На этом шаге мы начнем изучать простейшие типы данных, в частности, поговорим об
атомах.
При рассмотрении типов данных сначала задаются некоторые исходные типы, которые называются простейшими (примитивными, базовыми, элементарными) типами данных.
Взгляните на схему, иллюстрирующую классификацию простейших типов данных в языке LISP:
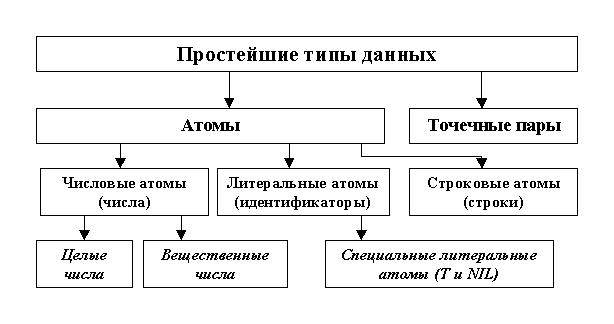
Рис.1. Классификация простейших типов данных
Приступим к рассказу о содержимом каждого блока схемы. Сразу же отметим, что в диалектах muLISP81 и muLISP83 отсутствуют атомы-вещественные числа.
Поясним используемые здесь обозначения. Знак "::=" обозначает "определяется как", а "|" - "или". В угловых скобках стоят названия определяемых или уже определенных объектов.
Атом является основным простейшим типом данных. В современном мире, когда мы изучаем составные части атома (в физике), такие, как электроны, протоны, нейтроны, легко забыть, что первоначальное значение слова "атом" - это "тот, который не может быть дальше разделен", но именно в этом смысле "атом" употребляется в языке LISP. (Греческие корни "а" - не, "том" - часть; том также означает часть большой книги).
Атомы могут быть числовыми, литеральными и строковыми.
В нотации Бэкуса-Наура это выглядит так:
<Атом> ::= <Числовой_атом> | <Литеральный_атом> |
<Строковый_атом> | T | NIL
a) Литеральный атом (идентификатор) - это последовательность букв и цифр, начинающаяся с буквы.
Отметим важную особенность интерпретаторов muLISP81 и muLISP83: большие и маленькие буквы считаются различными, поэтому, например, атомы NAME, Name и name не являются идентичными. Примеры литеральных атомов: LISP, APRPARAPR.
К литеральным атомам относятся специальные литеральные атомы:
- NIL - логическое значение "ложь" и одновременно обозначение пустого списка,
- T - логическое значение "истина".
В нотации Бэкуса-Наура это выглядит так:
<Литеральный_атом> ::= <Буква> |
<Буква> <Последовательность>
<Последовательность> ::= <Правильный_символ> |
<Правильный_символ> <Последовательность>
<Правильный_символ> ::= <Буква> | <Цифра>
<Цифра> ::= 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
<Буква> ::= A | B | C | D | E | F | G | H | I | G | K |
L | M | N | O | P | Q | R | S | T | U | V |
W | X | Y | Z |
a | b | c | d | e | f | g | h | i | j | k |
l | m | n | o | p | q | r | s | t | u | v |
w | x | y | z |
b) Разъясним смысл термина числовой атом с помощью нотации Бэкуса-Наура
для версий muLISP81 и muLISP83 (в которых отсутствуют вещественные числовые атомы):
<Числовой_атом> ::= <Целое_без_знака> |
+<Целое_без_знака> |
-<Целое_без_знака>
<Целое_без_знака> ::= <Цифра> | <Цифра> <Целое_без_знака>
<Цифра> ::= 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0
Приведем примеры числовых атомов:
0
23423
+2345
-345
c) Строковый атом - последовательность символов, начинающаяся и заканчивающаяся кавычками ("). Строковые атомы (строки) отличаются от литеральных атомов (идентификаторов) тем, что могут содержать в качестве элементов разделители атомов: пробелы, точки, запятые и т.д., но не должны содержать внутри себя символа "(кавычка).
В нотации Бэкуса-Наура это выглядит так:
<Строковый_атом> ::= "<Последовательность любых символов,
не содержащая символа кавычка>"
Максимальное количество символов в строковом атоме в диалекте muLISP81 - 120.
На следующем шаге будет продолжено рассмотрение простейших типов данных.
