На этом шаге мы рассмотрим назначение и использование матрицы ошибок.
Одним из наиболее развернутых способов, позволяющих оценить качество бинарной классификации, является использование матрицы ошибок. Давайте исследуем прогнозы модели LogisticRegression, построенной на предыдущем шаге, с помощью функции confusion_matrix(). Прогнозы для тестового набора данных мы уже сохранили в pred_logreg:
[In 43]: from sklearn.metrics import confusion_matrix confusion = confusion_matrix(y_test, pred_logreg) print("Confusion matrix:\n{}".format(confusion)) Confusion matrix: [[402 1] [ 6 41]]
Вывод confusion_matrix() представляет собой массив размером 2x2, где строки соответствуют фактическим классам, а столбцы соответствуют спрогнозированным классам. В данном случае речь идет о классах "недевятка" и "девятка". Число в каждой ячейке показывает количество примеров, когда спрогнозированный класс, представленный столбцом, совпадает или не совпадает с фактическим классом, представленным строкой.
Следующий график (рисунок 1) иллюстрирует сказанное:
[In 44]:
mglearn.plots.plot_confusion_matrix_illustration()

Рис.1. Матрица ошибок для классификационной задачи "девятка против остальных"
Элементы главной диагонали матрицы ошибок соответствуют правильным прогнозам (результатам классификации), тогда как остальные элементы показывают, сколько примеров, относящихся к одному классу, были ошибочно классифицированы как другой класс.
 Главная диагональ двумерного массива или матрицы A имеет вид A[i, i].
Главная диагональ двумерного массива или матрицы A имеет вид A[i, i].
Объявив "девятку" положительным классом, мы можем рассмотреть элементы матрицы ошибок в терминах ложно положительных (false positive) и ложно отрицательных (false negative) примеров, которые мы ввели ранее. Для полноты картины мы назовем правильно классифицированные положительные примеры истинно положительными (true positive), а правильно классифицированные отрицательные примеры - истинно отрицательными (true negative). Эти термины, как правило, записывают в сокращенном виде как FP, FN, TP и TN и приводят к следующей интерпретации матрицы ошибок (рисунок 2):
[In 45]:
mglearn.plots.plot_binary_confusion_matrix()
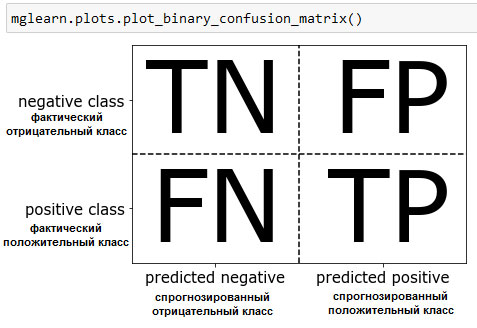
Рис.2. Матрица ошибок для бинарной классификации
Теперь давайте воспользуемся матрицей ошибок для сравнения ранее построенных моделей (две дамми-модели, дерево решений, а также логистическая регрессия):
[In 46]: print("Наиболее часто встречающийся класс:") print(confusion_matrix(y_test, pred_most_frequent)) print("\nДамми-модель:") print(confusion_matrix(y_test, pred_dummy)) print("\nДерево решений:") print(confusion_matrix(y_test, pred_tree)) print("\nЛогистическая регрессия") print(confusion_matrix(y_test, pred_logreg)) Наиболее часто встречающийся класс: [[403 0] [ 47 0]] Дамми-модель: [[361 42] [ 43 4]] Дерево решений: [[390 13] [ 24 23]] Логистическая регрессия [[402 1] [ 6 41]]
Взглянув на матрицу ошибок, становится совершенно ясно, что с моделью pred_most_frequent что-то не так, потому что она всегда предсказывает один и тот же класс. С другой стороны, модель pred_dummy характеризуется очень маленьким количеством истинно положительных примеров (4) по сравнению с остальными примерами, при этом количество ложно положительных примеров существенно больше количества истинно положительных примеров! Прогнозы, полученные с помощью дерева решений, несут гораздо больше смысла, чем прогнозы дамми-модели, хотя правильность у этих моделей почти одинаковая. И, наконец, мы видим, что прогнозы логистической регрессии лучше прогнозов pred_tree во всех аспектах: она имеет большее количество истинно положительных и истинно отрицательных примеров, в то время количество ложно положительных и ложно отрицательных примеров стало меньше. Из этого сравнения ясно, что лишь дерево решений и логистическая регрессия дают разумные результаты, при этом логистическая регрессия работает лучше дерева во всех отношениях. Однако интерпретация матрицы ошибок немного громоздка и хотя мы получили массу информации, анализируя все аспекты матрицы, процесс работы с матрицей ошибок был трудоемким и сложным. Есть несколько способов обобщить информацию, содержащуюся в матрице ошибок. О них мы поговорим на следующем шаге.
На следующем шаге мы рассмотрим связь с правильностью.
