В этом приложении приведено краткое описание основных функций библиотеки MPI.
Все функции MPI (кроме MPI_Wtime и MPI_Wtick) возвращают в качестве своего значения код завершения. При успешном выполнении функции возвращаемый код равен MPI_SUCCESS. Другие значения кода завершения свидетельствуют об обнаружении тех или иных ошибочных ситуаций в ходе выполнения функций. Для выяснения типа обнаруженной ошибки используются предопределенные именованные константы, среди которых:
- MPI_ERR_BUFFER - неправильный указатель на буфер;
- MPI_ERR_TRUNCATE - сообщение превышает размер приемного буфера;
- MPI_ERR_COMM - неправильный коммуникатор;
- MPI_ERR_RANK - неправильный ранг процесса и др.
Полный список констант для проверки кода завершения содержится в файле mpi.h.
Основные функции библиотеки MPI
- где argc - указатель на количество параметров командной строки, argv - параметры командной строки.
int MPI_Init (int *argc, char ***argv),
Применяется для инициализации среды выполнения MPI-программы (должна быть первой вызываемой функцией MPI). Является обязательной и должна быть выполнена (и только один раз) каждым процессом параллельной программы.
- Завершает код, содержащий функции MPI (должна быть последней вызываемой функцией). Является обязательной и должна быть выполнена (и только один раз) каждым процессом параллельной программы.
int MPI_Finalize (void)
- где comm - коммуникатор, размер которого определяется, size - определяемое количество процессов в коммуникаторе.
int MPI_Comm_size (MPI_Comm comm, int *size),
Определяет количество процессов в выполняемой параллельной программе. Коммуникатор MPI_COMM_WORLD создается по умолчанию и представляет все процессы выполняемой параллельной программы.
- где comm - коммуникатор, в котором определяется ранг процесса, rank - ранг процесса в коммуникаторе.
int MPI_Comm_rank (MPI_Comm comm, int *rank),
Определяет ранг процесса, выполнившего вызов этой функции (то есть переменная rank примет различные значения у разных процессоров). Функция, как правило, вместе с функцией MPI_Comm_size выполняется сразу после MPI_Init.
- где buf - адрес буфера памяти, в котором располагаются данные отправляемого сообщения, count - количество элементов данных пересылаемого сообщения, type - тип элементов данных пересылаемого сообщения, dest - ранг процесса, которому отправляется сообщение, tag - значение-тег, используемое для идентификации сообщения, comm - коммуникатор, в рамках которого выполняется передача данных.
int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm),
Используется для передачи сообщений в стандартном режиме. Процессы, между которыми выполняется передача данных, обязательно должны принадлежать коммуникатору, указываемому в функции MPI_Send. Параметр tag используется только при необходимости различения передаваемых сообщений, в противном случае в качестве значения параметра может быть использовано произвольное положительное целое число. На время выполнения функции процесс-отправитель сообщения блокируется.
Сразу же после завершения функции MPI_Send процесс-отправитель может начать повторно использовать буфер памяти, в котором располагалось отправляемое сообщение. В момент завершения функции MPI_Send состояние самого пересылаемого сообщения может быть совершенно различным: сообщение может располагаться в процессе-отправителе, может находиться в состоянии передачи, может храниться в процессе-получателе или же может быть принято процессом-получателем при помощи функции MPI_Recv. Тем самым, завершение функции MPI_Send означает лишь, что операция передачи начала выполняться и пересылка сообщения рано или поздно будет выполнена.
Для указания типа пересылаемых данных в MPI имеется ряд базовых типов, полный список которых приведен в таблице 1.
Таблица 1. Базовые типы данных MPI для алгоритмического языка С Тип данных MPI Тип данных С MPI_BYTE MPI_CHAR signed char MPI_DOUBLE double MPI_FLOAT float MPI_INT int MPI_LONG long MPI_LONG_DOUBLE long double MPI_PACKED MPI_SHORT short MPI_UNSIGNED_CHAR unsigned char MPI_UNSIGNED unsigned int MPI_UNSIGNED_LONG unsigned long MPI_UNSIGNED_SHORT unsigned short - где аргументы те же, что и у функции MPI_Send.
int MPI_Isend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *request),
Неблокирующая функция передачи сообщений в стандартном режиме. Перед своим завершением функция определяет переменную request, которая далее может использоваться для проверки завершения инициированной операции обмена.
- где аргументы те же, что и у функции MPI_Send.
MPI_Ssend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm),
Функция отправки сообщения в синхронном режиме. Синхронный режим состоит в том, что завершение функции отправки сообщения происходит только при получении от процесса-получателя подтверждения о начале приема отправленного сообщения. Отправленное сообщение или полностью принято процессом-получателем, или находится в состоянии приема.
Синхронный режим является наиболее медленным, так как требует подтверждения приема, однако не нуждается в дополнительной памяти для хранения сообщения. Этот режим может быть рекомендован для передачи длинных сообщений.
