На этом шаге мы рассмотрим особенности создания пользовательских буферов ввода.
В сущности, механизм ввода работает по тем же принципам, что и механизм вывода. Однако для ввода также существует возможность отмены последнего чтения. Функции sungetc() (вызывается функцией unget() входного потока данных) и sputbackc() (вызывается функцией putback() входного потока данных) используются для восстановления потокового буфера в состоянии перед последним чтением. Также существует возможность чтения следующего символа без перемещения позиции чтения. Следовательно, при реализации чтения из потокового буфера приходится переопределять больше функций, чем при реализации записи в потоковый буфер.
Для буфера, используемого для записи символов, поддерживаются три указателя, которые могут быть получены функциями eback(), gptr() и egptr() (рисунок 1):
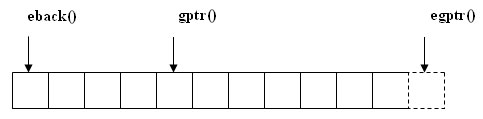
Рис.1. Интерфейс чтения из потоковых буферов
- eback() ("база ввода") - определяет начало буфера ввода или конец области отката;
- gptr() ("указатель ввода") - определяет текущую позицию чтения;
- egptr() ("конец ввода") - определяет конец буфера ввода.
Символы, находящиеся между начальной и конечной позициями, были переданы из внешнего представления в память программы, но еще ожидают обработки.
Одиночные символы читаются функциями sgetc() и sbumpc(). Отличие между этими функциями состоит в том, что функция sbumpc() увеличивает указатель текущей позиции ввода, а функция sgetc() этого не делает. Если буфер будет полностью прочитан (gptr()==egptr()), значит, доступных символов нет и буфер необходимо заполнять заново. Для этого вызывается виртуальная функция underflow(), отвечающая за чтение данных. С другой стороны, функция sbumpc() при отсутствии символов вызывает виртуальную функцию uflow(). По умолчанию uflow() просто вызывает underflow(), а затем увеличивает указатель. По умолчанию версия underflow() в базовом классе basic_streambuf возвращает EOF, то есть признак невозможности дальнейшего чтения с использованием стандартной реализации.
Функция sgetn() предназначена для чтения сразу нескольких символов. Она перепоручает работу виртуальной функции xsgetn(). В реализации по умолчанию xsgetn() просто читает символы, вызывая для каждого из них sbumpc(). По аналогии с функцией xsputn() при записи функция xsgetn() используется для оптимизации чтения нескольких символов.
В отличие от вывода для ввода недостаточно переопределить одну функцию. Вам придется либо выполнить настройку буфера, либо, по крайней мере, реализовать функции underflow() и uflow(). Дело в том, что функция underflow() не перемещается за текущий символ, однако она может быть вызвана из sgetc(). Перемещение к следующему символу приходится выполнять путем манипуляций с буфером или вызовом uflow(). В любом случае функция underflow() должна быть реализована для любого потокового буфера, поддерживающего чтение символов. Если реализованы обе функции, underflow() и uflow(), в настройке буфера нет необходимости.
Настройка буфера чтения осуществляется функцией setg(), получающей следующие три аргумента (именно в таком порядке):
- указатель на начало буфера (eback());
- указатель на текущую позицию чтения (gptr());
- указатель на конец буфера (egptr()).
В отличие от setp() функция setg() вызывается с тремя аргументами. Это необходимо для того, чтобы вы могли зарезервировать память для символов, возвращаемых в поток данных. Таким образом, при настройке буфера ввода желательно, чтобы некоторые символы (по крайней мере один) уже были прочитаны, но еще не сохранены в буфере.
Как упоминалось в предыдущих шагах, символы можно вернуть в буфер чтения с помощью функций sputbackc() и sungetc(). Функция sputbackc() получает возвращаемый символ в аргументе и проверяет, что именно этот символ был прочитан последним. Обе функции уменьшают указатель текущей позиции чтения, если это возможно. Очевидно, это возможно только в том случае, если указатель чтения не находится в начале буфера. При попытке возврата символа в начале буфера вызывается виртуальная функция pbackfail(). Переопределяя эту функцию, можно реализовать механизм восстановления прежней позиции чтения даже в этом случае. В базовом классе basic_streambuf соответствующее поведение не определено. Таким образом, на практике возврат на произвольное количество символов невозможен. Для потоков данных, не использующих буферизацию, следует реализовать функцию pbackfail(), потому что в общем случае предполагается, что хотя бы один символ может быть возвращен в поток.
Когда буфер заполняется заново, возникает другая проблема: если прежние данные не были сохранены в буфере, возврат даже одного символа невозможен. По этой причине реализация underflow() часто перемещает несколько последних символов (например, четыре) в начало буфера и присоединяет читаемые символы после ннх. Это позволяет вернуть хотя бы несколько символов перед тем, как будет вызвана функция pbackfail().
На следующем шаге мы рассмотрим пример использования потоковых буферов ввода.
