На этом шаге мы рассмотрим использование скорректированного коэффициента Рэнда (ARI) для оценки результатов кластеризации.
Существует показатели, которые можно использовать для оценки результатов с точки зрения истинной кластеризации. Наиболее важными среди них являются скорректированный коэффициент Рэнда (adjusted Rand index, ARI) и нормализованная взаимная информация (normalized mutual information, NMI), которые представляют собой количественные показатели. Они принимают значения, близкие к 0, при случайном назначении кластеров, и значение 1, когда полученные результаты кластеризации полностью совпадают с фактическими (обратите внимание, скорректированный коэффициент Рэнда может принимать значения от -1 до 1).
В данном случае мы сравним алгоритмы k-средних, агломеративной кластеризации и DBSCAN, используя ARI. Кроме того, для сравнения мы включим результаты кластеризации, полученные при случайном назначении точек двум кластерам (рисунок 1):
[In 67]: from sklearn.metrics.cluster import silhouette_score X, y = make_moons(n_samples=200, noise=0.05, random_state=0) # масштабируем данные так, чтобы получить нулевое среднее и единичную дисперсию scaler = StandardScaler() scaler.fit(X) X_scaled = scaler.transform(X) fig, axes = plt.subplots(1, 4, figsize=(15, 3), subplot_kw={'xticks': (), 'yticks': ()}) # случайно присваиваем точки двум кластерам для сравнения random_state = np.random.RandomState(seed=0) random_clusters = random_state.randint(low=0, high=2, size=len(X)) # выводим на графике результаты случайного присвоения кластеров axes[0].scatter(X_scaled[:, 0], X_scaled[:, 1], c=random_clusters, cmap=mglearn.cm3, s=60) axes[0].set_title("Случайное присвоение кластеров: {:.2f}".format( silhouette_score(X_scaled, random_clusters))) algorithms = [KMeans(n_clusters=2), AgglomerativeClustering(n_clusters=2), DBSCAN()] for ax, algorithm in zip(axes[1:], algorithms): clusters = algorithm.fit_predict(X_scaled) # выводим на графике принадлежность к кластерам и центры кластеров ax.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters, cmap=mglearn.cm3, s=60) ax.set_title("{} : {:.2f}".format(algorithm.__class__.__name__, silhouette_score(X_scaled, clusters)))
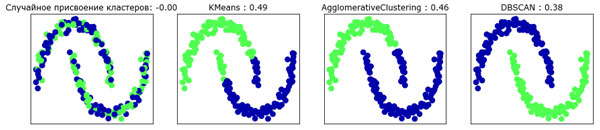
Рис.1. Сравнение результатов случайной кластеризации, k-средних, агломеративной кластеризации и DBSCAN для набора данных two_moons,
использовался скорректированный коэффициент Рэнда
Скорректированный коэффициент Рэнда показывает интуитивно понятные результаты, случайное присвоение кластеров получает оценку 0, а DBSCAN (который отлично восстанавливает нужные кластеры) - оценку 1.
Наиболее частая ошибка, возникающая при оценке результатов кластеризации, заключается в использовании accuracy_score вместо adjusted_rand_score, normalized_mutual_info_score или какой-либо другого показателя качества кластеризации. Проблема, связанная с использованием правильности, заключается в том, что оценка правильности требует точного соответствия меток кластеров, присвоенных точкам, истинным меткам кластеров (ground truth). Однако сами по себе метки кластеров не имеют смысла. Единственное, что имеет значение, это то, какие точки находятся в одном и том же кластере:
from sklearn.metrics import accuracy_score from sklearn.metrics import adjusted_rand_score # эти две маркировки точек соответствуют одним и тем же результатам кластеризации # в clusters1 записаны фактические результаты кластеризации, # а в clusters2 записаны расчетные результаты кластеризации clusters1 = [0, 0, 1, 1, 0] clusters2 = [1, 1, 0, 0, 1] # правильность равна нулю, поскольку ни одна из присвоенных меток не отражает # истинную кластеризацию print("Правильность: {:.2f}".format(accuracy_score(clusters1, clusters2))) # значение скорр. коэффициента Рэнда равно 1, поскольку полученные результаты # точно воспроизводят истинную кластеризацию print("ARI: {:.2f}".format(adjusted_rand_score(clusters1, clusters2))) Правильность: 0.00 ARI: 1.00
На следующем шаге мы рассмотрим оценку качества кластеризации без использования метрик, предполагаюших знание истинной кластеризации.