- где аргументы те же, что и у функции MPI_Send.
int MPI_Issend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *request),
Неблокирующая функция отправки сообщения в синхронном режиме. Перед своим завершением функция определяет переменную request, которая далее может использоваться для проверки завершения инициированной операции обмена.
- где аргументы те же, что и у функции MPI_Send.
MPI_Bsend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm),
Функция отправки сообщения в буферизованном режиме. Буферизованный режим предполагает использование дополнительных системных или задаваемых пользователем буферов для копирования в них отправляемых сообщений. Функция отправки сообщения завершается сразу же после копирования сообщения в системный буфер (см. функции MPI_Buffer_attach, MPI_Buffer_detach).
Буферизованный режим выполняется достаточно быстро, но может приводить к большим расходам ресурсов (памяти), - в целом может быть рекомендован для передачи коротких сообщений.
- где аргументы те же, что и у функции MPI_Send.
int MPI_Ibsend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *request),
Неблокирующая функция отправки сообщения в буферизованном режиме. Перед своим завершением функция определяет переменную request, которая далее может использоваться для проверки завершения инициированной операции обмена.
- где buf - адрес буфера памяти; size - размер буфера.
int MPI_Buffer_attach (void *buf, int size),
Создает буфер памяти для применения буферизованного режима передачи данных.
- где buf - адрес буфера памяти; size - возвращаемый размер буфера.
int MPI_Buffer_detach (void *buf, int *size),
Используется для отключения буфера памяти от MPI.
- где аргументы те же, что и у функции MPI_Send.
MPI_Rsend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm),
Функция отправки сообщения в режиме по готовности. Режим передачи по готовности может быть использован, только если операция приема сообщения уже инициирована. Буфер сообщения после завершения функции отправки сообщения может быть повторно использован.
Режим передачи по готовности формально является наиболее быстрым, но используется достаточно редко, так как обычно сложно гарантировать готовность операции приема.
- где аргументы те же, что и у функции MPI_Send.
int MPI_Irsend (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *request),
Неблокирующая функция отправки сообщения в режиме по готовности. Перед своим завершением функция определяет переменную request, которая далее может использоваться для проверки завершения инициированной операции обмена.
- где buf - адрес буфера памяти, в котором располагаются данные принимаемого сообщения, count - количество элементов данных принимаемого сообщения; type - тип элементов данных принимаемого сообщения; source - ранг процесса, от которого должен быть выполнен прием сообщения; tag - тег сообщения, которое должно быть принято для процесса; comm - коммуникатор, в рамках которого выполняется передача данных; status - указатель на структуру данных с информацией о результате выполнения.
int MPI_Recv (void *buf, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Status *status),
Используется для приема сообщения. Типы элементов передаваемого и принимаемого сообщения должны совпадать. При необходимости приема сообщения от любого процесса-отправителя для параметра source может быть указано значение MPI_ANY_SOURCE (в отличие от функции передачи MPI_Send, которая отсылает сообщение строго определенному адресату). Аналогично, при необходимости приема сообщения с любым тегом для параметра tag может быть указано значение MPI_ANY_TAG. Параметр status позволяет определить ряд характеристик принятого сообщения:
- status.MPI_SOURCE - ранг процесса-отправителя принятого сообщения;
- status.MPI_TAG - тег принятого сообщения.
Вызов функции MPI_Recv не обязан быть согласованным со временем вызова соответствующей функции передачи сообщения MPI_Send - прием сообщения может быть инициирован до момента, в момент или после момента начала отправки сообщения.
По завершении функции MPI_Recv в заданном буфере памяти будет располагаться принятое сообщение. Принципиальный момент здесь состоит в том, что функция MPI_Recv является блокирующей для процесса-получателя, то есть его выполнение приостанавливается до завершения работы функции. Таким образом, если по каким-то причинам ожидаемое для приема сообщение будет отсутствовать, выполнение параллельной программы будет блокировано.
В отличие от функции MPI_Send для функции приема MPI_Recv не существует различных режимов работы.
- где аргументы те же, что и у функции MPI_Recv.
int MPI_Irecv (void *buf, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Request *request),
Неблокирующая функция приема сообщений. Перед своим завершением функция определяет переменную request, которая далее может использоваться для проверки завершения инициированной операции обмена.
- где status - статус операции MPI_Recv, type - тип принятых данных, count - количество элементов данных в сообщении.
int MPI_Get_count (MPI_Status *status, MPI_Datatype type, int *count),
Определяет количество элементов данных в принятом сообщении.
- где request - дескриптор операции, определенный при вызове неблокирующей функции; flag - результат проверки (равен true, если операция завершена); status - результат выполнения операции обмена (только для завершенной операции).
int MPI_Test (MPI_Request *request, int *flag, MPI_status *status),
Осуществляет проверку состояния выполняемой неблокирующей операции передачи данных. Операция проверки является неблокирующей, то есть процесс может проверить состояние неблокирующей операции обмена и продолжить далее свои вычисления, если по результатам проверки окажется, что операция все еще не завершена.
