На этом шаге мы рассмотрим интерфейс Collector и класс Collectors�
Ранее мы рассказывали вам про функцию collect. Она принимает объект типа Collector, с помощью которого можно производить предварительные действия над элементами потока. Это может быть операция фильтрации, группировки и так далее. Collector - это интерфейс со следующими функциями:
- Supplier supplier() - supplier возвращает функцию, которая создает внутренний контейнер для работы с потом значений. Вся работа со значениями будет проходить через этот контейнер.�
- BiConsumer
- BinaryOperator combiner() - данная функция возвращает бинарный оператор, который получает два контейнера и производит их объединение.�
- Function
- Set
characteristics() - данная функция возвращает множества характеристик что из себя представляет данный Collector. Characteristics - это перечисление. Возможные значения следующие:�- CONCURRENT - при выставлении данного значения в качестве характеристики коллектора означает, что данный коллектор можно использовать при параллельных потоках.�
- UNORDERED - при выставлении данного значения в качестве характеристики коллектора означает, что данный коллектор не несет на себя обязательств за сохранения порядка следования элементов при добавлении этих значений во внутренний контейнер.�
- IDENTITY_FINISH - при выставлении данного значения в качестве характеристики коллектора означает, что функция finisher является функцией Identity (ничего не выполняющей) и значит может быть отменена.�
Чтобы написать свой Collector нужно реализовать данный интерфейс, реализовав перечисленные выше функции. В библиотеке Java содержатся уже готовые коллекторы для наиболее часто �выполняемых задач. Все они расположены в классе Collectors, который содержит только статические функции (далее мы будем опускать Collectors полагая что был совершен статический импорт соответствующих функций). Рассмотрим их подробнее.�
Самое простое что можно сделать с потоком это преобразовать его в какую-нибудь коллекцию. Это можно сделать с помощью одного из следующих функций:�
- toList()�
- toMap()�
- toSet()�
- toCollection()�
Особое внимание уделим функции toCollection(). Поток сам пытается понять какая лучше реализация интерфейса коллекции подходит для функций toList, toMap или toSet. Но если программист хочет чтобы использовался, например, TreeSet для преобразования в Set, то нужно воспользоваться функцией toCollection следующим образом:�
Set<Integer> set = list.stream().collect(toCollection(TreeSet::new));�
С помощью коллекторов можно находить максимальное, минимальное и среднее значение из потока. Для этого есть следующие функции:
�- maxBy(Comparator<? super T> comparator)�
- minBy(Comparator<? super T> comparator)�
- averagingInt(ToIntFunction<? super T> mapper)�
- averagingLong(ToLongFunction<? super T> mapper)�
- averagingDouble(ToDoubleFunction<? super T> mapper)�
Отметим, что перед тем как считать среднее значение все элементы преобразуются к примитивному типу (указан в имени функции) с помощью функции mapper.
�Также элементы потока можно группировать и соединять. Для этого есть следующие функции:�
- partitioningBy(Predicate<? super T> predicate) - данная функция разбивает набор элементов потока на два подмножества - те которые удовлетворяют заданному предикату, и те которые ему не удовлетворяют. Результатом будет объект типа Map. Ключами будут два значения - true и false. Для ключа true будут соответствовать все элементы, удовлетворяющие предикату, а для ключа false - не удовлетворяющие. Значения по ключу будут храниться в списке.�
- groupingBy(Function<? super T, ? extends K> classifier) - данная функция группирует элементы по какому-то признаку. Различие этой функции от partitioningBy в том, что полученных групп может быть сколько угодно. Ключем группы будет, то что возвращает classifier, а значением по ключу будет список. Также заметим, что пустых групп нет.�
- joining(CharSequence delimiter) - данная функция соединяет значения потока в строку с заданным разделителем.�
- joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix) - отличие этой функции от предыдущей в том, что к полученной строке в начале и в конце добавляется prefix и suffix соответственно.�
Рассмотренные выше функции сами по себе носят мало практического характера. Вся суть этих функций в том, что из них можно строить композиции вызовов, что позволяет строить простые и в то же время мощные выражения. Например, пусть у нас стоит задача разбить список на группы и подсчитать сколько элементов получилось в группах. Это можно сделать с помощью композиций коллекторов и коллектора counting:�
Map<Boolean, Long> mn = list.stream()
.collect(partitioningBy(x -> x > 6, counting()));Кроме подсчета значений в группе можно также преобразовывать значения в группах. Это также можно сделать с помощью композиций коллекторов. Для этого есть коллектор mapping. Например, пусть у нас есть задача написать функцию, которая принимает список, правило разбиения элементов списка, а также функцию-маппер для изменения элементов в группе. Эта функция должна разбить элементы с помощью первой функции, а потом применить маппер к каждому элементу каждой группы. Такая функция может выглядеть следующим образом:
Map<Integer, List<Integer>> partition(List<Integer> list,
Function<Integer, Integer> function,
Function<Integer, Integer> mapper) {
return list.stream()
.collect(groupingBy(function, mapping(mapper, toList())));
}Сначала будет происходить группировка элементов списка, потом будет применяться функция mapper к каждому элементу каждой непустой группы. В конце полученные новые значения в группах будут преобразованы к списку.�
Приведем ниже несколько примеров использования функции collect и коллекторов.
