На этом шаге мы рассмотрим примеры выбора различных контейнеров.
Ниже приведены две простые программы, которые сортируют строки, прочитанные из стандартного входного потока данных, и выводят их без дубликатов. Задача решается с применением двух разных контейнеров.
Решение с использованием множества:
//--------------------------------------------------------------------------- #include <vcl.h> #include <iostream> #include <iterator> #include <string> #include <set> #include <algorithm> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } int main(int argc, char* argv[]) { // Создание строкового множества // - инициализация словами, прочитанными из стандартного ввода cout << ToRus("Исходные слова:\n"); set<string> coll((istream_iterator<string>(cin)), istream_iterator<string>()); // Вывод всех элементов cout << ToRus("Введенные слова (без повторений):\n"); copy (coll.begin(),coll.end(), ostream_iterator<string> (cout, "\n")); getch(); return 0; } //---------------------------------------------------------------------------
Результат выполнения программы выглядит так:
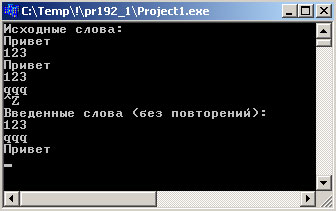
Рис.1. Результат работы приложения
Решение с использованием вектора:
//--------------------------------------------------------------------------- #include <vcl.h> #include <iostream> #include <iterator> #include <string> #include <vector> #include <algorithm> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } int main(int argc, char* argv[]) { // Создание строкового вектора // - инициализация словами, прочитанными из стандартного ввода cout << ToRus("Исходные слова:\n"); vector<string> coll((istream_iterator<string>(cin)), istream_iterator<string>()); // Сортировка элементов sort (coll.begin(), coll.end()); // Вывод всех элементов с подавлением дубликатов cout << ToRus("Введенные слова (без повторений):\n"); unique_copy (coll.begin(),coll.end(), ostream_iterator<string>(cout, "\n")); getch(); return 0; } //---------------------------------------------------------------------------
Результат выполнения программы выглядит так:
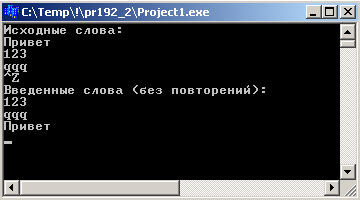
Рис.2. Результат работы приложения
Когда обе программы были запущены с тестовым набором из 150 000 строк, векторная версия работала примерно на 10 % быстрее. Включение вызова reserve() ускорило ее еще на 5 %. Если разрешить наличие дубликатов (использование типа multiset вместо set и вызов сору() вместо unique_copy()), ситуация кардинально меняется: векторная версия работает еще на 40 % быстрее! Такие показатели нельзя считать типичными, однако они доказывают, что во многих случаях стоит опробовать разные варианты обработки элементов.
На практике ипогда бывает трудно предсказать, какой тип контейнера лучше подходит для конкретной задачи. Одно из больших достоинств STL заключается в том, что вы можете относительно легко опробовать разные варианты. Основная работа - реализация структур данных и алгоритмов - уже выполнена. Вам остается лишь скомбинировать ее результаты оптимальным образом.
На следующем шаге мы рассмотрим типы и функции контейнеров.