- где request - дескриптор операции, определенный при вызове неблокирующей функции; status - результат выполнения операции обмена (только для завершенной операции).
int MPI_Wait (MPI_Request *request, MPI_status *status),Блокирующая операция ожидания завершения операции. Применяется, если при выполнении неблокирующей операции окажется, что продолжение вычислений невозможно без получения передаваемых данных.
- где count - длина списка; array_of_requests - массив запросов (массив дескрипторов); flag - результат проверки (равен true, если обмены, связанные с активными дескрипторами в массиве, завершены); array_of_statuses - массив статусов.
MPI_Testall (int count, MPI_Request array_of_requests[], int *flag, MPI_Status array_of_statuses[]),
Осуществляет проверку завершения всех перечисленных операций обмена.
- где count - длина списка; array_of_requests - массив запросов (массив дескрипторов); array_of_statuses - массив статусов.
MPI_Waitall (int count, MPI_Request array_of_requests, MPI_Status array_of_statuses),Выполняет ожидание завершения всех операций обмена.
- где count - длина списка; array_of_requests - массив запросов (массив дескрипторов); index - индекс дескриптора для завершенной операции (целое); flag - результат проверки (true, если одна из операций завершена); status - статусный объект (статус).
MPI_Testany (int count, MPI_Request *array_of_requests, int *index, int *flag, MPI_Status *status),
Выполняет проверку завершения хотя бы одной из перечисленных операций обмена.
- где count - длина списка; array_of_requests - массив запросов (массив дескрипторов); index - индекс дескриптора для завершенной операции (целое); status - статусный объект (статус).
MPI_Waitany (int count, MPI_Request *array_of_requests, int *index, MPI_Status *status),
Выполняет ожидание завершения любой из перечисленных операций обмена.
- где incount - длина массива запросов; array_of_requests - массив запросов (массив дескрипторов); outcount - число завершенных запросов; array_of_indices - массив индексов завершенных операций; array_of_statuses - массив статусных объектов завешенных операций.
MPI_Testsome (int incount, MPI_Request *array_of_requests, int *outcount, int *array_of_indices, MPI_Status *array_of_statuses)
Выполняет проверку завершения каждой из перечисленных операций обмена.
- где incount - длина массива запросов; array_of_requests - массив запросов; outcount - число завершенных запросов; array_of_indices - массив индексов операций, которые завершены; array_of_statuses - массив статусных операций для завершенных операций.
MPI_Waitsome (int incount, MPI_Request *array_of_requests, int *outcount, int *array_of_indices, MPI_Status *array_of_statuses),
Выполняет ожидание завершения хотя бы одной из перечисленных операций обмена и оценку состояния по всем операциям.
- Получение текущего момента времени. Результат ее вызова есть количество секунд, прошедшее от некоторого определенного момента времени в прошлом. Этот момент времени в прошлом, от которого происходит отсчет секунд, может зависеть от среды реализации библиотеки MPI, и, тем самым, для ухода от такой зависимости функцию MPI_Wtime следует использовать только для определения длительности выполнения тех или иных фрагментов кода параллельных программ. Возможная схема применения функции MPI_Wtime может состоять в следующем:
double MPI_Wtime (void)
double t1, t2, dt; t1 = MPI_Wtime(); . . . t2 = MPI_Wtime(); dt = t2 - t1; - Используется для определения текущего значения точности. Функция позволяет определить время в секундах между двумя последовательными показателями времени аппаратного таймера примененной компьютерной системы.
double MPI_Wtick (void)
- где buf, count, type - буфер памяти с отправляемым сообщением (для процесса с рангом 0) и для приема сообщений (для всех остальных процессов); root - ранг процесса, выполняющего рассылку данных; comm - коммуникатор, в рамках которого выполняется передача данных.
int MPI_Bcast (void *buf, int count, MPI_Datatype type, int root, MPI_Comm comm),
Выполняет операцию передачи данных от одного процесса всем процессам, входящим в коммуникатор (широковещательная рассылка данных). Функция MPI_Bcast определяет коллективную операцию, и, тем самым, при выполнении необходимых рассылок данных вызов функции MPI_Bcast должен быть осуществлен всеми процессами указываемого коммуникатора.
- где sendbuf - буфер памяти с отправляемым сообщением; recvbuf - буфер памяти для результирующего сообщения (только для процесса с рангом root); count - количество элементов в сообщениях; type - тип элементов сообщений; op - операция, которая должна быть выполнена над данными; root - ранг процесса, на котором должен быть получен результат; comm - коммуникатор, в рамках которого выполняется операция.
int MPI_Reduce (void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op op, int root, MPI_Comm comm),
Реализует обработку данных (редукцию). Функция MPI_Reduce определяет коллективную операцию, и, тем самым, вызов функции должен быть выполнен всеми процессами указываемого коммуникатора. При этом все вызовы функции должны содержать одинаковые значения параметров count, type, op, root, comm. Передача сообщений должна быть выполнена всеми процессами, результат операции будет получен только процессом с рангом root. Выполнение операции редукции осуществляется над отдельными элементами передаваемых сообщений. Так, например, если сообщения содержат по два элемента данных и выполняется операция суммирования MPI_SUM, то результат также будет состоять из двух значений, первое из которых будет содержать сумму первых элементов всех отправленных сообщений, а второе значение будет равно сумме вторых элементов сообщений соответственно.
