На этом шаге мы рассмотрим встроенные функции работы со строками.
На данном шаге мы рассмотрим некоторые встроенные функции языка Perl, предназначенные для работы со строками текста. Часть из них использует рассмотренное выше понятие регулярного выражения.
- Функция chop(). Общий вид:
удаляет последний символ из всех элементов списка list, возвращает последний удаленный символ. Список может состоять из одной строки. Если аргумент отсутствует, операция удаления последнего символа применяется к встроенной переменной $_. Обычно применяется для удаления завершающего символа перевода строки, остающегося при считывании строки из входного файла.
chop ([list])
- Функция length(). Общий вид:
возвращает длину скалярной величины EXPR в байтах.
length EXPRПриведем пример использования функций chop() и length().
Текст этого примера можно взять здесь.#! perl -w $input = <STDIN>; $Len = length($input); print "Строка до удаления последнего символа: $input\n"; print "Длина строки до удаления последнего символа: $Len\n"; $Chopped = chop($input); $Len = length($input); print "Строка после удаления последнего символа: $input\n"; print "Длина строки после удаления последнего символа: $Len\n"; print "Удаленный символ: <$Chopped>\n";Если после запуска данного скрипта ввести строку "qwerty", то вывод будет иметь вид:
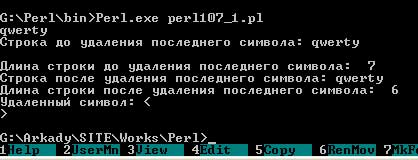
Рис.1. Результат работы приложенияПоследним символом, удаленным функцией chop(), является символ новой строки, сохраненный в переменной $Chopped. При выводе он вызывает переход на следующую строку, поэтому в данном выводе третья строка - пустая. В последней операции print вывод осуществляется в две строки, так как переменная $Сhopped содержит символ новой строки.
- Функции lс(), uc(), lcfirst(), ucfirst() предназначены для преобразования строчных букв в прописные и наоборот.
- Функция lc EXPR возвращает выражение, полученное из выражения EXPR преобразованием всех символов в строчные.
- Функция uc EXPR возвращает выражение, полученное из выражения EXPR преобразованием всех символов в прописные.
- Функция lcfirst EXPR возвращает выражение, полученное из выражения EXPR преобразованием первого символа в строчный.
- Функциия ucfirst EXPR возвращает выражение, полученное из выражения EXPR преобразованием первого символа в прописной.
Приведем пример использования этих функций.
Текст этого примера можно взять здесь.#! perl -w print "\nф-ция uc() преобразует ",$s="upper case"," в ",uc $s; print "\nФ-ция ucfirst() преобразует ",$s="uPPER CASE"," в ",ucfirst $s; print "\nФ-ция lс() преобразует ", $s="LOWER CASE"," в ",lc $s; print "\nФ-ция lcfirst() преобразует ",$s="Lower case"," в ",lcfirst $s;В результате выполнения данного скрипта будут напечатаны строки:
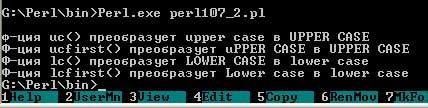
Рис.2. Результат работы скрипта - Функция join(). Общий вид:
join EXPR, LISTОбъединяет отдельные строки списка LIST в одну, используя в качестве разделителя строк значение выражения EXPR, и возвращает эту строку.
- Функция split(). Общий вид:
split [/PATTERN/ [, EXPR[, LIMIT]]]Разбивает строку EXPR на отдельные строки, используя в качестве разделителя образец, задаваемый регулярным выражением PATTERN. В списковом контексте возвращает массив полученных строк, в скалярном контексте - их число. Если функция split() вызывается в скалярном контексте, выделяемые строки помещаются в предопределенный массив @_. Об этом не следует забывать, так как массив @_ обычно используется для передачи параметров в подпрограмму, и обращение к функции split() неявно в скалярном контексте эти параметры уничтожит.
