На этом шаге мы рассмотрим особенности использования PCA при сравнении изображений.
И вот именно здесь применяется PCA. Вычисление расстояний в исходном пиксельном пространстве - довольно неудачный способ измерить сходство между лицами. Используя пиксельное представление для сопоставления двух изображений, мы сравниваем значение каждого отдельного пикселя по шкале градаций серого со значением пикселя в соответствующем положении на другом изображении. Это представление довольно сильно отличается от интерпретации изображений лиц людьми и крайне трудно выделить характеристики лица с использованием этого исходного представления. Например, использование пиксельных расстояний означает, что смещение лица на один пиксель вправо соответствует резкому изменению, дающему совершенно другое представление данных. Мы рассчитываем на то, что использование расстояний вдоль главных компонент может улучшить правильность. Здесь мы воспользуемся опцией PCA выбеливание (whitening), которая преобразует компоненты к одному и тому же масштабу. Операция выбеливания аналогична применению StandardScaler после преобразования. Повторно используя данные, приведенные на рисунке 1 87 шага, выбеливание не только поворачивает данные, но и масштабирует их таким образом, чтобы центральный график представлял собой окружность вместо эллипса (рисунок 1):
[In 26]:
mglearn.plots.plot_pca_whitening()
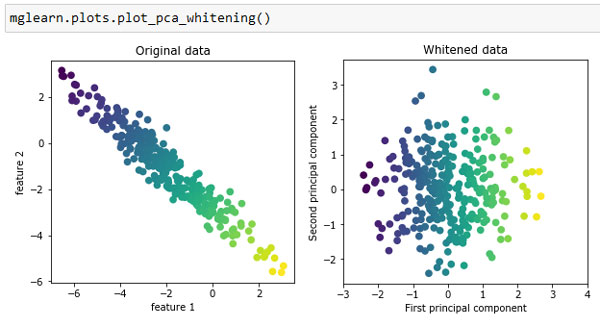
Рис.1. Преобразование данных с использованием выбеливания
Мы подгоняем объект PCA на обучающих данных и извлекаем первые 100 главных компонент. Затем мы преобразуем обучающие и тестовые данные:
[In 27]: pca = PCA(n_components=100, whiten=True, random_state=0).fit(X_train) X_train_pca = pca.transform(X_train) X_test_pca = pca.transform(X_test) print("обучающие данные после PCA: {}".format(X_train_pca.shape)) обучающие данные после PCA: (1547, 100)
Новые данные содержат 100 новых признаков, первые 100 главных компонент. Теперь мы можем использовать новое представление, чтобы классифицировать наши изображения, используя классификатор одного ближайшего соседа:
[In 28]: knn = KNeighborsClassifier(n_neighbors=1) knn.fit(X_train_pca, y_train) print("Правильность на тестовом наборе: {:.2f}".format(knn.score(X_test_pca, y_test))) Правильность на тестовом наборе: 0.31
Наша правильность улучшилась весьма значительно, с 23% до 31%, это подтверждает наше предположение о том, что главные компоненты могут дать лучшее представление данных.
Работая с изображениями, мы можем легко визуализировать найденные главные компоненты. Вспомним, что компоненты соответствуют направлениям в пространстве входных данных. Пространство входных данных здесь представляет собой изображения в градациях серого размером 87x65 пикселей, поэтому направления внутри этого пространства также являются изображениями в градациях серого размером 87x65 пикселей.
Давайте посмотрим на первые несколько главных компонент (рисунок 2):
[In 29]: print("форма pca.components_: {}".format(pca.components_.shape)) форма pca.components_: (100, 5655)
[In 30]: fix, axes = plt.subplots(3, 5, figsize=(15, 12), subplot_kw={'xticks': (), 'yticks': ()}) for i, (component, ax) in enumerate(zip(pca.components_, axes.ravel())): ax.imshow(component.reshape(image_shape),cmap='viridis') ax.set_title("{}. component".format((i + 1)))
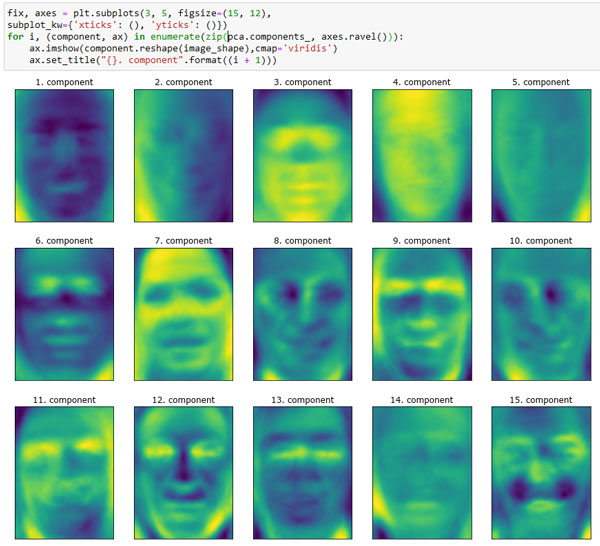
Рис.2. Собственные векторы первых 15 компонент для набора лиц
Несмотря на то что мы, конечно, не сможем понять весь содержательный смысл этих компонент, мы можем догадаться, какие характеристики изображений лиц были выделены некоторыми компонентами. Похоже, что первая компонента главным образом кодирует контраст между лицом и фоном, а вторая компонента кодирует различия в освещенности между правой и левой половинами лица и т.д. Хотя это представление данных в отличие от исходных значений пикселей немного содержательнее, оно по-прежнему весьма далеко от того, как человек привык воспринимать лицо. Поскольку модель PCA основана на пикселях, выравнивание изображения лица (положения глаз, подбородка и носа) и освещенность оказывают сильное влияние на степень сходства двух пиксельных изображений. Однако выравнивание и освещенность, вероятно, будут совсем не теми характеристиками, которые человек будет воспринимать в первую очередь. Когда людей просят оценить сходство между лицами, они в большей степени руководствуются такими признаками, как возраст, пол, выражение лица и прическа, то есть признаками, которые трудно выделить, исходя из интенсивностей пикселей. Важно помнить, что, как правило, алгоритмы в отличие от человека интерпретируют данные (в частности, визуальные данные, например, изображения популярных людей) совершенно по-другому.
На следующем шаге мы закончим изучение этого вопроса.
