На этом шаге мы рассмотрим что из себя представлют TRIE-структуры и какова их область применения.
TRIE-структуры (словари, боры) - класс структур данных, в которых значение ключа, по которому производится поиск, рассматривается как упорядоченная последовательность (строка) знаков из некоторого алфавита, содержащего V символов [1, с.134-142; 2, с.572-600]. Само название "TRIE" происходит от слова "reTRIEval" (поиск, выБОРка).
Рассмотрим, например, имеющиеся во многих словарях "побуквенные высечки"; по первой букве данного слова мы можем немедленно нащупать страницы, содержащие все слова, начинающиеся с этой буквы.
TRIE-структура представляет собой сильно ветвящееся дерево, в котором из каждой вершины выходят в точности V ветвей, по одной для каждого возможного символа в позиции строки ключа. Если ключ состоит из K символов (байтов), то поиск соответствующей записи данных с целью выявления ее наличия или отсутствия в TRIE-структуре требует просмотра K вершин бора. Записям данных в этой структуре соответствуют листья.
Достоинствами TRIE-структуры являются:
- возможность быстрого произвольного доступа к данным ценой дополнительных затрат памяти;
- если поиск записи в боре неудачен, все же будет найден элемент, лучше всего совпадающий с аргументом поиска. Это свойство полезно для некоторых приложений.
i-я позиция в ключе может иметь V возможных значений, каждому значению соответствует определенная позиция в определенной вершине на i-м уровне структуры дерева. Такой способ адресации представляет разновидность прямой адресации, при которой значение символа неявно определяет позицию в вершине, где может быть найдено значение соответствующего указателя. Значение указателя определяет местоположение вершины на следующем уровне, в котором представлены возможные значения (i+1)-го символа в ключе. Следовательно, для ключа из K знаков выполняется просмотр только K вершин, по одной на каждом из K уровней дерева.
Пpимеp 1. Пусть в словаpь поступают последовательно следующие слова: Мас, Мал, Мяч.
Расположение инфоpмации в словаpе можно изобpазить так:
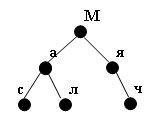
Рис.1. Расположение информации в словаре
Расположение инфоpмации в лисповском списке:
(М (а (с л) я (ч)))
Пpимеp 2. Пусть в TRIE-структуру поступают последовательно следующие слова: Hаташа, Hаташенька, Hаталыч, Hатуля, Hатуся, Татоша, Татошка, Туська.
Расположение инфоpмации в словаpе можно изобpазить так:

Рис.2. Расположение информации в словаре
Расположение инфоpмации в лисповском списке:
(H (а (т (а (ш (а е (н (ь (к (а))))) л (ы (ч))) у (л (я) с (я)))))
Т (а (т (о (ш (а к (а))))) у (с (ь (к (а))))))
Вследствие того, что ключи могут быть переменной длины, TRIE-структура, как правило, не сбалансирована; это означает следующее: если Kj обозначает длину ключа j, то для разных j листья в TRIE-структуре располагаются на разных Kj уровнях.
Разумеется, в каждом листе TRIE-структуры необходимо предусмотреть флажок (со значениями, например, 0 и 1), который предназначается для идентификации последней вершины на пути, соответствующем значению ключа.
Изобразим схематически TRIE-структуру, содержащую ключи AAA, AAC, AC, BAB, BBCA, CA, CB, составленные из символов алфавита {A,B,C}:
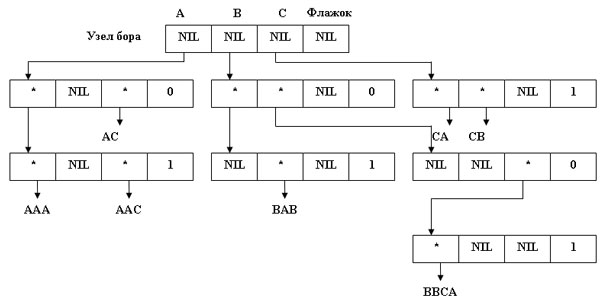
Рис.3. Изображение TRIE-структуры
Хотя в каждой вершине предусматривается место для V возможных значений, многие из комбинаций значений в качестве ключевых идентификаторов не используются. Вследствие этого возможны большие потери памяти. Ясно, что если конкретная позиция в вершине не используется, ее указатели устанавливаются в NIL, отражая тот факт, что поддерево, соответствующее данному префиксу пусто.
Пpимеp 3. Реализация TRIE-деpева на языке LISP.