Если присутствует параметр LIMIT, то он задает максимальное количество строк, на которое может быть разбита исходная строка. Отрицательное значение параметра LIMIT трактуется как произвольно большое положительное число.
Если параметр EXPR опущен, разбивается строка $_. Если отсутствует также и параметр PATTERN, то в качестве разделителей полей используются пробельные символы после пропуска всех начальных пробельных символов (что соответствует заданию образца в виде /\s+/). К пробельным символам относятся пробел (space), символ табуляции (tab), возврат каретки (carriage return), символ перевода строки (line feed) и символ перевода страницы (form feed).
Замечание. Предопределенная глобальная переменная $_ служит для обозначения используемой по умолчанию области ввода и поиска по образцу. Обычно мы осуществляем ввод при помощи операции "<>" ("ромб"). Внутри угловых скобок о может стоять дескриптор файла ввода, например, <STDIN>. Если дескриптор файла отсутствует, то в качестве файлов ввода используются файлы, переданные программе Perl в качестве аргументов командной строки. Пусть, например, программа содержится в файле script.pl.#! perl -w while (<>) { print; }Программа вызвана следующим образом:
script.pl file1 file2 file3Тогда операция <> будет считывать строки сначала из файла file1, затем из файла file2 и, наконец, из файла file3. Если в командной строке файлы не указаны, то в качестве файла ввода будет использован стандартный ввод. Только в случае, когда условное выражение оператора while состоит из единственной операции "ромб", вводимое значение автоматически присваивается предопределенной переменной $_. Вот что означают слова о том, что переменная $_ применяется для обозначения используемой по умолчанию области ввода. Аналогично обстоит дело с поиском по образцу.
Приведем пример использования функций split() и join().
Текст этого примера можно взять здесь.#! perl -w while (<>) { chop; print "Число полей во входной строке '$_' равно ", $n=split; print "\nВходная строка разбита на строки :\n"; foreach $i (@_) { print $i."\n"; } print "Объединение списка строк в одну строку через '+':\n"; $joined = join "+",@_; print "$joined\n"; }В результате применения операции ввода <> внутри условного выражения оператора while вводимая строка будет присвоена переменной $_. Функция chop() без параметров применяется к переменной $_. В операции print вторым операндом является выражение $n=split, в котором функция split вызывается в скалярном контексте и без параметров. Поэтому она применяется по умолчанию к переменной $_. В качестве разделителей полей по умолчанию используется множество пробельных символов, а результат помещается в масссив @_. Затем к массиву @_ применяется функция join(), объединяющая строки-элементы массива в одну строку.
Если ввести строку "one two three", то вывод будет иметь вид:
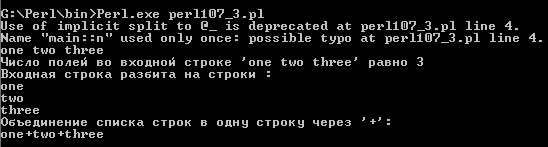
Рис.3. Результат работы скрипта - Функция index(). Общий вид:
index STR, SUBSTR [, POSITION]Находит первое, начиная с позиции POSITION, вхождение подстроки SUBSTR в строку STR, и возвращает найденную позицию. Если параметр POSITION не задан, по умолчанию принимается значение POSITION = $[. Если подстрока SUBSTR не найдена, возвращается значение $[ - 1.
Замечание. Предопределенная переменная $[ содержит индекс первого элемента в массиве и первого элемента в строке. По умолчанию ее значение равно 0. В принципе его можно изменить, но делать это не рекомендуется. Таким образом, по умолчанию значение параметра POSITION полагается равным 0, а функция index возвращает -1, если не найдена подстрока SUBSTR.
- Функция rindex(). Общий вид:
rindex STR, SUBSTR, POSITION
Находит последнее, ограниченное справа позицией POSITION, вхождение подстроки SUBSTR в строку STR, и возвращает найденную позицию. Если подстрока SUBSTR не найдена, возвращается значение $[ - 1.
