1 отражен результат выполнения этой программы.
// 66_1.cpp: главный файл проекта. #include "stdafx.h" #include <clocale> //обязательно для функции setlocale() #include <stdio.h> #include <conio.h> #include <string.h> //strcpy() #define MAXLINE 1000 #define eof -1 using namespace System; //--- Ввод строки с клавиатуры --- int getline(char s[], int lim) { int c,i; for(i=0; i<lim-1 && (c=getchar()) != eof && c != '\n'; i++) s[i] = c; s[i] = '\0'; i++; //для учета количества return i; } // ----------------- struct tnod //базовый узел { char* word; //значение переменной - символьная строка в узле //(слово) int count; //здесь накапливается число встреч данного слова tnod *left; //левый потомок: здесь хранится указатель на левый //подузел, т. е. на структуру, в которой хранится слово, //меньшее данного. Если слов меньших данного нет, //то здесь хранится ноль tnod *right;//правый потомок: здесь хранится указатель на правый //подузел, т. е. на структуру, в которой хранится слово, //большее данного. Если слов больших данного нет, то здесь хранится ноль }; // ----------------- char *strsave(char *s) { //Функция выделяет память по длине строки s, и в эту память //помещает саму строку s, а затем выдает указатель на //начало помещенной в буфер строки. char* p = new char [strlen(s)+1]; if((p != NULL)) strcpy(p,s); return p; } // ----------------- tnod* NodAlloc(void) { //Функция выделяет память под структуру tnod и //возвращает указатель на эту память tnod* p = new tnod; return p; } // ----------------- tnod* MakeTree(tnod *p, char *w) //Эта функция формирует двоичное дерево. //р - указатель на структуру, по которой будет создаваться //новый узел или будут проверяться старые узлы. //w - слово, поступающее для его поиска в дереве. //Если такое слово уже есть, то в счетчик структуры, где оно //обнаружено, добавляется единица: подсчитывается, сколько //одинаковых слов. //Если такого слова в дереве нет, то для него образуется //новый узел (новая структура) { int cond; if( p == NULL) //появилось новое слово. Для этого слова //еще нет узла и его надо создать { p = NodAlloc(); //выделяется память под новый узел p->word = strsave(w); //введенное слово по strsave() записывается в память //и на него выдается указатель p->count = 1; // слово пока единственное p->left = p->right = NULL; //т. к. это слово пока последнее в дереве, то этот узел //не указывает на следующие (меньшие - слева или //большие - справа) слова дерева } else if( ( cond=strcmp(w, p->word) ) == 0 ) //слово не новое, тогда оно сравнивается со словом //в узле, на который Указывает указатель р p->count++; //в этом узле - такое же слово, поэтому добавляем к //счетчику единицу else if( cond < 0 ) //слово меньше того, которое в узле, поэтому //его помещаем в левую часть опять же с помощью этой функции. //Ее первая часть создаст узел в динамической памяти, //поместит в него слово, в левые и правые подузлы поместит //нули, т.к. пока дальше этого слова ни справа, ни слева //ничего нет, а в левую часть узла-предка поместит указатель //на эту структуру p->left = MakeTree(p->left,w); else if( cond > 0 ) p->right = MakeTree(p->right, w); //слово больше того, которое в узле, поэтому мы его помещаем //в правую часть дерева опять же с помощью этой же функции: ее //первая часть создаст узел в динамической памяти, поместит в него //слово, в левые и правые подузлы поместит нули, т. к. пока дальше //этого слова ни справа, ни слева ничего нет, а в правую часть //узла-предка поместит указатель на эту структуру. return p; //возвращает указатель на область, где создана новая структура, или на //структуру, в которую добавлена единица, т. к. поступившее слово //совпало со словом в этой структуре } // ----------------- void TreePrint(tnod *p) //left_right=1 при выводе левого узла и = 2 - при выводе правого узла //Эта функция печатает или выводит на экран все дерево, рекурсивно себя вызывая* { if(p != NULL) //p всегда указывает на начало дерева. //p != NULL - дерево существует { //Left = ссылка на левый подузел, right - на правый. //Эти ссылки могут быть нулевыми: дерево дальше не идет printf("Слово = %s количество = %d\n",p->word, p->count); TreePrint(p->left); //выводит левый узел TreePrint(p->right); //выводит правый узел } } // ----------------- void main() { setlocale(LC_ALL,"Russian"); //функция setlocale() с аргументами //для корректного вывода кириллицы tnod *pp = NULL; char s[MAXLINE]; int i=0; printf("Задайте слова: >\n"); while(getline(s,MAXLINE)-1) //getline() возвращает количество введенных символов //Когда нажимаем только <Enter>, вводится всего один символ ('\n'). //Если от единицы отнять единицу, получим ноль, а это - для цикла while //сигнал о прекращении цикла { pp = MakeTree(pp,s); // формирует очередной узел // рр всегда указывает на начало дерева } //while TreePrint(pp); //вывод дерева _getch(); }
Результат работы приложения:
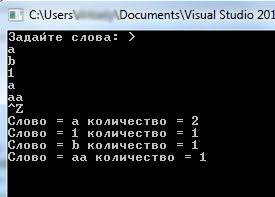
Рис.1. Результат работы приложения
На рисунке 2 приведена структура дерева (в скобках указано значение поля count).
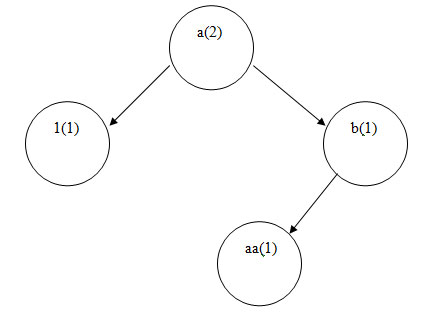
Рис.2. Физическая структура дерева
На следующем шаге мы рассмотрим битовые поля в структурах.
