На этом шаге мы рассмотрим назначение и использование этого метода.
Следующий подход вместо исключения несущественных признаков пытается масштабировать признаки в зависимости от степени их информативности. Одним из наиболее распространенных способов такого масштабирования является метод частота термина-обратная частота документа (term frequency-inverse document frequency, tf-idf). Идея этого метода заключается в том, чтобы присвоить большой вес термину, который часто встречается в конкретном документе, но при этом редко встречается в остальных документах корпуса. Если слово часто появляется в конкретном документе, но при этом редко встречается в остальных документах, оно, вероятно, будет описывать содержимое этого документа лучше. В библиотеке scikit-learn метод tf-idf реализован в двух классах:
- TfidfTransformer, который принимает на вход разреженную матрицу, полученную с помощью CountVectorizer, и преобразует ее, и
- TfidfVectorizer, который принимает на вход текстовые данные и выполняет как выделение признаков "мешок слов", так и преобразование tf-idf.
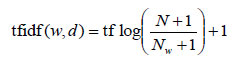
Поскольку tf-idf фактически использует статистические свойства обучающих данных, мы воспользуемся конвейером, чтобы убедиться в достоверности результатов нашего решетчатого поиска. Для этого пишем следующий программный код:
[In 23]: from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.pipeline import make_pipeline pipe = make_pipeline(TfidfVectorizer(min_df=5, norm=None), LogisticRegression()) param_grid = {'logisticregression__C': [0.001, 0.01, 0.1, 1, 10]} grid = GridSearchCV(pipe, param_grid, cv=5) grid.fit(text_train, y_train.ravel()) print("Наилучшее значение перекр проверки: {:.2f}".format(grid.best_score_)) Наилучшее значение перекр проверки: 0.88
Видно, что применение преобразования tf-idf вместо обычных частот слов дало определенное улучшение. Кроме того, мы можем выяснить, какие слова в результате преобразования tf-idf стали наиболее важными. Имейте в виду, что масштабирование tf-idf призвано найти слова, которые лучше всего дискриминируют документы, но при этом оно является методом неконтролируемого обучения. Таким образом, "важное" не обязательно должно быть связано с интересующими метками "положительный отзыв" и "отрицательный отзыв". Сначала мы извлекаем из конвейера наилучшую модель TfidfVectorizer, найденную с помощью решетчатого поиска:
[In 24]: vectorizer = grid.best_estimator_.named_steps["tfidfvectorizer"] # преобразуем обучающий набор данных X_train = vectorizer.transform(text_train) # находим максимальное значение каждого признака по набору данных max_value = X_train.max(axis=0).toarray().ravel() sorted_by_tfidf = max_value.argsort() # получаем имена признаков feature_names = np.array(vectorizer.get_feature_names()) print("Признаки с наименьшими значениями tfidf:\n{}".format( feature_names[sorted_by_tfidf[:20]])) print("Признаки с наибольшими значениями tfidf: \n{}".format( feature_names[sorted_by_tfidf[-20:]])) Признаки с наименьшими значениями tfidf: ['remained' 'acclaimed' 'combines' 'rapidly' 'uniformly' 'diverse' 'avoiding' 'fills' 'feeble' 'admired' 'wherever' 'admission' 'abound' 'starters' 'assure' 'pivotal' 'comprehend' 'deliciously' 'strung' 'inadvertently'] Признаки с наибольшими значениями tfidf: ['nukie' 'reno' 'dominick' 'taz' 'ling' 'rob' 'victoria' 'turtles' 'khouri' 'lorenzo' 'id' 'zizek' 'elwood' 'nikita' 'rishi' 'timon' 'titanic' 'zohan' 'pammy' 'godzilla']
Признаки с низкими значениями tf-idf - это признаки, которые либо встречаются во многих документах, либо используются редко и только в очень длинных документах. Интересно отметить, что многие признаки с высокими значениями tf-idf на самом деле соответствуют названиям некоторых шоу или фильмов. Эти термины встречаются лишь в отзывах, посвященным конкретному шоу или франшизе, но при этом они встречаются в данных отзывах очень часто. Это очевидно для таких терминов как "smallville" и "doodlebops", но в нашем случае и вполне нейтральное слово "scanners" тоже относится к названию фильма. Эти слова вряд ли помогут нам классифицировать тональность отзывов (если только некоторые франшизы не оцениваются всеми зрителями положительно или отрицательно), однако они, разумеется, содержат много конкретной информации об отзывах.
Кроме того, мы можем найти слова, которые имеют низкое значение обратной частоты документа, то есть слова, которые встречаются часто и поэтому считаются менее важными. Значения обратной частоты документа, найденные для обучающего набора, хранятся в атрибуте idf_:
[In 25]: sorted_by_idf = np.argsort(vectorizer.idf_) print("Признаки с наименьшими значениями idf:\n{}".format( feature_names[sorted_by_idf[:100]])) Признаки с наименьшими значениями idf: ['the' 'and' 'of' 'to' 'this' 'is' 'it' 'in' 'that' 'but' 'for' 'with' 'was' 'as' 'on' 'movie' 'not' 'one' 'be' 'have' 'are' 'film' 'you' 'all' 'at' 'an' 'by' 'from' 'so' 'like' 'who' 'there' 'they' 'his' 'if' 'out' 'just' 'about' 'he' 'or' 'has' 'what' 'some' 'can' 'good' 'when' 'more' 'up' 'time' 'very' 'even' 'only' 'no' 'see' 'would' 'my' 'story' 'really' 'which' 'well' 'had' 'me' 'than' 'their' 'much' 'were' 'get' 'other' 'do' 'been' 'most' 'also' 'into' 'don' 'her' 'first' 'great' 'how' 'made' 'people' 'will' 'make' 'because' 'way' 'could' 'bad' 'we' 'after' 'them' 'too' 'any' 'then' 'movies' 'watch' 'she' 'think' 'seen' 'acting' 'its' 'characters']
Как и следовало ожидать, словами с низкими значениями idf стали английские стоп-слова типа "the" и "no". Но некоторые из них характерны для киноотзывов. Это слова типа "movie", "film", "time", "story" и так далее. Интересно, что в соответствии с метрикой tf-idf слова "good", "great" и "bad" также были отнесены к самым часто встречающимся и потому "самым нерелевантным" словам, хотя можно было бы ожидать, что они будут иметь очень важное значение для анализа тональности.
На следующем шаге мы рассмотрим исследование коэффициентов модели.