Приведем пример использования функций index() и rindex().
Текст этого примера можно взять здесь.#! perl -w $STR = "Этот безумный, безумный, безумный, безумный мир!"; $SUBSTR = "безумный"; $POS = 7; print "Индекс первого символа строки по умолчанию равен $[\n"; print "Позиция первого вхождения подстроки '$SUBSTR' в строку '$STR' = ",index($STR, $SUBSTR), "\n"; print "Позиция первого после позиции $POS вхождения подстроки '$SUBSTR' в строку '$STR' = ",index($STR, $SUBSTR, $POS), "\n"; print "Позиция последнего вхождения подстроки '$SUBSTR' в строку '$STR' = ",rindex($STR, $SUBSTR), "\n"; print "Позиция последнего перед позицией $POS вхождения подстроки '$SUBSTR' в строку '$STR' = ",rindex($STR, $SUBSTR, $POS), "\n"; $[=2; print "\nИндекс первого символа строки по умолчанию изменен на $[\n"; print "Позиция первого вхождения подстроки '$SUBSTR' в строку '$STR' = ",index($STR, $SUBSTR), "\n"; print "Позиция первого после позиции $POS вхождения подстроки '$SUBSTR' в строку '$STR' = ",index($STR, $SUBSTR, $POS), "\n"; print "Позиция последнего вхождения подстроки '$SUBSTR' в строку '$STR' = ",rindex($STR, $SUBSTR), "\n"; print "Позиция последнего перед позицией $POS вхождения подстроки '$SUBSTR' в строку '$STR' = ",rindex($STR, $SUBSTR, $POS), "\n";В результате выполнения скрипта будут выведены следующие строки:
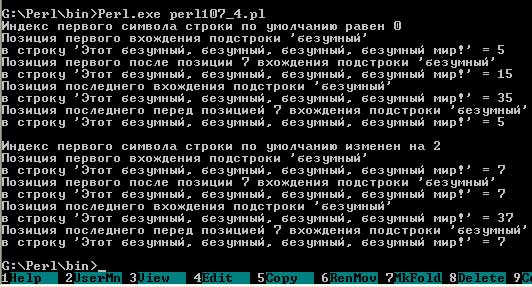
Рис.4. Результат рабты скрипта - Функция substr(). Общий вид:
substr EXPR, OFFSET [, LENGTH [, REPLACEMENT ]]Извлекает из выражения EXPR подстроку и возвращает ее. Возвращаемая подстрока состоит из LENGTH символов, расположенных справа от позиции OFFSET. Если параметр LENGTH опущен, возвращается вся оставшаяся часть выражения EXPR. Если параметр LENGTH отрицательный, его абсолютное значение задает количество символов от конца строки, не включаемых в результирующую подстроку. Если параметр OFFSET имеет отрицательное значение, смещение отсчитывается с конца строки. Функция substr() может стоять в левой части операции присваивания. Например, в результате выполнения операторов
переменная $Str получит значение "Язык Perl". Тот же результат будет достигнут, если указать параметр REPLACEMENT, значение которого будет подставлено в EXPR вместо выделенной подстроки. Сама подстрока в этом случае возвращается в качестве значения функции substr().$Str = "Язык Pascal"; substr($Str, 5,6) = "Perl";Приведем пример использования функции substr().