В качестве операций редукции данных могут быть использованы предопределенные в MPI операции - см. таблицу 2.
Таблица 2. Базовые типы операций MPI для функций редукции данных Операции Описание MPI_MAX Определение максимального значения MPI_MIN Определение минимального значения MPI_SUM Определение суммы значений MPI_PROD Определение произведения значений MPI_LAND Выполнение логической операции "И" над значениями сообщений MPI_BAND Выполнение битовой операции "И" над значениями сообщений MPI_LOR Выполнение логической операции "ИЛИ" над значениями сообщений MPI_BOR Выполнение битовой операции "ИЛИ" над значениями сообщений MPI_LXOR Выполнение логической операции исключающего "ИЛИ" над значениями сообщений MPI_BXOR Выполнение битовой операции исключающего "ИЛИ" над значениями сообщений MPI_MAXLOC Определение максимальных значений и их индексов MPI_MINLOC Определение минимальных значений и их индексов Не все сочетания типа данных type и операции op возможны, разрешенные сочетания перечислены в таблице 3.
Таблица 3. Разрешенные сочетания операции типа операнда в операции редукции Операции Допустимый тип операндов для алгоритмического языка C MPI_MAX, MPI_MIN, MPI_SUM, MPI_PROD Целый, вещественный MPI_LAND, MPI_LOR, MPI_LXOR Целый MPI_BAND, MPI_BOR, MPI_BXOR Целый, байтовый MPI_MINLOC, MPI_MAXLOC Целый, вещественный - где comm - коммуникатор, в рамках которого выполняется операция.
int MPI_Barrier (MPI_Comm comm),Выполняет синхронизация процессов, то есть одновременное достижение процессами тех или иных точек процесса вычислений. Функция MPI_Barrier определяет коллективную операцию, и, тем самым, при использовании она должна вызываться всеми процессами используемого коммуникатора. При вызове функции MPI_Barrier выполнение процесса блокируется, продолжение вычислений процесса произойдет только после вызова функции MPI_Barrier всеми процессами коммуникатора.
- где comm - коммуникатор, процессы которого необходимо аварийно остановить; errorcode - код возврата из параллельной программы.
int MPI_Abort (MPI_Comm comm, int errorcode),
Для корректного завершения параллельной программы в случае непредвиденных ситуаций. Эта функция корректно прерывает выполнение параллельной программы, оповещая об этом событии среду MPI.
- где sbuf, scount, stype, dest, stag - параметры передаваемого сообщения; rbuf, rcount, rtype, source, rtag - параметры принимаемого сообщения; comm - коммуникатор, в рамках которого выполняется передача данных; status - структура данных с информацией о результате выполнения операции.
int MPI_Sendrecv (void *sbuf, int scount, MPI_Datatype stype, int dest, int stag, void *rbuf, int rcount, MPI_Datatype rtype, int source, int rtag, MPI_Comm comm, MPI_Status *status),
Одновременно выполняет операции передачи и приема данных с использованием двух различных буферов памяти.
- где buf, count, type - параметры передаваемого сообщения; dest - ранг процесса, которому отправляется сообщение; stag - тег для идентификации отправляемого сообщения; source - ранг процесса, от которого выполняется прием сообщения; rtag - тег для идентификации принимаемого сообщения; comm - коммуникатор, в рамках которого выполняется передача данных; status - структура данных с информацией о результате выполнения операции.
int MPI_Sendrecv_replace (void *buf, int count, MPI_Datatype type, int dest, int stag, int source, int rtag, MPI_Comm comm, MPI_Status* status),
Одновременно выполняет операции передачи и приема данных с использованием единого буфера (используется в случае, когда отсылаемое сообщение больше не нужно на процессе-отправителе).
- где sbuf, scount, stype - параметры передаваемого сообщения (scount определяет количество элементов, передаваемых на каждый процесс); rbuf, rcount, rtype - параметры сообщения, принимаемого в процессах; root - ранг процесса, выполняющего рассылку данных; comm - коммуникатор, в рамках которого выполняется передача данных.
int MPI_Scatter (void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm),
Выполняет обобщенную операцию передачи данных от одного процесса всем процессам (распределение данных). Отличается от широковещательной рассылки тем, что процесс передает различным процессам различные данные.
При вызове этой функции процесс с рангом root произведет передачу данных всем другим процессам в коммуникаторе. Каждому процессу будет отправлено scount элементов. Процесс с рангом 0 получит блок данных из sbuf элементов с индексами от 0 до scount-1, процессу с рангом 1 будет отправлен блок из sbuf элементов с индексами от scount до 2*(scount-1) и т.д. Тем самым, общий размер отправляемого сообщения должен быть равен scount*p элементов, где p есть количество процессов в коммуникаторе comm.
