На этом шаге мы рассмотрим правила задания регулярный выражений.
Регулярные выражения предназначены для выполнения в строке сложного поиска или замены. В языке Python использовать регулярные выражения позволяет модуль re. Прежде чем задействовать функции из этого модуля, необходимо подключить модуль с помощью инструкции:
import re
Синтаксис регулярных выражений
Создать откомпилированный шаблон регулярного выражения позволяет функция compile(). Функция имеет следующий формат:
<Шаблон> = re.compile(<Регулярное выражение>[, <Модификатор>])
В параметре Модификатор могут быть указаны следующие флаги (или их комбинация через оператор |):
- L или LOCALE - учитываются настройки текущей локали;
- I или IGNORECASE - поиск без учета регистра. Пример:
>>> import re >>> p = re.compile(r'^[а-яё]+$', re.I | re.U) >>> print("Найдено" if p.search("ФБВГДЕЁ") else "Нет") Найдено >>> p = re.compile(r'^[а-яё]+$', re.U) >>> print("Найдено" if p.search("ФБВГДЕЁ") else "Нет") Нет
- M или MULTILINE - поиск в строке, состоящей из нескольких подстрок, разделенных символом новой строки ("\n"). Символ ^ соответствует привязке к началу каждой подстроки, а
символ $ - позиции перед символом перевода строки;
- S или DOTALL - метасимвол "точка" по умолчанию соответствует любому символу, кроме символа перевода строки ("\n"). Символу перевода строки метасимвол "точка" будет соответствовать в
присутствии дополнительного модификатора. Символ ^ соответствует привязке к началу всей строки, а символ $ - привязке к концу всей строки. Пример:
>>> p = re.compile(r'^.$') >>> print("Найдено" if p.search("\n") else "Нет") Нет >>> p = re.compile(r'^.$', re.M) >>> print("Найдено" if p.search("\n") else "Нет") Нет >>> p = re.compile(r'^.$', re.S) >>> print("Найдено" if p.search("\n") else "Нет") Найдено
- X или VERBOSE - если флаг указан, то пробелы и символы перевода строки будут проигнорированы. Внутри регулярного выражения можно использовать и комментарии. Пример:
>>> p = re.compile(r'''^# Привязка к началу строки [0-9]+ # строка должна содержать одну цифру (или более) $ # Привязка к концу строки ''', re.X | re.S) >>> print("Найдено" if p.search("1234567890") else "Нет") Найдено >>> print("Найдено" if p.search("abcd123ef") else "Нет") Нет
- А или ASCII - классы \w, \W, \b, \B, \d, \D, \s и \S будут соответствовать символам в кодировке ASCII (по умолчанию перечисленные классы соответствуют Unicode-символам).
Примечание. Флаги U и UNICODE, включающие режим соответствия Unicode-символам классов \w, \W, \b, \B, \d, \D, \s и \S, сохранены в Python 3 лишь для совместимости с ранними версиями этого языка и никакого влияния на обработку регулярных выражений не оказывают.