Текст этого примера можно взять здесь.#! perl -w # Исходная строка $Str = "Карл у Клары украл кораллы"; $Offset = 13; print "Исходная строка:'$Str'\n"; # Смещение 13, длина подстроки не задана $Substr = substr $Str, $Offset; print "Смещение $Offset, длина подстроки не задана, результат:\n"; print "$Substr\n"; # Смещение 13, длина подстроки +5 $Substr = substr $Str, $Offset, 5; print "Смещение $Offset, длина подстроки +5, результат:\n"; print "$Substr\n"; # Смещение 13, длина подстроки -1 $Substr = substr $Str, $Offset, -1; print "Смещение $Offset, длина подстроки -1, результат:\n"; print "$Substr\n"; # Отрицательное смещение -7, длина подстроки +7 $Offset = -7; $Substr = substr $Str, $Offset, 7; print "Отрицательное смещение $Offset, длина подстроки +7, результат:\n"; print "$Substr\n"; # Отрицательное смещение -7, длина подстроки -1 $Substr = substr $Str, $Offset, -1; print "Отрицательное смещение $Offset, длина подстроки -1, результат:\n"; print "$Substr\n"; # Замена подстроки $Repl = "бокалы"; $Substr = substr $Str, $Offset, 7, $Repl; print "В строке '$Str' слово '$Repl' заменяет слово '$Substr'\n";
Вывод выглядит следующим образом:
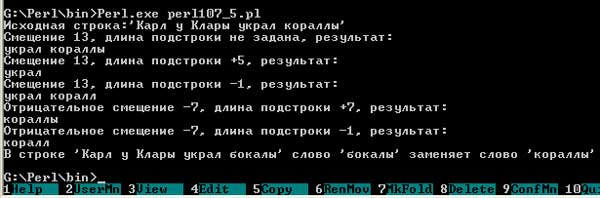
Рис.5. Результат выполнения скрипта - Функция eval(). Общий вид:
eval EXPRРассматривает параметр EXPR как текст Perl-программы, компилирует его и, если не обнаруживает ошибок, выполняет в текущем вычислительном окружении. Если параметр EXPR отсутствует, вместо него по умолчанию используется глобальная переменная $_. Компиляция программного кода EXPR осуществляется при каждом вызове функции eval() во время выполнения основной программы. Если выполнение мини-программы EXPR завершается успешно, функция eval() возвращает значение последнего выражения, вычисленного внутри EXPR. Если код EXPR содержит синтаксические ошибки, или обращение к функции die(), или возникла ошибка во время выполнения EXPR, то в специальную переменную $@ помещается сообщение об ошибке, а функция eval() возвращает неопределенное значение.
Замечания.- Если скалярной переменной не присвоено никакое допустимое значение (число, строка или ссылка), то говорят, что она имеет неопределенное значение. Неопределенные значения возникают в различных случаях, например, при попытке чтения данных после достижения конца файла или в результате системных ошибок. Неопределенное значение представляется пустой строкой "", но его следует отличать от определенного значения, равного "". Например, в результате выполнения операторов
переменные $а и $е будут иметь неопределенное значение, а переменная $b - определенное значение "". Для того чтобы определить, имеет выражение EXPR определенное значение или нет, существует функция defined EXPR, возвращающая соответствующее булевское значение. В данном примере результатом выполнения будет вывод единственной строки$е = eval '$а = 1/0'; # деление на 0 $b = ""; print "a= $a\n" if defined $a; print "e= $e\n" if defined $e; print "b= $b\n" if defined $b;b=- Специальная переменная $@ служит для запоминания сообщения об ошибке, возникшей при последнем обращении к функции eval().
- Существует вторая форма функции eval()
где BLOCK представляет собой блок - последовательность операторов, заключенную в фигурные скобки. Вторая форма отличается от первой тем, что синтаксический анализ параметра BLOCK осуществляется всего один раз - во время компиляции основной программы, содержащей обращение к функции eval(). Таким образом, если параметр BLOCK содержит синтаксические ошибки, то они обнаружатся на этапе компиляции основной программы. При использовании первой формы синтаксические ошибки обнаружатся только во время выполнения.eval BLOCK,
Основным применением функции eval() является перехватывание исключений. Исключением мы называем ошибку, возникающую при выполнении программы, когда нормальная последовательность выполнения прерывается (например, при делении на нуль). Обычной реакцией на исключение является аварийное завершение программы. Язык Perl предоставляет возможность перехватывать исключения без аварийного выхода. Если исключение возникло в основной программе, то программа завершается. Если ошибка возникла внутри мини-программы функции eval(), то аварийно завершается только функция eval(), а основная программа продолжает выполняться и может реагировать на возникшую ошибку, сообщение о которой ей доступно через переменную $@.
