На этом шаге мы рассмотрим особенности использования этих потоков.
В примере связывания из предыдущего шага один поток данных используется как для чтения, так и для записи. Обычно файл открывается для чтения/записи при помощи класса fstream:
std::fstream file ("example.txt", std::ios::in | std::ios::out);
Также можно использовать два разных потоковых объекта, по одному для чтения и записи. Соответствующий фрагмент может выглядеть примерно так:
std::ofstream out ("example.txt", ios::in | ios::out);
std::istream in (out.rdbuf());
Объявление out открывает файл. Объявление in использует потоковый буфер out для чтения из него. Обратите внимание: поток данных out должен открываться для чтения и записи. Если открыть его только для записи, чтение из потока данных приведет к непредсказуемым последствиям. Также обратите внимание на то, что in определяется не с типом ifstream, а только с типом istream. Файл уже открыт, и у него имеется соответствующий потоковый буфер. Все, что требуется, - это второй потоковый объект. Как и в примерах из предыдущих шагов, файл закрывается при уничтожении объекта файлового потока данных.
Также можно создать буфер файлового потока данных и назначить его обоим потоковым объектам. Решение выглядит так:
std::filebuf buffer;
std::ostream out(&buffer);
std::istream in (&buffer);
buffer.open("example.txt", std::ios::in | std::ios::out);
Объект filebuf является обычной специализацией класса basic_filebuf<> для типа char. Класс определяет потоковый буфер, используемый файловыми потоками данных.
В следующем примере с помощью цикла в файл выводится четыре строки. После каждой операции вывода все содержимое файла записывается в стандартный выходной поток данных:
// pr501_1.cpp : Defines the entry point for the console application. // #include "stdafx.h" #include <fstream> #include <iostream> #include <conio.h> //необходимо для getch() using namespace std; int _tmain(int argc, _TCHAR* argv[]) { locale::global(locale("rus")); // Создание массива значений с 12 элементами // Открытие файла "example.dat" для чтения и записи filebuf buffer; ostream output(&buffer); istream input(&buffer); buffer.open ("example.dat", ios::in | ios::out | ios::trunc); for (int i=1; i<=4; i++) { // Запись одной строки output << i << "-я строка" << endl; // Вывод всего содержимого файла input.seekg(0); // Позиционирование в начало char c; while (input.get(c)) { cout.put(c); } cout << endl; input.clear(); // Сброс флагов eofbit и failbit } getch(); return 0; }
Замечание. Программа реализована в среде C++ Microsoft Visual Studio 2005 вследствие того, что в Borland C++ Builder 6.0 она работает некорректно (не помещает в файл строки, начиная со второй).
Результат выполнения программы выглядит так:
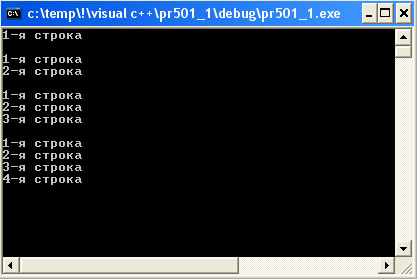
Рис.1. Результат работы приложения
Хотя для чтения и записи используются два разных объекта потоков данных, позиции чтения и записи тесно связаны между собой. Функции seekg() и seekp() вызывают одну и ту же функцию потокового буфера. Следовательно, для того чтобы вывести все содержимое файла, иеобходимо всегда устанавливать позицию чтения в начало файла. После вывода всего содержимого файла позиция чтения/записи снова перемещается в конец файла для присоединения новых строк.
Операции чтения и записи с одним файлом должны разделяться операцией позиционирования (кроме выхода за конец файла во время чтения). Пропуск операции позиционирования приведет к искажению содержимого файла или еще более фатальным ошибкам.
Как упоминалось ранее, вместо последовательной обработки символов все содержимое файла можно вывести одной командой, для чего оператору << передается указатель на потоковый буфер:
std::cout << input.rebuf();
Со следующего шага мы начнем рассматривать потоковые классы для работы со строками.