1 пример. Написать коллектор joining.�
import java.util.Arrays; import java.util.EnumSet; import java.util.List; import java.util.Set; import java.util.function.BiConsumer; import java.util.function.BinaryOperator; import java.util.function.Function; import java.util.function.Supplier; import java.util.stream.Collector; public class Main { public static void main(String[] args) { List<String> list = Arrays.asList("1", "2", "3", "4", "5"); /* Производим конкатенацию значений с помощью функции reduce */ String joinReduceTest = list.stream() .reduce(new StringCombiner(", ", "[", "]"), StringCombiner::add, StringCombiner::merge ).toString(); System.out.println("С помощью reduce: " + joinReduceTest); /* Производим конкатенацию значений с помощью функции collect */ String joinCollectTest = list.stream() .collect(new StringCollector(", ", "[", "]")); System.out.println("С помощью collect: " + joinCollectTest); } } /** * Коллектор конкатеницаии строк */ class StringCollector implements Collector<String, StringCombiner, String> { private String delim; private String prefix; private String suffix; public StringCollector(String delim, String prefix, String suffix) { this.delim = delim; this.prefix = prefix; this.suffix = suffix; } @Override public Supplier<StringCombiner> supplier() { return () -> new StringCombiner(delim, prefix, suffix); } @Override public BiConsumer<StringCombiner, String> accumulator() { return StringCombiner::add; } @Override public BinaryOperator<StringCombiner> combiner() { return StringCombiner::merge; } @Override public Function<StringCombiner, String> finisher() { return StringCombiner::toString; } @Override public Set<Characteristics> characteristics() { return EnumSet.of(Characteristics.UNORDERED); } } /** * Вспомогательный класс-контейнер */ class StringCombiner { private String delim; private String prefix; private String suffix; private boolean areAtStart = true; private StringBuilder sb = new StringBuilder(); public StringCombiner(String delim, String prefix, String suffix) { this.delim = delim; this.prefix = prefix; this.suffix = suffix; } /** * Функция для добавления елемента для конкатенации * * @param elem Елемента для добавления * @return текущий объект класса */ public StringCombiner add(String elem) { if (areAtStart) { sb.append(prefix); areAtStart = false; } else { sb.append(delim); } sb.append(elem); return this; } /** * Функция объединения контейнеров * * @param other Контейнер для объединения с текущим контейнером * @return текущий объект класса */ public StringCombiner merge(StringCombiner other) { sb.append(other.sb); return this; } /** * Функция для добавления форматированого вывода контейнера * * @return Строка */ @Override public String toString() { sb.append(suffix); return sb.toString(); } }
Проект можно взять здесь
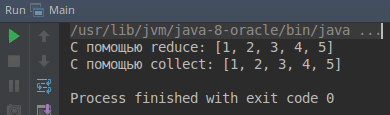
Рис. 1. Вывод программы
2 пример. Напишем программу, читающую из файла текст (путь к файлу передается через командную строку), подсчитывающую в нем частоту появления слов, и в конце выводящую 10 наиболее часто встречающихся слов. Перед фильтрацией отсортировать слова по алфавиту при одинаковых значениях частот, а также привести все слова к нижнему регистру. Будем считать, что файл состоит только из букв, цифр и пробелов. Словом будем считать любую последовательность символов, внутри которой нет пробелов, а ограничена пробелами за исключением, быть может, первого и последнего слова в строке.�
