На этом шаге мы рассмотрим реализацию этого алгоритма.
Рассмотрим теперь алгоритм обхода графа, известный под названием обход в ширину (поиск в ширину). При обходе графа в глубину, чем позднее будет посещена вершина, тем раньше она будет использована. Это прямое следствие того факта, что просмотренные, но ещё не использованные вершины накапливаются в стеке.
Обход графа в ширину основывается на замене стека очередью. После такой модификации, чем раньше посещается вершина (помещается в очередь), тем раньше она используется (удаляется из очереди). Использование вершины происходит с помощью просмотра сразу всех ещё непросмотренных вершин, смежных этой вершине. Таким образом, "поиск ведётся как бы во всех возможных направлениях одновременно" [1, с.131].
Механизм работы алгоритма обхода в ширину становится ясным из рассмотрения бинарного дерева поиска для следующего графа (порядок обхода графа задан цифрами рядом с кружками):
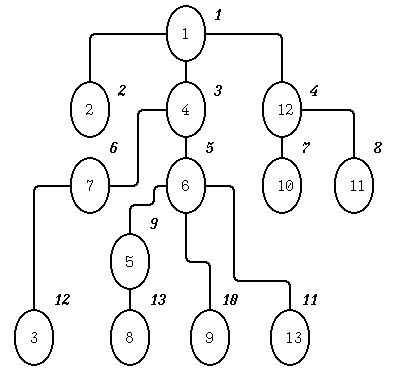
Рис.1. Пример дерева для обхода в ширину
Приведем программу, реализующую обход в ширину.
Раскрыть/скрыть текст примера.
Библиотека для работы с графами, представленными ассоциативными списками смежности.
Раскрыть/скрыть текст библиотеки.
Все файлы можно взять здесь.При поиске в ширину ближайшие соседи последней просмотренной вершины добавляются в конец списка queue операцией:
queue ++ (neighbour (head queue) graph),
(head queue): visited,
(1)Крюков А.П., Радионов А.Я., Таранов А.Ю., Шаблыгин Е.М. Программирование на языке R-Лисп. - М.: Радио и связь, 1991. - 192 с.
На следующем шаге мы рассмотрим нерекурсивный алгоритм поиска в ширину на графе.