Как видно из примеров, перед всеми строками, содержащими регулярные выражения, указан модификатор r. Иными словами, мы используем неформатированные строки. Если модификатор не указать, то все слеши необходимо экранировать. Например, строку:
р = re.compile(r"^\w+$")
р = re.compile("^\\w+$")
Внутри регулярного выражения символы ., ^, $, *, +, ?, {, }, [, ], |, \, ( и ) имеют специальное значение. Если эти символы должны трактоваться как есть, их следует экранировать с помощью слеша. Некоторые специальные символы теряют свое особое значение, если их разместить внутри квадратных скобок, - в этом случае экранировать их не нужно. Например, как уже было отмечено ранее, метасимвол "точка" по умолчанию соответствует любому символу, кроме символа перевода строки. Если необходимо найти именно точку, то перед точкой нужно указать символ \ или разместить точку внутри квадратных скобок: [ . ]. Продемонстрируем это на примере проверки правильности введенной даты:
# -*- coding: utf-8 -*- import re # Подключаем модуль d = "20,01.2017" # Вместо точки указана запятая p = re.compile(r"^[0-3][0-9].[01][0-9].[12][09][0-9][0-9]$") # Символ "\" не указан перед точкой if p.search(d): print("Дата введена правильно") else: print("Дата введена неправильно") # Так как точка означает любой символ, # выведет: Дата введена правильно p = re.compile(r"^[0-3][0-9]\.[01][0-9]\.[12][09][0-9][0-9]$") # Символ "\" указан перед точкой if p.search(d): print("Дата введена правильно") else: print("Дата введена неправильно") # Так как перед точкой указан символ "\", # выведет: Дата введена неправильно p = re.compile(r"^[0-3][0-9][.][01][0-9][.][12][09][0-9][0-9]$") # Точка внутри квадратных скобок if p.search(d): print("Дата введена правильно") else: print("Дата введена неправильно") # Выведет: Дата введена неправильно input()
Результат работы приложения приведен на рисунке 1:
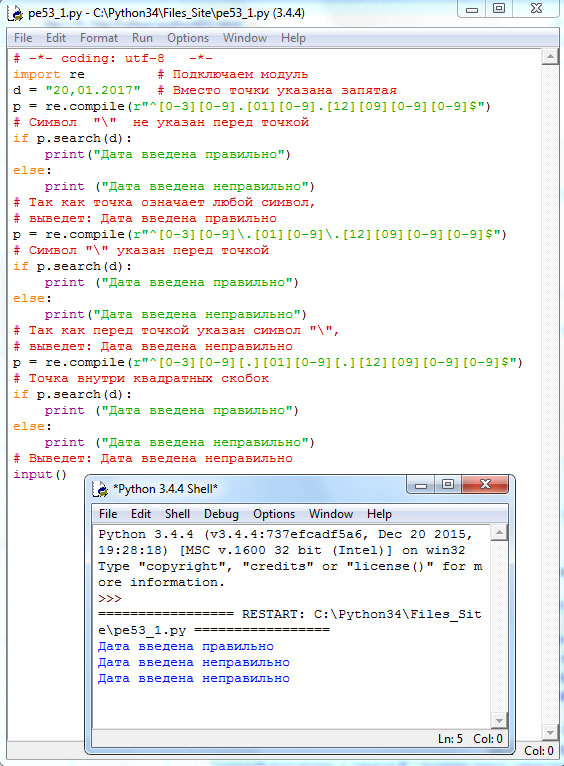
Рис.1. Результат работы приложения
В этом примере мы осуществляли привязку к началу и концу строки с помощью следующих метасимволов:
- ^ - привязка к началу строки или подстроки. Она зависит от флагов M (или MULTILINE) и S (или DOTALL);
- $ - привязка к концу строки или подстроки. Она зависит от флагов M (или MULTILINE) и S (или DOTALL);
- \А - привязка к началу строки (не зависит от модификатора);
- \Z - привязка к концу строки (не зависит от модификатора).