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; import java.util.Arrays; import java.util.Comparator; import java.util.List; import java.util.Map; import java.util.function.Function; import java.util.stream.Collectors; public class Main { private static boolean checkArgs(String[] args) { if (args.length == 0) { System.out.println("Передайте путь к существующему файлу"); return false; } Path file = Paths.get(args[0]); if (Files.notExists(file) || Files.isDirectory(file)) { System.out.println("Передайте путь к существующему файлу"); return false; } return true; } private static Comparator<Map.Entry<String, Long>> myComparator() { // вот это нужно чтобы java поняла какие типы у getValue и getKey // |___________________________ ______________________________| // \/ return Comparator.<Map.Entry<String, Long>>comparingLong (Map.Entry::getValue) // сравнивает сначала по значению количества // перевернем в обратном порядке, чтобы шли по убыванию значения количества .reversed() // и в конце пересортируем при равных количествах по алфавиту слова .thenComparing(Map.Entry::getKey); } public static void main(String[] args) throws IOException { if (checkArgs(args)) { Path file = Paths.get(args[0]); List<String> words = Files.lines(file) // получаем массив слов в строке .map(line -> line.split("\\s+")) // меняем массивы слов на один поток слов .flatMap(Arrays::stream) // убираем пустые строки из потока .filter(word -> !word.isEmpty()) // переводим каждое слово в нижний регистр .map(String::toLowerCase) // групируем слова по их имени и считаем с помощью композиции коллекторов //сколько раз слово встретилось .collect(Collectors.groupingBy(Function.identity(), Collectors.counting())) // так как на этот момент уже будет Map, то получаем поток пар: слово - количество .entrySet().stream() // сортируем пары по нашему правилу .sorted(myComparator()) // берем первые 10 часто встречаемых слов .limit(10) // из потока пар возьмем только ключ (слово) .map(Map.Entry::getKey) // и преобразуем поток к списку .collect(Collectors.toList()); // Выводим ответ к задаче System.out.println("Ответ на условие задачи: "); if (words.size() == 0) { System.out.println("Файл не содержит слов"); return; } words.forEach(System.out::println); } } }
Проект можно взять здесь
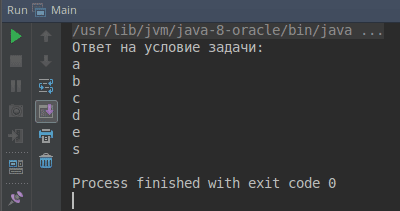
Рис. 2. Вывод программы
3 пример. Пусть у нас есть список чисел. Нужно сгруппировать числа по их остаткам при делении на заданное число. Число нужно считывать с клавиатуры.�
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.util.Comparator; import java.util.List; import java.util.Map; import java.util.Random; import java.util.stream.Stream; import static java.util.stream.Collectors.groupingBy; import static java.util.stream.Collectors.toList; public class Main { public static void main(String[] args) throws IOException { // Читаем значение для расчета остатка числа BufferedReader bufferedReader = new BufferedReader( new InputStreamReader(System.in)); int n = Integer.parseInt(bufferedReader.readLine()); // Формируем список произвольных чисел Random rnd = new Random(); List<Integer> list = Stream.generate(() -> rnd.nextInt(200)) .limit(100) .collect(toList()); // Группируем числа по остаткам Map<Integer, List<Integer>> groups = list.stream() .collect(groupingBy(x -> x % n)); groups.entrySet() .stream() // сортируем по значению остатка .sorted(Comparator.comparingInt(Map.Entry::getKey)) .forEach(e -> { // Выводим каждую группу System.out.print(e.getKey() + ":"); List<Integer> group = e.getValue(); group.forEach(v -> System.out.print(" " + v)); System.out.println(); }); } }
Проект можно взять здесь
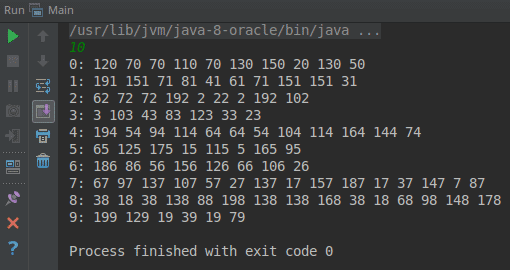
Рис. 3. Вывод программы
На следующем шаге мы узнаем что такое Maven