(DEFUN MAIN (LAMBDA NIL ; Построение словаpя и поиск в нем ; (PRIN1 "Input first letter... ") (PRINT (SETQ WORD1 (LIST (READ)))) (LOOP (PRIN1 "Input keyword: ") (SETQ WORD2 (READ)) ( (EQ WORD2 END) 'BYE-BYE ) ; Символ & отмечает конец слова WORD2 ; (SETQ WORD2 (APPEND (UNPACK WORD2) (LIST '&))) (SETQ WORD1 (INSERT WORD2 WORD1)) (PRINT WORD1) ) (LOOP (PRIN1 "Input keyword for search: ") (SETQ WORD2 (READ)) ( (EQ WORD2 END) 'BYE-BYE ) (SETQ WORD2 (APPEND (UNPACK WORD2) (LIST '&))) (PRIN1 "Result: ") (PRINT (SEARCH WORD2 WORD1)) ) )) ; ----------------------------- ; (DEFUN SEARCH (LAMBDA (WORD TRIE) ; Поиск слова WORD в словаре TRIE ; (COND ( (NULL TRIE) NIL ) ( (EQUAL WORD TRIE) T ) ( (EQ (CAR WORD) '&) "Subword" ) ( (MEMBER (CAR WORD) TRIE) (SEARCH (CDR WORD) (CADR (MEMBER (CAR WORD) TRIE))) ) ( T NIL ) ) )) ; ---------------------------- ; (DEFUN INSERT (LAMBDA (WORD LST) ; Помещение слова WORD в словаpь LST ; (COND ( (NULL LST) (TREE WORD) ) ( (NULL WORD) LST ) ( (NOT (MEMBER (CAR WORD) LST)) (APPEND LST (TREE WORD)) ) ; -------------------------------- ; ( (AND (EQ (CAR LST) (CAR WORD)) (ATOM (CADR LST)) (NULL (CDR WORD)) ) (CONS (CAR LST) (CDR LST)) ) ; ---------------------------- ; ( (AND (EQ (CAR LST) (CAR WORD)) (ATOM (CADR LST)) ) (CONS (CAR LST) (APPEND (LIST (TREE (CDR WORD))) (CDR LST))) ) ; ---------------------------- ; ( (AND (EQ (CAR LST) (CAR WORD)) (NOT (ATOM (CADR LST)))) (CONS (CAR LST) (APPEND (LIST (INSERT (CDR WORD) (CADR LST))) (CDDR LST))) ) ; ----------------------------- ; ( (NOT (EQ (CAR LST) (CAR WORD))) (CONS (CAR LST) (INSERT WORD (CDR LST))) ) ) )) ; --------------------- ; (DEFUN TREE (LAMBDA (LST) ; Постpоение из списка (A B C ...) списка ; ; со следующей структурой: (A (B (C (...)))) ; (COND ( (NULL (CDR LST)) (LIST (CAR LST)) ) ( T (LIST (CAR LST) (TREE (CDR LST))) ) ) )) ; ----------------------- ; (DEFUN APPEND (LAMBDA (X Y) ; Функция APPEND возвpащает список, состоящий из ; ; элементов списка LST1, добавленных к списку LST2 ; (COND ( (NULL X) Y ) ( T (CONS (CAR X) (APPEND (CDR X) Y)) ) ) ))
Тестовый пример:
$ Input first letter... A (A) $ Input keyword: ASD (A (S (D (&)))) $ Input keyword: ASE (A (S (D (&) E (&)))) $ Input keyword: AKE $ (A (S (D (&) E (&)) K (E (&)))) $ Input keyword: AKK $ (A (S (D (&) E (&)) K (E (&) K (&)))) $ Input keyword: END $ Input keyword for search: ASE $ Result: T $ Input keyword for search: AS $ Result: Subword $ Input keyword for search: E $ Result: NIL $ Input keyword for search: END
TRIE-деpевья пpедставляют собой стpуктуpы данных, пpименение котоpых не уступает по эффективности методам хешиpования.
Замечания.
- В литературе предложено множество гибридных древовидных структур, сочетающих в себе лучшие качества метода хэширования, бинарных деревьев, B-деревьев и многочисленных их вариантов. Среди них в монографии [1, с.134] названы: хэш-деревья, расширенный метод хэширования, виртуальное B-дерево.
- Используя TRIE-деpевья, можно стpоить позиционные деpевья [3], часто используемые пpи поиске подстpоки в стpоке. Более сильный pезультат о pаспознавании вхождения одной цепочки в дpугую был получен Ю.В.Матиясевичем в 1969 г. ( см. его статью "О pаспознавании в pеальное вpемя отношения вхождения". Зап.научн.семинаpов ЛОМИ, т.20, 104-114).
(1)Тиори Т., Фрай Дж. Проектирование структур баз данных: В 2-х кн. Кн.2 - М.: Мир, 1985. - 320 с.
(2)Кнут Д. Искусство программирования для ЭВМ. Т.3: Сортировка и поиск. - M.: Мир, 1978. - 844 с.
(3)Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. - М.: Мир, 1979. - 536 с.
Со следующего шага мы начнем рассматривать простейшие алгоритмы на графах.
