На этом шаге мы рассмотрим особенности изменения записей.
Для добавления записей в таблицу используется инструкция INSERT. Формат инструкции:
INSERT [OR <Алгоритм>] INTO [<Название базы данных>.] <Название таблицы> [(<Поле1>, <Поле2>, ...)] VALUES (<Значение1>, <Значение2>, ...) | DEFAULT VALUES;
Необязательный параметр OR <Алгоритм> задает алгоритм обработки ошибок (ROLLBACK, ABORT, FAIL, IGNORE или REPLACE). Все эти алгоритмы мы уже рассматривали в предыдущем шаге. После названия таблицы внутри круглых скобок могут быть перечислены поля, которым будут присваиваться значения, указанные в круглых скобках после ключевого слова VALUES. Количество параметров должно совпадать. Если в таблице существуют поля, которым в инструкции INSERT не присваивается значение, то они получат значения по умолчанию. Если список полей не указан, то значения задаются в том порядке, в котором поля перечислены в инструкции CREATE TABLE.
Вместо конструкции VALUES (<Список полей>) можно указать DEFAULT VALUES. В этом случае будет создана новая запись, все поля которой получат значения по умолчанию или NULL, если таковые не были заданы при создании таблицы.
Создадим таблицы user (данные о пользователе), rubr (название рубрики) и site (описание сайта):
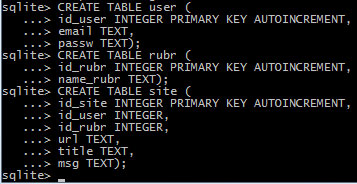
Рис.1. Создание таблиц
Такая структура таблиц характерна для реляционных баз данных и позволяет избежать в таблицах дублирования данных - ведь одному пользователю может принадлежать несколько сайтов, а в одной рубрике можно зарегистрировать множество сайтов. Если в таблице site каждый раз указывать название рубрики, то при необходимости переименовать рубрику придется изменять названия во всех записях, где встречается старое название. Если же названия рубрик расположены в отдельной таблице, то изменить название можно будет только в одном месте, - все остальные записи будут связаны целочисленным идентификатором. Как получить данные сразу из нескольких таблиц, мы узнаем по мере изучения SQLite.
Теперь заполним таблицы связанными данными:
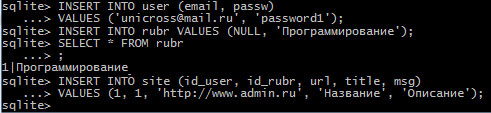
Рис.2. Заполнение таблиц
В первом примере перечислены только поля email и passw. Поскольку поле id_user не указано, то ему присваивается значение по умолчанию. В таблице user поле iduser объявлено как первичный ключ, поэтому туда будет вставлено значение, на единицу большее максимального значения в поле. Такого же эффекта можно достичь, если в качестве значения передать NULL. Это демонстрируется во втором примере. В третьем примере вставляется запись в таблицу site. Поля iduser и id_rubr в этой таблице должны содержать идентификаторы соответствующих записей из таблиц user и rubr. Поэтому вначале мы делаем запросы на выборку данных и смотрим, какой идентификатор был присвоен вставленным записям в таблицы user и rubr. Обратите внимание на то, что мы опять указываем названия полей явным образом. Хотя перечислять поля и необязательно, но лучше так делать всегда. Тогда в дальнейшем можно будет изменить структуру таблицы (например, добавить поле) без необходимости изменять все SQL-запросы - достаточно будет для нового поля указать значение по умолчанию, а все старые запросы останутся по-прежнему рабочими.
Во всех этих примерах строковые значения указываются внутри одинарных кавычек. Однако бывают ситуации, когда внутри строки уже содержится одинарная кавычка. Попытка вставить такую строку приведет к ошибке:

Рис.3. Ошибочная ситуация: апостроф внутри апострофов
Чтобы избежать этой ошибки, можно заключить строку в двойные кавычки или удвоить каждую одинарную кавычку внутри строки:

Рис.4. Вариант исправления
Если предпринимается попытка вставить запись, а в таблице уже есть запись с таким же идентификатором (или значение индекса UNIQUE не уникально), то такая SQL-команда приводит к ошибке. Когда необходимо, чтобы имеющиеся неуникальные записи обновлялись без вывода сообщения об ошибке, можно указать алгоритм обработки ошибок REPLACE после ключевого слова OR. Заменим название рубрики с идентификатором 2:
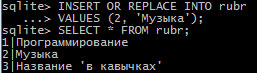
Рис.5. Изменение названия рубрики
Вместо алгоритма REPLACE можно использовать инструкцию REPLACE INTO. Инструкция имеет следующий формат:
REPLACE INTO [<Название базы данных>.]<Название таблицы> [ <Поле1>, <Поле2>, ...)] VALUES (<Значение1>, <Значение2>, ...) | DEFAULT VALUES;
Заменим название рубрики с идентификатором 3:
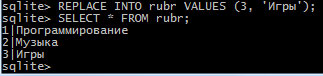
Рис.6. Изменение названия рубрики с идентификатором 3
На следующем шаге мы рассмотрим обновление и удаление записей.
