На этом шаге мы рассмотрим конкретную задачу, где используются экспертные знания.
Как правило, конструирование признаков является тем важным этапом, на котором применяются экспертные знания (expert knowledge) в конкретной сфере. Хотя во многих случаях цель машинного обучения заключается в том, чтобы избежать построения набора экспертных правил, это вовсе не означает, что априорные знания в той или иной сфере или области должны быть отброшены. Как правило, эксперты могут помочь выделить полезные признаки, которые являются гораздо более информативным, чем исходные данные. Представьте, что вы работаете в туристическом агентстве и вам нужно спрогнозировать цены на авиарейсы. Допустим, у вас есть цены с датами, названиями авиакомпаний, местами отправления и назначения. Возможно, что модель машинного обучения вполне способна построить достойную модель на основе этих данных. Однако некоторые важные факторы, связанные с ценами на авиарейсы останутся без внимания. Например, стоимость авиарейсов, как правило, становится выше в месяцы, приходящиеся на период отпусков, и в праздничные дни. Хотя даты некоторых праздников (например, Рождество) фиксированы, и поэтому их эффект можно учесть, исходя из даты, другие могут зависеть от фазы луны (например, Ханука и Пасха) или устанавливаться органами власти (например, каникулы). Эти события нельзя извлечь из данных, если каждый рейс записывается только с помощью (григорианской) даты. Однако легко добавить признак, который будет фиксировать день полета как предшествующий дню государственного праздника/дню объявления школьных каникул или следующий после дня государственного праздника/дня объявления школьных каникул. Таким образом, априорное знание можно закодировать в признаки, чтобы помочь алгоритму машинного обучения. Добавление признака не означает его обязательное использование алгоритмом машинного обучения и даже если информация о празднике окажется малоинформативной с точки зрения прогнозирования цен на авиарейсы, обогащение данных этим признаком не принесет вреда.
Теперь мы рассмотрим конкретный случай применения экспертных знаний, хотя в данном случае их с полным правом можно назвать "здравым смыслом". Задача заключается в том, чтобы спрогнозировать количество велосипедов, взятых напрокат перед домом Андреаса.
Система общественнотранспортных велосипедов City Bike в Нью-Йорке представляет собой сеть станций проката велосипедов, воспользоваться которой можно с помощью подписки. Станции расположены по всему городу и обеспечивают удобный способ передвижения. Данные о прокате велосипедов выложены на сайте City Bike в анонимном виде и были проанализированы различными способами. Задача, которую мы хотим решить, заключается в том, чтобы предсказать, сколько людей воспользуется прокатом велосипедов перед домом Андреаса, поэтому он знает о количестве оставшихся велосипедов.
Сначала загрузим данные за август 2015 года для этой конкретной станции в виде пандасовского DataFrame. Мы разбили данные на 3-часовые интервалы, чтобы выделить основные тренды для каждого дня:
[In 49]: def load_citibike(): data_mine = pd.read_csv("D:/citibike.csv") data_mine['one'] = 1 data_mine['starttime'] = pd.to_datetime(data_mine.starttime) data_starttime = data_mine.set_index("starttime") data_resampled = data_starttime.resample("3h").sum().fillna(0) return data_resampled.one citibike = load_citibike()
[In 50]: print("данные Citi Bike:\n{}".format(citibike.head())) данные Citi Bike: starttime 2015-08-01 00:00:00 1135 2015-08-01 03:00:00 302 2015-08-01 06:00:00 1781 2015-08-01 09:00:00 7126 2015-08-01 12:00:00 8442 Freq: 3H, Name: one, dtype: int64
Следующий пример показывает количество велосипедов, взятых в прокат, по дням месяца (рисунок 1):
[In 51]: plt.figure(figsize=(10, 3)) xticks = pd.date_range(start=citibike.index.min(), end=citibike.index.max(), freq='D') plt.xticks(xticks, xticks.strftime("%a %m-%d"), rotation=90, ha="left") plt.plot(citibike, linewidth=1) plt.xlabel("Дата") plt.ylabel("Частота проката")
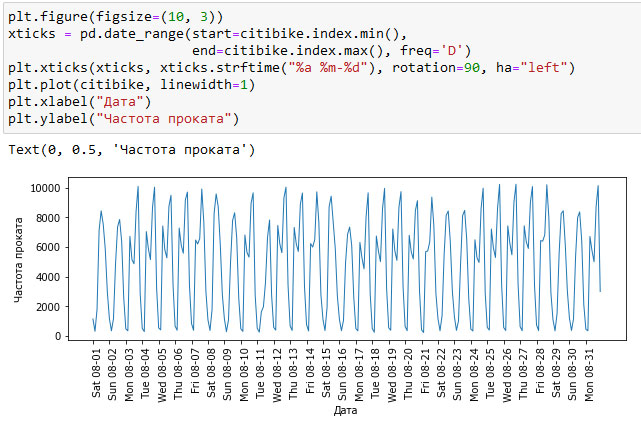
Рис.1. Количество велосипедов, взятых на прокат в течение месяца для определенной станции
Взглянув на данные, мы можем четко выделить день и ночь для каждого 24-часового интервала. Структура данных для будних и выходных дней также выглядит совершенно по-разному. Решая задачу прогнозирования для временных рядов, мы учимся на прошлом и делаем прогноз на будущее. Это означает, что при разбиении данных на обучающий и тестовый наборы, нам нужно взять все данные до определенной даты в качестве обучающей выборки и все данные после этой даты в качестве тестовой выборки. Вот как мы обычно используем прогнозирование временных рядов: обладая информацией о прокате велосипедов в прошлом, мы строим предположения о том, что произойдет завтра. Мы используем первые 184 точки данных, соответствующие первым 23 дням, в качестве обучающего набора, а остальные 64 точки данных, соответствующие оставшимся 8 дням, в качестве тестового набора.
Единственный признак, который мы используем в нашей задаче прогнозирования, - дата и время проката. Таким образом, входной признак - это дата и время, например, 2015-08-01 00:00:00, а зависимая переменная - количество велосипедов, взятых на прокат в последующие три часа (в соответствии с нашим DataFrame).
На следующем шаге мы продолжим изучение этого вопроса.