Так как функция MPI_Scatter определяет коллективную операцию, вызов этой функции при выполнении рассылки данных должен быть обеспечен на каждом процессе коммуникатора.
- где значения аргументов те же, что и для MPI_Scatter; displs - массив (размер равен числу процессов в группе), i-ое значение определяет смещение относительно начала sbuf для данных, посылаемых процессу i.
MPI_Scatterv (void* sbuf, int *scounts, int *displs, MPI_Datatype stype, void* rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm),
В отличие от функции MPI_Scatter, которая передает всем процессам сообщения одинакового размера, выполняет более общий вариант операции распределения данных, когда размеры сообщений для процессов могут быть различны.
- где sbuf, scount, stype - параметры передаваемого сообщения; rbuf, rcount, rtype - параметры принимаемого сообщения; root - ранг процесса, выполняющего сбор данных; comm - коммуникатор, в рамках которого выполняется передача данных.
int MPI_Gather (void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm comm),
Выполняет операцию обобщенной передачи данных от всех процессов одному процессу (сбор данных).
При выполнении функции MPI_Gather каждый процесс в коммуникаторе передает данные из буфера sbuf на процесс с рангом root. Процесс с рангом root собирает все получаемые данные в буфере rbuf (размещение данных в буфере осуществляется в соответствии с рангами процессов-отправителей сообщений). Для того чтобы разместить все поступающие данные, размер буфера rbuf должен быть равен scount*p элементов, где p есть количество процессов в коммуникаторе comm.
Функция MPI_Gather также определяет коллективную операцию, и ее вызов при выполнении сбора данных должен быть обеспечен в каждом процессе коммуникатора.
- где аргументы те же, что и у MPI_Gather; displs - массив (размер равен числу процессов в группе), i-ое значение определяет смещение i-го блока данных относительно начала rbuf.
MPI_Gatherv (void* sbuf, int scount, MPI_Datatype stype, void* rbuf, int *rcounts, int *displs, MPI_Datatype rtype, int root, MPI_Comm comm),
В отличие от функции MPI_Gather, которая передает процессу сообщения одинакового размера, выполняет более общий вариант операции передачи данных, когда размеры сообщений для процессов-отправителей могут быть различны.
- где sbuf, scount, stype - параметры передаваемого сообщения; rbuf, rcount, rtype - параметры принимаемого сообщения; comm - коммуникатор, в рамках которого выполняется передача данных.
int MPI_Allgather (void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm),
Применяется для получения всех собираемых данных на каждом из процессов коммуникатора (функция сбора и рассылки).
- где аргументы те же, что и у MPI_Allgather; displs - массив (размер равен числу процессов в группе), i-ое значение определяет смещение относительно начала rbuf i-го блока данных.
int MPI_Allgatherv(void* sbuf, int scount, MPI_Datatype stype, void* rbuf, int *rcounts, int *displs, MPI_Datatype rtype, MPI_Comm comm),
В отличие от функции MPI_Allgather, которая оперирует сообщениями одинакового размера, выполняет более общий вариант операции, когда размеры сообщений для процессов могут быть различны.
- где sbuf, scount, stype - параметры передаваемых сообщений; rbuf, rcount, rtype - параметры принимаемых сообщений; comm - коммуникатор, в рамках которого выполняется передача данных.
int MPI_Alltoall (void *sbuf,int scount,MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm),
Применяется для передачи данных от всех процессов всем процессам. При выполнении функции MPI_Alltoall каждый процесс в коммуникаторе передает данные из scount элементов каждому процессу (общий размер отправляемых сообщений в процессах должен быть равен scount*p элементов, где p есть количество процессов в коммуникаторе comm) и принимает сообщения от каждого процесса.
Вызов функции MPI_Alltoall при выполнении операции общего обмена данными должен быть выполнен в каждом процессе коммуникатора.
- где аргументы те же, что и у MPI_Alltoall; sdispls - массив (размера группы). Элемент j содержит смещение области (относительно sendbuf), из которой берутся данные для процесса j; rdispls - массив (размера группы). Элемент i определяет смещение области (относительно recvbuf), в которой размещаются данные, получаемые из процесса i.
int MPI_Alltoallv (void *sbuf, int *scounts, int *sdispls, MPI_Datatype stype, void *rbuf, int *rcounts, int *rdispls, MPI_Datatype rtype, MPI_Comm comm),
Выполняет операцию общего обмена данных, когда размеры передаваемых процессами сообщений различны.
- где sendbuf - буфер памяти с отправляемым сообщением; recvbuf - буфер памяти для результирующего сообщения; count - количество элементов в сообщениях; type - тип элементов сообщений; op - операция, которая должна быть выполнена над данными; comm - коммуникатор, в рамках которого выполняется операция.
int MPI_Allreduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op op, MPI_Comm comm),
Используется для получения результатов редукции данных на каждом из процессов коммуникатора.
- где аргументы те же, что и у MPI_Allreduce; recvcounts - массив, в котором задаются размеры блоков, посылаемых процессам.
