На этом шаге мы рассмотрим использование потоковых итераторов.
Потоковые адаптеры составляют еще одну чрезвычайно полезную разновидность итераторпых адаптеров. Под этим термином понимаются итераторы, обеспечивающие чтение из потока данных и запись в поток данных. Иначе говоря, потоковые итераторы позволяют интерпретировать ввод с клавиатуры как коллекцию, из которой можно читать данные. Аналогично, вы можете перенаправить результаты работы алгоритма в файл или на экран.
Рассмотрим типичный пример, убедительно подтверждающий возможности STL. По сравнению с "чистой" реализацией С или C++ эта программа выполняет довольно большой объем работы всего в нескольких командах:
//--------------------------------------------------------------------------- #include <vcl.h> #include <iostream> #include <iterator> #include <vector> #include <string> #include <algorithm> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } int main(int argc, char* argv[]) { vector<string> coll; // Загрузка слов из стандартного входного потока данных // - источник: все строки до конца файла (или до возникновения ошибки) // - приемник: coll (вставка) cout << ToRus("Задайте слова (выход - CTRL+Z):\n"); copy (istream_iterator <string> (cin), // Начало источника istream_iterator <string> (), // Конец источника back_inserter(coll)); //Приемник // Сортировка элементов sort (coll.begin(),coll.end()); // Вывод всех элементов без дубликатов // - источник: coll // - приемник: стандартный вывод (с разделением элементов // символом новой строки) cout << ToRus("Отсортированные слова:\n"); unique_copy (coll.begin(), coll.end(), // Источник ostream_iterator<string>(cout,"\n")); // Приемник cout << endl; getch(); return 0; } //---------------------------------------------------------------------------
Программа, фактически состоящая всего из трех команд, читает все слова из стандартного входного потока данных и выводит их в отсортированном виде (рисунок 1).
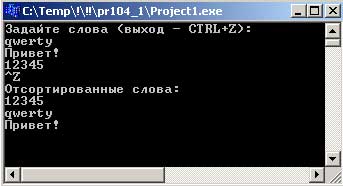
Рис.1. Результат работы приложения
Давайте последовательно рассмотрим каждую из этих трех команд. В первой команде используются два потоковых итератора ввода:
copy (istream_iterator <string> (cin), // Начало источника istream_iterator <string> (), // Конец источника back_inserter(coll)); //Приемник
- Выражение istream_iterator<string> (cin) создает потоковый итератор для чтения из стандартного входного потока
данных cin. Аргумент string определяет тип элементов, читаемых потоковым итератором.
Элементы читаются стандартным оператором ввода >>. Каждый раз, когда алгоритм пытается обработать следующий
элемент, потоковый итератор ввода преобразует эту попытку в вызов:
cin >> строка
Оператор чтения строк обычно читает отдельное "слово", отделенное пропуском от следующего слова, поэтому алгоритм вводит данные по словам.
- Выражение istream_iterator<string>() вызывает конструктор по умолчанию и создает конечный потоковый итератор. Он представляет поток данных, дальнейшее чтение из которого невозможно. Как обычно, алгоритм сору() продолжает работать до тех пор, пока первый (наращиваемый) аргумент не сравняется со вторым аргументом. Конечный потоковый итератор определяет конец обрабатываемого интервала; следовательно, алгоритм будет читать все строки из cin до тех пор, пока дальнейшее чтение станет невозможным (из-за достижения конца потока данных или из-за ошибки).
Подведем итог: источником данных для алгоритма сору() являются "все слова из cin". Прочитанные слова копируются в coll конечным итератором вставки.
Алгоритм sort() сортирует все содержимое коллекции:
sort (coll.begin(),coll.end());
Наконец, следующая команда копирует все элементы коллекции в приемник cout:
unique_copy (coll.begin(), coll.end(), // Источник ostream_iterator<string>(cout,"\n")); // Приемник
В процессе копирования алгоритм unique_copy исключает из копируемых данных дубликаты. Представленное ниже выражение создает потоковый итератор вывода, который записывает string в выходной поток данных cout, вызывая оператор << для каждого элемента:
ostream_iterator<string>(cout,"\n")); // Приемник
Второй аргумент определяет разделитель, выводимый между элементами. Передавать этот аргумент не обязательно. В нашем примере разделителем является символ новой строки, поэтому каждый элемент будет выводиться в отдельной строке.
Все компоненты программы реализованы в виде шаблонов, поэтому программа легко адаптируется для сортировки других типов данных (например, целых чисел или более сложных объектов).
На следующем шаге мы рассмотрим обратные итераторы.
