На этом шаге мы рассмотрим использование линейной модели для прогнозирования.
Для регрессии общая прогнозная формула линейной модели выглядит следующим образом:
у = w[0] * x[0] + w[1] * x[1] +... + w[p] * x[p] + b
Здесь х[0] по х[р] обозначают признаки (в данном примере число характеристик равно р+1) для отдельной точки данных, w и b - параметры модели, оцениваемые в ходе обучения, и у - прогноз, выдаваемый моделью. Для набора данных с одним признаком эта формула имеет вид:
у = w[0] * x[0] + b
Возможно из школьного курса математики вы вспомните, что эта формула - уравнение прямой. Здесь х[0] является наклоном, а b - сдвигом по оси y.
 Более точно наклон представляет собой тангенс угла наклона линии регрессии и называется регрессионным коэффициентом, а сдвиг определяет точку пересечения линии регрессии с осью ординат и
называется свободным членом или константой.
Более точно наклон представляет собой тангенс угла наклона линии регрессии и называется регрессионным коэффициентом, а сдвиг определяет точку пересечения линии регрессии с осью ординат и
называется свободным членом или константой.
Когда используется несколько признаков, регрессионное уравнение содержит параметры наклона для каждого признака. Как вариант, прогнозируемый ответ можно представить в виде взвешенной суммы входных признаков, где веса (которые могут быть отрицательными) задаются элементами w.
Попробуем вычислить параметры w[0] и b для нашего одномерного набора данных wave с помощью следующей строки программного кода (см. рисунок 1):
[In 2]: import mglearn mglearn.plots.plot_linear_regression_wave() w[0]: 0.393906 b: -0.031804
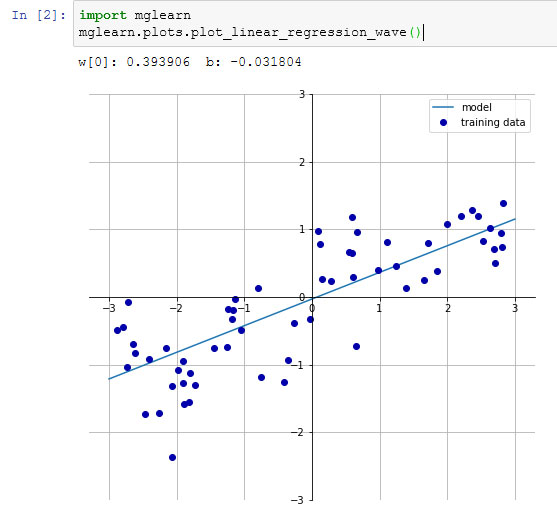
Рис.1. Прогнозы линейной модели для набора данных wave
Мы добавили координатный крест на график, чтобы прямую было проще интерпретировать. Взглянув на значение w[0], мы видим, что наклон должен быть около 0.4 и это визуально подтверждается на графике. Константа (место пересечения линии прогнозов с осью ординат) чуть меньше нуля, что также подтверждается графиком.
Линейные модели для регрессии можно охарактеризовать как регрессионные модели, в которых прогнозом является прямая линия для одного признака, плоскость, когда используем два признака, или гиперплоскость для большего количества измерений (то есть, когда используем много признаков).
Если прогнозы, полученные с помощью прямой линии, сравнить с прогнозами KNeighborsRegressor (рисунок 2 из 34 шага), использование линии регрессии для получения прогнозов кажется очень строгим.
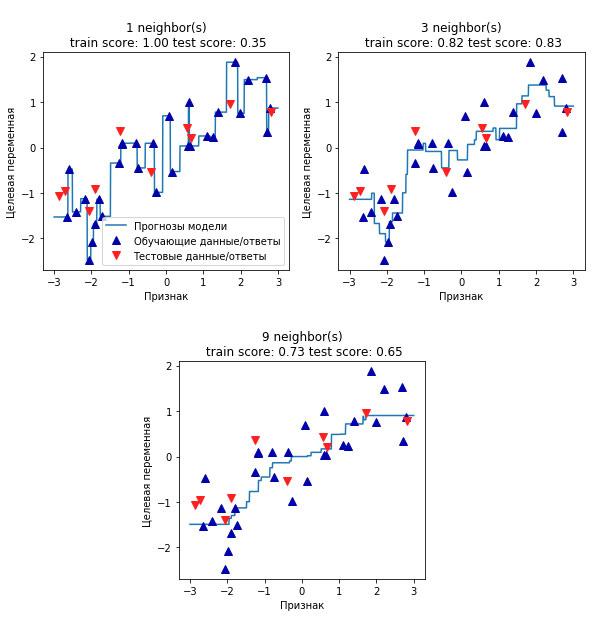
Рис.2. Рисунок 2 из 34 шага с прогнозами KNeighborsRegressor
Похоже, что все мелкие детали данных не учитываются. В некотором смысле это верно. Мы видвигаем сильное (и в некоторой степени нереальное) предположение, что наша целевая переменная у является линейной комбинацией признаков. Однако анализ одномерных данных дает несколько искаженную картину. Для наборов данных с большим количеством признаков линейные модели могут быть очень полезны. В частности, если у вас количество признаков превышает количество точек данных для обучения, любую целевую переменную у можно прекрасно смоделировать (на обучающей выборке) в виде линейной функции.
Существует различные виды линейных моделей для регрессии. Различие между этими моделями заключается в способе оценивания параметров модели w и b по обучающим данным и контроле сложности модели. Теперь мы рассмотрим наиболее популярные линейные модели для регрессии.
На следующем шаге мы рассмотрим линейную регрессию.