MPI_Reduce_scatter (void* sendbuf, void* recvbuf, int *recvcounts, MPI_Datatype type, MPI_Op op, MPI_Comm comm),Функция MPI_Reduce_scatter отличается от MPI_Allreduce тем, что результат операции разрезается на непересекающиеся части по числу процессов в группе, i-ая часть посылается i-ому процессу в его буфер приема. Длины этих частей задает третий параметр, являющийся массивом.
- где sendbuf - буфер памяти с отправляемым сообщением; recvbuf - буфер памяти для результирующего сообщения; count - количество элементов в сообщениях; type - тип элементов сообщений; op - операция, которая должна быть выполнена над данными; comm - коммуникатор, в рамках которого выполняется операция.
int MPI_Scan (void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op op, MPI_Comm comm),
Выполняет операцию сбора и обработки данных, при этом обеспечивается получение всех частичных результатов редуцирования.
Элементы получаемых сообщений представляют собой результаты обработки соответствующих элементов передаваемых процессами сообщений, при этом для получения результатов на процессе с рангом i, 0<=i<n, используются данные от процессов, ранг которых меньше или равен i, то есть
где S есть операция, задаваемая при вызове функции MPI_Scan.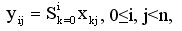
- где type - тип данных, протяженность которого отыскивается; extent - протяженность типа.
int MPI_Type_extent (MPI_Datatype type, MPI_Aint *extent),Используется для получения значения протяженности типа.
- где type - тип данных, размер которого отыскивается; size - размер типа.
int MPI_Type_size (MPI_Datatype type, MPI_Aint *size),Используется для нахождения размера типа.
- где type - тип данных, нижняя граница которого отыскивается; disp - нижняя граница типа.
int MPI_Type_lb (MPI_Datatype type, MPI_Aint *disp),Используется для определения нижней границы типа.
- где type - тип данных, верхняя граница которого отыскивается; disp - верхняя граница типа.
int MPI_Type_ub (MPI_Datatype type, MPI_Aint *disp),Используется для определения верхней границы типа.
- int MPI_Address (void *location, MPI_Aint *address),
где location - адрес памяти; address - адрес памяти в переносимом MPI-формате.
Используется для получения адреса переменной.
- где count - количество элементов исходного типа; oldtype - исходный тип данных; newtype - новый определяемый тип данных.
int MPI_Type_contiguous (int count, MPI_Data_type oldtype, MPI_Datatype *newtype),
Используется при непрерывном способе конструирования производного типа данных. Непрерывный способ позволяет определить непрерывный набор элементов существующего типа как новый производный тип.
- где count - количество блоков; blocklen - размер каждого блока; stride - количество элементов, расположенных между двумя соседними блоками; oldtype - исходный тип данных; newtype - новый определяемый тип данных.
int MPI_Type_vector (int count, int blocklen, int stride, MPI_Data_type oldtype, MPI_Datatype *newtype),
Используется при векторном способе конструирования производного типа данных. Векторный способ обеспечивает создание нового производного типа как набора элементов существующего типа, между элементами которого имеются регулярные промежутки памяти. При этом размер промежутков задается в числе элементов исходного типа, в то время как в варианте векторного способа этот размер указывается в байтах.
- где аргументы те же, что и для MPI_Type_vector.
int MPI_Type_hvector (int count, int blocklen, MPI_Aint stride, MPI_Data_type oldtype, MPI_Datatype *newtype),
Отличие способа конструирования, определяемого функцией MPI_Type_hvector, состоит лишь в том, что параметр stride для определения интервала между блоками задается в байтах, а не в элементах исходного типа данных.
- где count - количество блоков; blocklens - количество элементов в каждом блоке; indices - смещение каждого блока от начала типа; oldtype - исходный тип данных; newtype - новый определяемый тип данных.
int MPI_Type_indexed(int count, int blocklens[], int indices[], MPI_Data_type oldtype, MPI_Datatype *newtype),
Используется при индексном способе конструирования производного типа данных. При индексном способе новый производный тип создается как набор блоков разного размера из элементов исходного типа, при этом между блоками могут иметься разные промежутки памяти.
- где аргументы те же, что и для MPI_Type_indexed.
int MPI_Type_hindexed(int count, int blocklens[], MPI_Aint indices[], MPI_Data_type oldtype, MPI_Datatype *newtype),
Отличается от MPI_Type_indexed тем, что элементы indices для определения интервалов между блоками задаются в байтах, а не в элементах исходного типа данных.
- где count - количество блоков; blocklens - количество элементов в каждом блоке; indices - смещение каждого блока от начала типа (в байтах); oldtypes - исходные типы данных в каждом блоке в отдельности; newtype - новый определяемый тип данных.
int MPI_Type_struct(int count, int blocklens[], MPI_Aint indices[], MPI_Data_type oldtypes[], MPI_Datatype *newtype),
Используется при структурном способе конструирования производного типа данных. Структурный способ является самым общим методом конструирования производного типа данных при явном задании соответствующей карты типа. Он позволяет указывать типы элементов для каждого блока в отдельности.
