На этом шаге мы рассмотрим пример задания собственных критериев поиска и сортировки.
Следующий пример показывает, как при помощи STL задать собственные критерии поиска и сортировки. В этом примере производится поиск и сравнение строк без учета регистра символов.
//--------------------------------------------------------------------------- #include <vcl.h> #include <string> #include <iostream> #include <algorithm> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } bool nocase_compare (char c1, char c2) { return toupper(c1) == toupper(c2); } int main (int argc, char* argv[]) { string s1("This is a string"); string s2("STRING"); cout << ToRus("1-я строка:\n") << s1 << endl; cout << ToRus("2-я строка:\n") << s2 << endl; // Сравнение строк без учета регистра символов if (s1.size() == s2.size() && // Проверить совпадение размеров equal (s1.begin(),s1.end(), // Первая строка s2.begin(), // Вторая строка nocase_compare)) { // Критерий сравнения cout << ToRus("Строки эквивалентны") << endl; } else { cout << ToRus("Строки не эквивалентны") << endl; } // Поиск без учета регистра символов string::iterator pos; pos = search (s1.begin(),s1.end(), // Строка, в которой ведется поиск s2.begin(),s2.end(), // Искомая подстрока nocase_compare); // Критерий сравнения if (pos == s1.end()) { cout << ToRus("Строка s2 - подстрока строки s1") << endl; } else { cout << '"' << s2 << ToRus("\" - подстрока \"") << s1 << ToRus("\" (начиная с номера ") << pos - s1.begin() << ")" << endl; } getch(); return 0; } //---------------------------------------------------------------------------
Результат выполнения программы выглядит так:
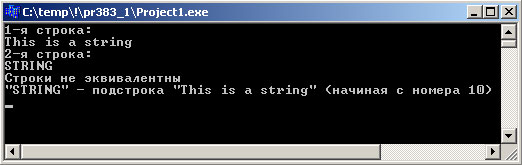
Рис.1. Результат работы приложения
Перед вызовом equal() нужно проследить за тем, чтобы количество элементов во втором интервале было по крайней мере не меньше, чем в первом. Этим объясняется необходимость сравнения размеров; без эгой проверки возможны непредсказуемые последствия.
В последней команде вывода индекс символа вычисляется как разность двух итераторов:
pos - s1.begin()
Такой способ вычисления работает, потому что строковые итераторы являются итераторами произвольного доступа. Преобразование индекса в итератор производится аналогично - достаточно просто прибавить значение индекса.
В приведенном примере определяется вспомогательная функция nocase_compare(), сравнивающая строки без учета регистра символов. Вместо нее также можно было бы воспользоваться комбинацией функциональных адаптеров и заменить вызов nocase_compare следующим выражением:
compose_f_gx_hy(equal_to<int>(),
ptr_fun(toupper),
ptr_fun(toupper))
За дополнительной информацией обращайтесь к шагам 247 и 252.
При хранении строк в множествах или отображениях может потребоваться специальный критерий сортировки строк без учета регистра символов. На 184 шаге приведен пример определения такого критерия.
На следующем шаге мы продолжим изучение этого вопроса.
