На этом шаге мы рассмотрим еще один пример использования строк.
Во втором примере отдельные слова читаются из стандартного входного потока данных и символы каждого слова выводятся в обратном порядке. Слова разделяются стандартным символом пропуска (пробелом, новой строкой, табуляцией), запятой, точкой с запятой или двоеточием.
//--------------------------------------------------------------------------- #include <vcl.h> #include <iostream> #include <string> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } int main (int argc, char* argv[]) { const string delims(" \t,.;"); string line; // Для каждой успешно прочитанной строки while (getline(cin,line)) { string::size_type begIdx, endIdx; // Поиск начала первого слова begIdx = line.find_first_not_of(delims); // Пока удается найти начало очередного слова... while (begIdx != string::npos) { // Поиск конца текущего слова endIdx = line.find_first_of (delims, begIdx); if (endIdx == string::npos) { // Конец слова совпадает с концом строки endIdx = line.length(); } // Вывод символов в обратном порядке for (int i=endIdx-1; i>=static_cast<int>(begIdx); --i) { cout << line[i]; } cout << ' '; // Поиск начала следующего слова begIdx = line.find_first_not_of (delims, endIdx); } cout << endl; } getch(); return 0; } //---------------------------------------------------------------------------
Прокомментируем приведенную программу.
В этой программе все символы, используемые для разделения слов, определяются в специальной строковой константе:
const string delims (" \t.,;");
Символ новой строки тоже используется как разделитель. Тем не менее он не требует особой обработки, поскольку программа читает данные по строкам.
Внешний цикл работает до тех пор, пока в переменную line успешно читается очередная строка:
string line;
while (getline(cin.line)) {
. . .
}
Функция getllne() предназначена для чтения из потока данных в строковую переменную. Она читает все символы до ближайшего разделителя строк, которым по умолчанию является символ новой строки. Разделитель извлекается из потока данных, но не присоединяется к прочитанным данным. Передавая собственный разделитель строк в необязательном третьем аргументе, можно перевести функцию getline() в режим чтения лексем, разделенных заданными символами.
Внутри внешнего цикла производится поиск и вывод отдельных слов. Первая команда ищет начало первого слова;
begIdx = line.find_first_not_of(delims);
Функция find_first_not_of() возвращает индекс первого символа, не входящего в переданный строковый аргумент. Иначе говоря, функция возвращает первый символ, не указанный в переменной delims как разделитель. Как и прочие функции поиска, при отсутствии совпадения функция find_first_not_of() возвращает string::npos.
Внутренний цикл выполняется до тех пор, пока в потоке данных обнаруживается начало очередного слова:
while (begIdx != string::npos) {
. . . .
}
Первая команда внутреннего цикла ищет конец текущего слова:
endIdx = line.find_first_of (delims, begIdx);
Функция find_first_of() ищет первое вхождение одного из символов, составляющих первый аргумент. Необязательный второй аргумент определяет позицию, с которой начинается поиск. В нашем случае он начинается за началом слова.
Если символ не найден, конец слова совпадает с концом строки:
if (endIdx == string::npos) {
endIdx = line.length());
. . . .
Количество символов определяется при помощи функции length(), которая для строк эквивалентна функции size().
В следующей команде все символы слова выводятся в обратном порядке:
for (int i=endIdx-1; i>=static_cast<int>(begIdx); --i) { cout << line[i]; }
Для обращения к отдельным символам строки используется оператор []. Помните, что этот оператор не проверяет действительность индекса. Это означает, что вы должны сами заранее убедиться в правильности индекса (как это сделано в нашем примере). Более безопасный способ обращения к символам основан на применении функции at(). Лишние проверки замедляют работу программы, поэтому обычно при обращении к символам указанная проверка не предусмотрена.
С индексами строк связана и другая неприятная проблема. Если забыть о приведении типа begIdx к типу int, возможно зацикливание или аварийное завершение программы. Как и в первом примере, это объясняется тем, что string::size_type является беззнаковым целым типом. Без преобразования типа знаковое значение i автоматически преобразуется в беззнаковое значение из-за сравнения с другим беззнаковым значением. В этом случае выражение i>=begIdx всегда равно true, если текущее слово начинается с начала строки. Дело в том, что переменная begIdx в этом случае равна 0, а любое беззнаковое значение всегда больше либо равно нулю. Программа зацикливается и прерывается только в результате сбоя при нарушении защиты памяти.
По этой причине мы стараемся избегать применения конструкций string::size_type и string::npos.
Последняя команда внутреннего цикла переводит begIdx к началу следующего слова, если его удается найти:
begIdx = line.find_first_not_of (delitns, endIdx);
В отличие от первого вызова функции find_first_not_of() поиск начинается от конца предыдущего слова. Если предыдущее слово завершалось в конце строки, то endIdx содержит индекс конца строки. В этом случае поиск начнется от конца строки и вернет string::npos.
Попробуем запустить эту "полезную и нужную" программу для следующих входных данных: pots & pans I saw a reed
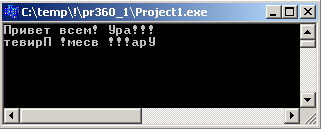
Рис.1. Результат работы приложения
Со следующего шага мы начнем рассматривать описание строковых классов.