Если в параметре Модификатор указан флаг M (или MULTILINE), то поиск производится в строке, состоящей из нескольких подстрок, разделенных символом новой строки (\n). В этом случае символ ^ соответствует привязке к началу каждой подстроки, а символ $ - позиции перед символом перевода строки:
>>> p = re.compile(r'^.+$') # Точка не соответствует \n >>> p.findall("str1\nstr2\nstr3") # Ничего не найдено [] >>> p = re.compile(r'^.+$', re.S) # Теперь точка соответствует \n >>> p.findall("str1\nstr2\nstr3") # Строка полностью соответствует ['str1\nstr2\nstr3'] >>> p = re.compile(r'^.+$', re.M) # Многострочный режим >>> p.findall("str1\nstr2\nstr3") # Получили каждую подстроку ['str1', 'str2', 'str3']
Привязку к началу и концу строки следует использовать, если строка должна полностью соответствовать регулярному выражению. Например, для проверки, содержит ли строка число:
# -*- coding: utf-8 -*- import re # Подключаем модуль p = re.compile(r"^[0-9]+$", re.S) if p.search("245"): print("Число") # Выведет: Число else: print("He число") if p.search("Строка245"): print("Число") else: print("He число") # Выведет: Не число input()
Результат работы приложения приведен на рисунке 2:
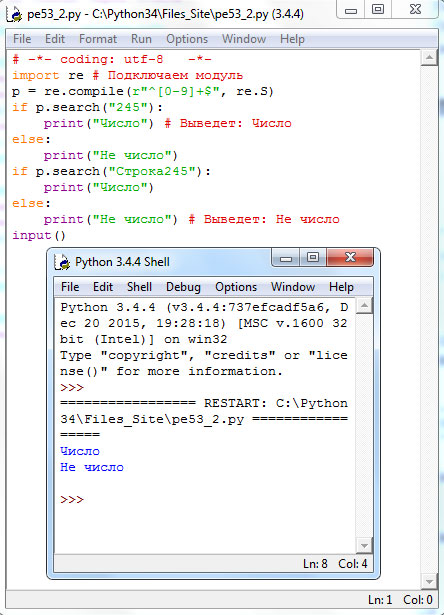
Рис.2. Результат работы приложения
Если убрать привязку к началу и концу строки, то любая строка, содержащая хотя бы одну цифру, будет распознана как число:
# -*- coding: utf-8 -*- import re # Подключаем модуль p = re.compile(r"[0-9]+$", re.S) if p.search("Строка245"): print("Число") # Выведет: Число else: print("He число") input()
Результат работы приложения приведен на рисунке 3:
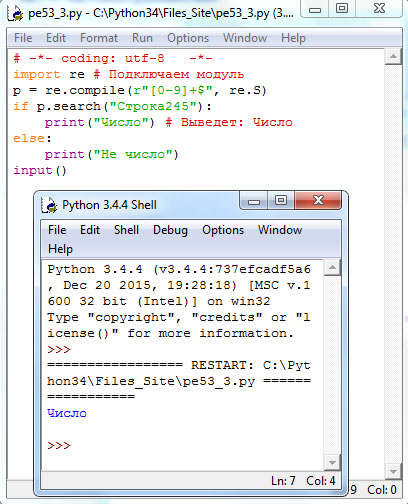
Рис.3. Результат работы приложения
Кроме того, можно указать привязку только к началу или только к концу строки:
# -*- coding: utf-8 -*- import re # Подключаем модуль p = re.compile(r"[0-9]+$", re.S) if p.search("Строка245"): print("Есть число в конце строки") else: print("Нет числа в конце строки") # Выведет: Есть число в конце строки p = re.compile(r"^[0-9]+", re.S) if p.search("Строка245"): print("Есть число в конце строки") else: print("Нет числа в конце строки") # Выведет: Нет числа в конце строки input()
Результат работы приложения приведен на рисунке 4:
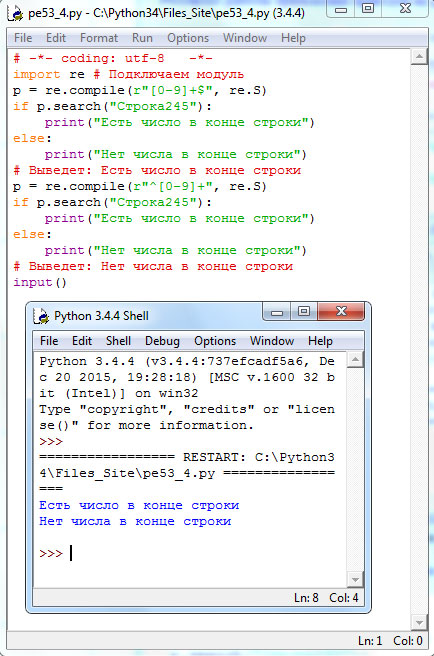
Рис.4. Результат работы приложения
На следующем шаге мы закончим изучение этого вопроса.
