На этом шаге мы рассмотрим градиентный бустинг.
Градиентный бустинг деревьев регрессии - еще один ансамблевый метод, который объединяет в себе множество деревьев для создания более мощной модели. Несмотря на слово "регрессия" в названии, эти модели можно использовать для регрессии и классификации. В отличие от случайного леса, градиентный бустинг строит последовательность деревьев, в которой каждое дерево пытается исправить ошибки предыдущего. По умолчанию в градиентном бустинге деревьев регрессии отсутствует случайность, вместо этого используется строгая предварительная обрезка. В градиентном бустинге деревьев часто используются деревья небольшой глубины, от одного до пяти уровней, что делает модель меньше с точки зрения памяти и ускоряет вычисление прогнозов.
Основная идея градиентного бустинга заключается в объединении множества простых моделей (в данном контексте известных под названием слабые ученики или weak learners), деревьев небольшой глубины. Каждое дерево может дать хорошие прогнозы только для части данных и таким образом для итеративного улучшения качества добавляется все большее количество деревьев.
Градиентный бустинг деревьев часто занимает первые строчки в соревнованиях по машинному обучению, а также широко используется в коммерческих сферах. В отличие от случайного леса он, как правило, немного более чувствителен к настройке параметров, однако при правильно заданных параметрах может дать более высокое значение правильности.
Помимо предварительной обрезки и числа деревьев в ансамбле, еще один важный параметр градиентного бустинга - это learning_rate, который контролирует, насколько сильно каждое дерево будет пытаться исправить ошибки предыдущих деревьев. Более высокая скорость обучения означает, что каждое дерево может внести более сильные корректировки и это позволяет получить более сложную модель. Добавление большего количества деревьев в ансамбль, осуществляемое за счет увеличения значения n_estimators, также увеличивает сложность модели, поскольку модель имеет больше шансов исправить ошибки на обучающем наборе.
Ниже приведен пример использования GradientBoostingClassifier на наборе данных Breast Cancer. По умолчанию используются 100 деревьев c максимальной глубиной 3 и скорости обучения 0.1:
[In 6]: from sklearn.ensemble import GradientBoostingClassifier X_train, X_test, y_train, y_test = train_test_split( cancer.data, cancer.target, random_state=0) gbrt = GradientBoostingClassifier(random_state=0) gbrt.fit(X_train, y_train) print("Правильность на обучающем наборе: {:.3f}". format(gbrt.score(X_train, y_train))) print("Правильность на тестовом наборе: {:.3f}". format(gbrt.score(X_test, y_test))) Правильность на обучающем наборе: 1.000 Правильность на тестовом наборе: 0.965
Поскольку правильность на обучающем наборе составляет 100%, мы, вероятно, столкнулись с переобучением. Для уменьшения переобучения мы можем либо применить более сильную предварительную обрезку, ограничив максимальную глубину, либо снизить скорость обучения:
[In 7]: gbrt = GradientBoostingClassifier(random_state=0, max_depth=1) gbrt.fit(X_train, y_train) print("Правильность на обучающем наборе: {:.3f}". format(gbrt.score(X_train, y_train))) print("Правильность на тестовом наборе: {:.3f}". format(gbrt.score(X_test, y_test))) Правильность на обучающем наборе: 0.991 Правильность на тестовом наборе: 0.972
[In 8]: gbrt = GradientBoostingClassifier(random_state=0, learning_rate=0.01) gbrt.fit(X_train, y_train) print("Правильность на обучающем наборе: {:.3f}". format(gbrt.score(X_train, y_train))) print("Правильность на тестовом наборе: {:.3f}". format(gbrt.score(X_test, y_test))) Правильность на обучающем наборе: 0.988 Правильность на тестовом наборе: 0.965
Как и ожидалось, эти методы, направленные на уменьшение сложности модели, снижают правильность на обучающем наборе. В данном случае снижение максимальной глубины деревьев значительно улучшило модель, тогда как скорость обучения лишь незначительно повысило обобщающую способность.
И вновь, как и в случае с остальными моделями на основе деревьев, мы можем визуализировать важности признаков, чтобы получить более глубокое представление о нашей модели (рисунок 1). Поскольку мы использовали 100 деревьев, вряд ли целесообразно проверять все деревья, даже если все они имеют глубину 1:
[In 9]: gbrt = GradientBoostingClassifier(random_state=0, max_depth=1) gbrt.fit(X_train, y_train) def plot_feature_importances_cancer(model): n_features = cancer.data.shape[1] plt.barh(range(n_features), model.feature_importances_, align='center') plt.yticks(np.arange(n_features), cancer.feature_names) plt.xlabel("Важность признака") plt.ylabel("Признак") plot_feature_importances_cancer(gbrt)
Архив блокнота со всеми вычислениями, выполненными на 57 и 59 шагах, можно взять здесь.
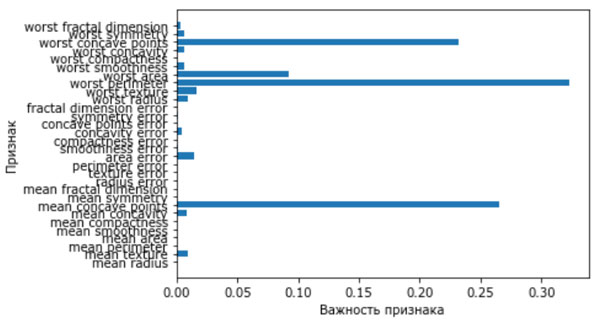
Рис.1. Важности признаков, вычисленные градиентным бустингом деревьев для набора данных Breast Cancer
На рисунке видно, что важности признаков, вычисленные градиентным бустингом деревьев, в какой-то степени схожи с важностями признаков, полученными с помощью случайного леса, хотя градиентный бустинг полностью проигнорировал некоторые признаки.
Поскольку и градиентный бустинг и случайный лес хорошо работают на одних и тех же данных, общераспространенный подход заключается в том, чтобы сначала попытаться построить случайный лес, который дает вполне устойчивые результаты. Если случайный лес дает хорошее качество модели, однако время, отводимое на прогнозирование, на вес золота или важно выжать из модели максимальное значение правильности, выбор в пользу градиентного бустинга часто помогает решить эти задачи.
Если вы хотите применить градиентный бустинг для решения крупномасштабной задачи, возможно стоит обратиться к пакету xgboost и его Python-интерфейсу, который на многих наборах данных работает быстрее (а иногда и проще настраивается), чем реализация градиентного бустинга в scikit-learn.
На следующем шаге мы рассмотрим преимущества, недостатки и параметры.