- где type - объявляемый тип данных.
int MPI_Type_commit(MPI_Datatype *type),Функция объявляет созданный тип перед его использованием.
- где type - аннулируемый тип данных.
int MPI_Type_free(MPI_Datatype *type),Функция аннулирует производный тип при завершении использования.
- где data - буфер памяти с элементами для упаковки; count - количество элементов в буфере; type - тип данных для упаковываемых элементов; buf - буфер памяти для упаковки; bufsize - размер буфера в байтах; bufpos - позиция для начала записи в буфер (в байтах от начала буфера); comm - коммуникатор для упакованного сообщения.
int MPI_Pack(void *data, int count, MPI_Datatype type, void *buf, int bufsize, int *bufpos, MPI_Comm comm),
Упаковывает в буфер входящие в состав сообщения данные.
- где count - количество элементов в буфере; type - тип данных для упаковываемых элементов; comm - коммуникатор для упакованного сообщения; size - рассчитаный размер буфера.
int MPI_Pack_size(int count, MPI_Datatype type, MPI_Comm comm, int *size),
Определяет необходимого размера буфера для упаковки. После упаковки всех необходимых данных подготовленный буфер может быть использован в функциях передачи данных с указанием типа MPI_PACKED.
- где buf - буфер памяти с упакованными данными; bufsize - размер буфера в байтах; bufpos - позиция начала данных в буфере (в байтах от начала буфера); data - буфер памяти для распаковываемых данных; count - количество элементов в буфере; type - тип распаковываемых данных; comm - коммуникатор для упакованного сообщения.
int MPI_Unpack (void *buf, int bufsize, int *bufpos, void *data, int count, MPI_Datatype type, MPI_Comm comm),
Используется для распаковки данных сообщения. Начальное значение переменной bufpos должно быть сформировано до начала распаковки и далее устанавливается функцией MPI_Unpack. Вызов функции MPI_Unpack осуществляется последовательно для распаковки всех упакованных данных, при этом порядок распаковки должен соответствовать порядку упаковки.
- где comm - коммуникатор; group - группа, связанная с коммуникатором.
int MPI_Comm_group (MPI_Comm comm, MPI_Group *group),Используется для получения группы, связанной с существующим коммуникатором.
- где oldgroup - существующая группа; n - число элементов в массиве ranks; ranks - массив рангов процессов, которые будут включены в новую группу; newgroup - созданная группа.
int MPI_Group_incl (MPI_Group oldgroup, int n, int *ranks, MPI_Group *newgroup),
Осуществляет создание новой группы newgroup из существующей группы oldgroup, которая будет включать в себя n процессов - их ранги перечисляются в массиве ranks.
- где oldgroup - существующая группа; n - число элементов в массиве ranks; ranks - массив рангов процессов, которые будут исключены из новой группы; newgroup - созданная группа.
int MPI_Group_excl (MPI_Group oldgroup, int n, int *ranks, MPI_Group *newgroup),
Осуществляет создание новой группы newgroup из группы oldgroup, которая будет включать в себя n процессов, чьи ранги не совпадают с рангами, перечисленными в массиве ranks.
- где group1 - первая группа; group2 - вторая группа; newgroup - объединение групп.
int MPI_Group_union (MPI_Group group1, MPI_Group group2, MPI_Group *newgroup),Осуществляет создание новой группы newgroup как объединение групп group1 и group2.
- где group1 - первая группа; group2 - вторая группа; newgroup - пересечение групп.
int MPI_Group_intersection (MPI_Group group1, MPI_Group group2, MPI_Group *newgroup),Осуществляет создание новой группы newgroup как пересечения групп group1 и group2.
- где group1 - первая группа; group2 - вторая группа; newgroup - разность групп.
int MPI_Group_difference (MPI_Group group1, MPI_Group group2, MPI_Group *newgroup),Осуществляет создание новой группы newgroup как разности групп group1 и group2.
- где group - группа; size - число процессов в группе.
int MPI_Group_size (MPI_Group group, int *size),
Осуществляет получение количества процессов в группе.
- где group - группа; size - ранг процесса в группе.
int MPI_Group_rank (MPI_Group group, int *rank),
Осуществляет получение ранга текущего процесса в группе.
- где group - группа, подлежащая удалению.
int MPI_Group_free (MPI_Group *group),Осуществляет удаление группы после завершения ее использования.
- где oldcom - существующий коммуникатор, копия которого создается; newcom - новый коммуникатор.
int MPI_Comm_dup(MPI_Comm oldcom, MPI_comm *newcom),Осуществляет дублирование уже существующего коммуникатора.
- где oldcom - существующий коммуникатор; group - подмножество процессов коммуникатора oldcom; newcom - новый коммуникатор.
int MPI_comm_create(MPI_Comm oldcom, MPI_Group group, MPI_Comm *newcom),Осуществляет создание нового коммуникатора из подмножества процессов существующего коммуникатора.
