На этом шаге мы узнаем, как с помощью конкатенации списков многократно копировать маленькие списки и объединить их в один большой для генерации циклических данных.
Общее описание
На сей раз мы работаем над маленьким программным проектом для больницы. Наша задача - мониторинг и визуализация статистики состояния здоровья пациентов путем отслеживания их сердечных циклов. Благодаря построению графиков данных сердечных циклов мы помогаем докторам и пациентам отслеживать возможные отклонения от этого цикла. Например, при заданном ряде измерений отдельного сердечного цикла, хранящихся в списке [62, 60, 62, 64, 68, 77, 80, 76, 71, 66, 61, 60, 62], необходимо получить визуализацию, подобную изображенной на рисунке 1.
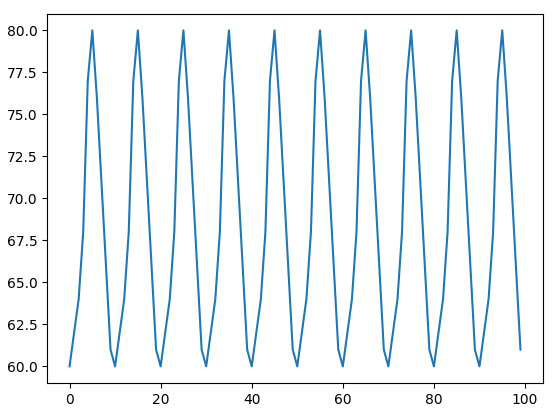
Рис.1. Визуализация ожидаемых сердечных циклов путем копирования избранных значений из списка измеренных данных
Проблема состоит в том, что первое и второе значения данных в нашем списке избыточны: [62, 60, 62, 64, 68, 77, 80, 76, 71, 66, 61, 60, 62]. Это удобно при построении графика одного сердечного цикла в качестве указания на то, что был визуализирован один полный цикл. Однако необходимо избавиться от этих избыточных данных, чтобы наши ожидаемые сердечные циклы не выглядели так, как на рисунке 2, при копировании одного и того же сердечного цикла.
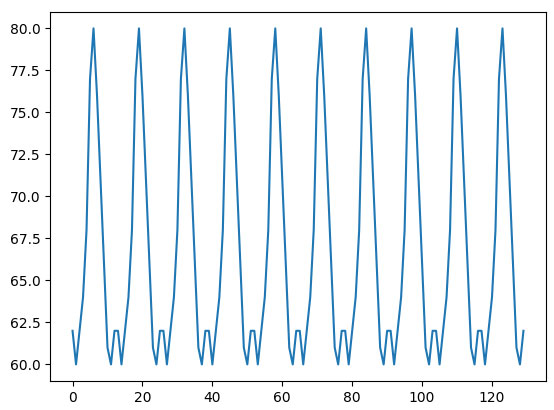
Рис.2. Визуализация ожидаемых сердечных циклов путем копирования всех значений из списка измеренных данных (без фильтрации избыточных данных)
Ясно, что нужно очистить исходный список, удалив из него избыточные два первых и два последних значения данных, то есть список [62, 60, 62, 64, 68, 77, 80, 76, 71, 66, 61, 60, 62] превращается в [60, 62, 64, 68, 77, 80, 76, 71, 66, 61].
Можно воспользоваться срезами в сочетании с новой возможностью Python - конкатенацией списков (list concatenation), создающей новый список путем конкатенации (то есть соединения) существующих списков. Например, операция [1, 2, 3] + [4, 5] создает новый список [1, 2, 3, 4, 5], не заменяя при этом существующие. При этом можно выполнить операцию * для многократной конкатенации одного и того же списка: например, операция [1, 2, 3] * 3 создает новый список [1, 2, 3, 1, 2, 3, 1, 2, 3].
Кроме того, можно использовать модуль matplotlib.pyplot для построения графика сгенерированных данных о сердечной деятельности. Функция
plot(data) библиотеки matplotlib ожидает на входе итерируемый аргумент data (итерируемый означает просто объект, по
которому можно проходить в цикле, например список) и использует его в качестве значений у для последующих типов данных на двумерном графике. Рассмотрим этот пример подробнее.
Код
У нас есть список целых чисел, отражающий измерения сердечного цикла. Сначала мы хотим очистить данные, удалив два первых и два последних значения из этого списка. Далее создаем новый список с ожидаемыми будущими значениями частоты сердечных сокращений, копируя сердечный цикл в экземпляры для будущего времени. Код приведен в примере 2.8.
Пример 2.8. Однострочное решение для предсказания частоты сердечных сокращений в различные моменты времени
# Зависимости import matplotlib.pyplot as plt ## Данные cardiac_cycle = [62, 60, 62, 64, 68, 77, 80, 76, 71, 66, 61, 60, 62] ## Однострочник expected_cycles = cardiac_cycle[1:-2] * 10 ## Результат plt.plot(expected_cycles) plt.show()
Далее вы узнаете результаты выполнения этого фрагмента кода.
Принцип работы
Приведенный однострочник работает в два этапа. Во-первых, мы очищаем данные с помощью среза с отрицательным аргументом конца, равным -2, чтобы срез включал в себя все элементы до правого конца, за исключением двух последних избыточных значений. Во-вторых, мы выполняем конкатенацию полученных значений данных десять раз с помощью оператора повтора *. В результате получаем список из 10 * 10 = 100 целых чисел, состоящих из конкатенаций данных о сердечной деятельности. И на построенном графике результата мы видим желаемую картину, показанную ранее на рисунке 1.
На следующем шаге мы рассмотрим поиск компаний, платящих меньше минимальной зарплаты, с помощью выражений-генераторов.
