На этом шаге мы рассмотрим пример, реализующий чтение из стандартного входного потока с использованием итераторов.
В следующем примере содержимое строки читается из стандартного входного потока данных с использованием конечных итераторов вставки:
//--------------------------------------------------------------------------- #include <vcl.h> #include <string> #include <iostream> #include <algorithm> #include <iterator> #include <locale> #include <conio.h> //необходимо для getch() #pragma hdrstop //--------------------------------------------------------------------------- #pragma argsused using namespace std; std::string ToRus(const std::string &in) { char *buff = new char [in.length()+1]; CharToOem(in.c_str(),buff); std::string out(buff); delete [] buff; return out; } class bothWhiteSpaces { private: const locale& loc; // Локальный контекст public: // Конструктор // - сохранение объекта локального контекста bothWhiteSpaces (const locale& l) : loc(l) { } // Функция проверяет, являются ли оба символа пропусками bool operator() (char elem1, char elem2) { return isspace(elem1,loc) && isspace(elem2,loc); } }; int main (int argc, char* argv[]) { string contents; // Не игнорировать начальные пропуски cin.unsetf (ios::skipws); // Чтение всех символов со сжатием пропусков unique_copy(istream_iterator<char>(cin), // Начало источника istream_iterator<char>(), // Конец источника back_inserter(contents), // Приемник bothWhiteSpaces(cin.getloc())); // Критерий удаления // Обработка содержимого // - в данном случае - запись в стандартный вывод cout << contents; getch(); return 0; } //---------------------------------------------------------------------------
Результат выполнения программы выглядит так:
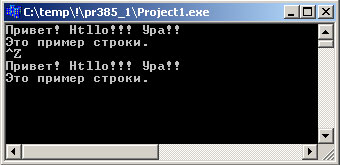
Рис.1. Результат работы приложения
Алгоритм unique_copy() (смотри 294 шаг) читает все символы из входного потока данных cin и вставляет их в строку contents. Объект функции bothWhiteSpaces проверяет, являются ли два последовательных символа пропусками. Для этого он инициализируется локальным контекстом cin и вызывает функцию isspace(), которая проверяет, относится ли символ к категории пропусков (функция isspace() будет рассмотрена позднее). Алгоритм unique_copy() использует критерий bothWhiteSpaces для удаления смежных пропусков. Похожий пример приведен при описании алгоритма unique_copy() на 294 шаге.
На следующем шаге мы рассмотрим интернационализацию.
