На этом шаге мы рассмотрим использование некоторых основных алгоритмов.
STL поддерживает несколько стандартных алгоритмов, предназначенных для обработки элементов коллекций. Под обработкой понимается выполнение таких стандартных операций, как поиск, сортировка, копирование, переупорядочение, модификация и численные расчеты.
Алгоритмы не являются функциями контейнерных классов - это глобальные функции, работающие с итераторами. У такого подхода есть одно важное достоинство: вместо того чтобы реализовывать каждый алгоритм для каждого типа контейнера, достаточно реализовать его один раз для обобщенного типа контейнера. Алгоритм может работать даже с элементами контейнеров разных типов, в том числе определенных пользователем. В конечном счете такой подход сокращает объем программного кода, делая библиотеку более мощной и гибкой.
Обратите внимание: речь идет не о парадигме объектно-ориентированного программирования, а об общей парадигме функционального программирования. Вместо того чтобы объединять данные с операциями, как в объектно-ориентированном программировании, мы разделяем их на части, взаимодействующие через некоторый интерфейс. Впрочем, у такого подхода есть свои обратные стороны: во-первых, он недостаточно интуитивен. Во-вторых, некоторые комбинации структур данных и алгоритмов могут оказаться недопустимыми или, что еще хуже, допустимыми, но бесполезными (например, обладающими недостаточным быстродействием). Таким образом, очень важно изучить основные возможности и потенциальные опасности STL, чтобы использовать все достоинства библиотеки и благополучно обойти ловушки.
Начнем с простого примера, демонстрирующего некоторые алгоритмы STL и принципы их использования:
//--------------------------------------------------------------------------- #include <vcl.h> #include <iostream> #include <vector> #include <algorithm> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } int main(int argc, char* argv[]) { vector<int> coll; vector<int>::iterator pos; // Вставка элементов от 1 до 6 в произвольном порядке coll.push_back(2); coll.push_back(5); coll.push_back(4); coll.push_back(1); coll.push_back(6); coll.push_back(3); // Поиск и вывод минимального и максимального элементов pos = min_element (coll.begin(),coll.end()); cout << "min: " << *pos << endl; pos = max_element (coll.begin(), coll.end()); cout << "max: " << *pos << endl; // Сортировка всех элементов sort (coll.begin(), coll.end()); cout << ToRus("Отсортированные элементы:\n"); for (pos = coll.begin(); pos != coll.end(); ++pos) { cout << *pos << ' '; } // Поиск первого элемента со значением, равным 3 pos = find (coll.begin(), coll.end(), // Интервал 3); // Значение // Перестановка найденного элемента со значением 3 // и всех последующих элементов в обратном порядке reverse (pos, coll.end()); // Вывод всех элементов cout << ToRus("\nЭлементы после перестановки:\n"); for (pos = coll.begin(); pos != coll.end(); ++pos) { cout << *pos << ' '; } getch(); return 0; } //---------------------------------------------------------------------------
Чтобы использовать алгоритмы в программе, необходимо включить в нее заголовочный файл <algorithm>:
#include <a1gorithm>
Первые два алгоритма называются min_element() и max_element(). При вызове им передаются два параметра, определяющих интервал обрабатываемых элементов. Чтобы обработать все содержимое контейнера, просто используйте вызовы begin() и end(). Алгоритмы возвращают итераторы соответственно для минимального и максимального элементов. Таким образом, в показанной ниже команде алгоритм min_element() возвращает позицию минимального элемента (если таких элементов несколько, алгоритм возвращает позицию первого из них):
pos = min_element (coll.begin(), coll.end());
Следующая команда выводит найденный элемент:
cout << "min: " << *pos << endl;
Разумеется, поиск и вывод можно объединить в одну команду:
cout << *min_element(coll.begin(),coll .end()) << endl;
Следующим вызывается алгоритм sort(). Как нетрудно догадаться по названию, этот алгоритм сортирует элементы в интервале, определяемом двумя аргументами. Как обычно, вы можете задать собственный критерий сортировки. По умолчанию сортировка осуществляется с использованием оператора <. Таким образом, следующая команда сортирует все элементы контейнера по возрастанию:
sort (coll.begin(), coll.end());
В конце концов элементы вектора будут расположены в следующем порядке: 1 2 3 4 5 6.
Алгоритм find() ищет значение в заданном интервале. В нашем примере во всем контейнере ищется первый элемент со значением 3:
pos = find (coll.begin(), coll.end(), // Интервал 3); // Значение
Если поиск оказался успешным, алгоритм find() возвращает итератор, установленный на первый найденный элемент. В случае неудачи возвращается итератор для позиции за концом интервала, определяемым вторым переданным аргументом. В нашем примере значение 3 находится в третьем элементе, поэтому pos ссылается на третий элемент coll.
Последним вызывается алгоритм reverse(), который переставляет элементы переданного интервала в обратном порядке. В аргументах передается третий элемент, найденный алгоритмом find(), и конечный итератор:
reverse (pos, coll.end());
Результат работы программы выглядит так:
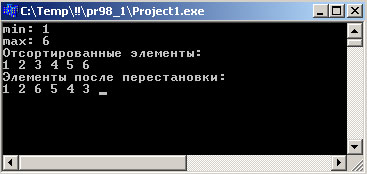
Рис.1. Результат работы приложения
На следующем шаге мы рассмотрим интервалы.