- где oldcomm - исходный коммуникатор; split - номер коммуникатора, которому должен принадлежать процесс; key - порядок ранга процесса в создаваемом коммуникаторе; newcomm - создаваемый коммуникатор.
int MPI_Comm_split(MPI_Comm oldcomm, int split, int key, MPI_Comm *newcomm),
Осуществляет одновременное создание нескольких коммуникаторов. Создание коммуникаторов относится к коллективным операциям, поэтому вызов функции MPI_Comm_split должен быть выполнен в каждом процессе коммуникатора oldcomm. В результате выполнения функции процессы разделяются на непересекающиеся группы с одинаковыми значениями параметра split. На основе сформированных групп создается набор коммуникаторов. Для того чтобы указать, что процесс не должен входить ни в один из создаваемых коммуникаторов, необходимо воспользоваться константой MPI_UNDEFINED в качестве значения параметра split. При создании коммуникаторов для рангов процессов в новом коммуникаторе выбирается такой порядок нумерации, чтобы он соответствовал порядку значений параметров key (процесс с большим значением параметра key получает больший ранг, процессы с одинаковым значением параметра key сохраняют свою относительную нумерацию).
- где comm - коммуникатор, подлежащий удалению.
int MPI_Comm_free (MPI_Comm *comm),Используется для удаления коммуникатора.
- где oldcomm - исходный коммуникатор; ndims - размерность декартовой решетки; dims - массив длины ndims, задает количество процессов в каждом измерении решетки; periods - массив длины ndims, определяет, является ли решетка периодической вдоль каждого измерения; reorder - параметр допустимости изменения нумерации процессов; cartcomm - создаваемый коммуникатор с декартовой топологией процессов.
int MPI_Cart_create (MPI_Comm oldcomm, int ndims, int *dims, int *periods, int reorder, MPI_Comm *cartcomm),
Используется для создания декартовой топологии (решетки). Операция создания топологии является коллективной и, тем самым, должна выполняться всеми процессами исходного коммуникатора.
- где comm - коммуникатор с топологией решетки; rank - ранг процесса, для которого определяются декартовы координаты; ndims - размерность решетки; coords - возвращаемые функцией декартовы координаты процесса.
int MPI_Cart_coords (MPI_Comm comm, int rank, int ndims, int *coords),
Используется для определения декартовых координат процесса по его рангу.
- где comm - коммуникатор с топологией решетки; coords - декартовы координаты процесса; rank - возвращаемый функцией ранг процесса.
int MPI_Cart_rank (MPI_Comm comm, int *coords, int *rank),
Используется для определения ранга процесса по его декартовым координатам.
- где comm - исходный коммуникатор с топологией решетки; subdims - массив для указания, какие измерения должны остаться в создаваемой подрешетке; newcomm - создаваемый коммуникатор с подрешеткой.
int MPI_Cart_sub (MPI_Comm comm, int *subdims, MPI_Comm *newcomm),
Осуществляет разбиение решетки на подрешетки меньшей размерности. Операция создания подрешеток также является коллективной и, тем самым, должна выполняться всеми процессами исходного коммуникатора. В ходе своего выполнения функция MPI_Cart_sub определяет коммуникаторы для каждого сочетания координат фиксированных измерений исходной решетки.
- где comm - коммуникатор с топологией решетки; dir - номер измерения, по которому выполняется сдвиг; disp - величина сдвига (при отрицательных значениях сдвиг производится к началу измерения); source - ранг процесса, от которого должны быть получены данные; dst - ранг процесса, которому должны быть отправлены данные.
int MPI_Cart_shift (MPI_Comm comm, int dir, int disp, int *source, int *dst),
Обеспечивает получение рангов процессов, с которыми текущий процесс (процесс, вызвавший функцию MPI_Cart_shift) должен выполнить обмен данными.
- где oldcom - исходный коммуникатор; nnodes - количество вершин графа; index - количество исходящих дуг для каждой вершины; edges - последовательный список дуг графа; reorder - параметр допустимости изменения нумерации процессов; graphcom - создаваемый коммуникатор с топологией типа граф.
int MPI_Graph_create (MPI_Comm oldcom, int nnodes, int *index, int *edges, int reorder, MPI_Comm *graphcom),
Используется для создания коммуникатора с топологией типа граф. Операция создания топологии является коллективной и, тем самым, должна выполняться всеми процессами исходного коммуникатора.
- где comm - коммуникатор с топологией типа граф; rank - ранг процесса в коммуникаторе; nneighbors - количество соседних процессов.
int MPI_Graph_neighbors_count (MPI_Comm comm, int rank, int *nneighbors),
Определяет количество соседних процессов, в которых от проверяемого процесса есть выходящие дуги.
- где comm - коммуникатор с топологией типа граф; rank - ранг процесса в коммуникаторе; mneighbors - размер массива neighbors; neighbors - ранги соседних в графе процессов.
int MPI_Graph_neighbors (MPI_Comm comm, int rank, int mneighbors, int *neighbors),
Используется для получения рангов соседних вершин.