В следующем примере функция eval() применяется для перехватывания ошибки, связанной с делением на 0 при вычислении функции ctg(x). Используются встроенные функции sin, cos и warn. Последняя функция осуществляет вывод сообщения, задаваемого ее аргументом, на стандартное устройство вывода ошибок STDERR.
Текст этого примера можно взять здесь.#! perl -w $fi = 0.314159265358979; $f = '$ctg = cos ($x) /sin($x) ' ; for $i (0..10) { $x = $i*$fi; eval $f; print "x= $x ctg (x) = $ctg\n" if defined $ctg; warn "x= $x ", $@ if not defined $ctg; };Вывод программы выглядит следующим образом:
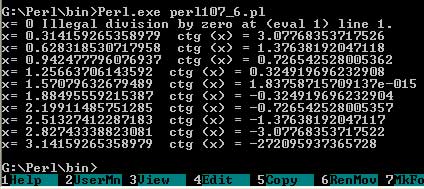
Рис.6. Результат работы скрипта
Замечание. Иногда бывает полезно искусственно вызвать исключительную ситуацию. Для этого можно воспользоваться функцией die() LIST. Назначение функции die() - генерировать исключения. Если функция die() вызывается в основной программе вне функции eval(), то она осуществляет аварийное завершение основной программы и выводит сообщение об ошибке LIST на стандартное устройство вывода ошибок STDERR. Если она вызывается внутри функции eval(), то осуществляет аварийное завершение eval() и помещает сообщение об ошибке в специальную переменную $@.
- Функция роs(). Общий вид:
роs [$SCALAR]Возвращает позицию, в которой завершился последний глобальный поиск $SCALAR=~m/.../g, осуществленный в строке, задаваемой переменной $SCALAR. Возвращаемое значение равно числу length ($') + length ($&). Следующий глобальный поиск m/.../g в данной строке начнется именно с этой позиции.
Если аргумент $SCALAR отсутствует, возвращается позиция завершения последнего глобального поиска, осуществленного в строке $_.
Приведем пример использования функции роs().
Текст этого примера можно взять здесь.#! perl -w $words = "one two three four"; while ($words =~ m/\w+/g) { print "pos=",pos($words)," length(\$`)=", length ($`), " length(\$&)=",length($&),"\n"; };В результате выполнения данного скрипта будут выведены номера позиций, соответствующих окончаниям слов в строке $words:
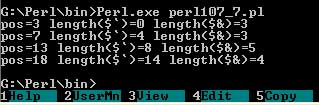
Рис.7. Результат работы скриптаФункцию pos() можно использовать в левой части операции присваивания для изменения начальной позиции следующего поиска:
Текст этого примера можно взять здесь.#! perl -w # изменение начальной позиции для последующего поиска $words = "one two three four"; pos $words = 4; while ($words =~ m/\w+/g) { print pos $words, "\n"; };
В последнем случае поиск слов начнется со второго слова, и будут выведены номера позиций 7, 13 и 18.
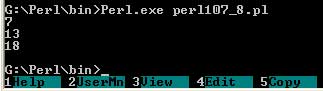
Рис.8. Результат работы скрипта - Функция quotemeta(). Общий вид:
quotemeta [EXPR]Возвращает строку EXPR, в которой все символы, кроме алфавитно-цифровых символов и символа подчеркивания "_", экранированы символом "\". Например, в результате выполнения
будет выведена строкаprint quotemeta "*****", "\n";\*\*\*\*\*Если аргумент EXPR отсутствует, вместо него используется переменная $_.
На следующем шаге мы приведем примеры использования рассмотренных конструкций.
