На этом шаге рассмотрим синтаксический анализ формул в приложении Электронная таблица.
Функция evalExpression() возвращает значение выражения из ячейки электронной таблицы. Выражение состоит из одного или нескольких термов, разделенных знаками операций "+" или "-". Термы состоят из одного или нескольких факторов, разделенных знаками операций "*" или "/". Разбивая выражения на термы, а термы на факторы, мы обеспечиваем правильную последовательность выполнения операций.
Например, "2*C5+D6" является выражением, первый терм которого будет "2*С5", а второй терм - "D6". "2*С5" является термом, первый фактор которого будет "2", а второй фактор - "С5"; "D6" состоит из одного фактора - "D6".
Фактором может быть число ("2"), обозначение ячейки ("С5") или выражение в скобках, перед которым может стоять знак минуса. Блок-схема синтаксического анализа выражений электронной таблицы представлена на рис. 1.
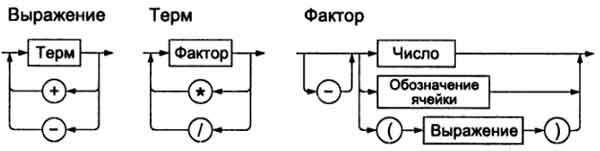
Рис.1. Блок-схема синтаксического анализа выражений электронной таблицы
Для каждого грамматического символа (выражение, терм и фактор) имеется соответствующая функция-член, которая выполняет его синтаксический анализ и структура которой очень хорошо отражает его грамматику. Построенные таким образом синтаксические анализаторы называются парсерами с рекурсивным спуском (recursive-descent parsers).
QVariant Cell::evalExpression(const QString &str, int &pos) const
{
//вызываем функцию evalTerm() для получения значения первого терма
QVariant result = evalTerm(str, pos);
while (str[pos] != QChar::Null) {
QChar op = str[pos];
/*если за ним не идет символ "+" или "-",
то выражение состоит из единственного терма, и мы возвращаем его значение
в качестве значения всего выражения*/
if (op != '+' && op != '-')
return result;
++pos;
//в противном случае, вызываем второй раз evalTerm()
QVariant term = evalTerm(str, pos);
/*после получения значений первых двух термов мы вычисляем
результат операции в зависимости от оператора. Если при оценке обоих
термов их значения будут иметь тип double, мы рассчитываем результат в
виде числа типа double; в противном случае мы устанавливаем результат на
значение Invalid*/
if (result.type() == QVariant::Double
&& term.type() == QVariant::Double) {
if (op == '+') {
result = result.toDouble() + term.toDouble();
} else {
result = result.toDouble() - term.toDouble();
}
} else {
result = Invalid;
}
}
return result;
}Продолжаем эту процедуру, пока не закончатся термы. Это даст правильный результат, потому что операции сложения и вычитания обладают свойством "ассоциативности слева" (left-associative); то есть "1-2-3" означает "(1-2)-3", а не "1-(2-3)".
Функция evalTerm() очень напоминает функцию evalExpression(), но в отличие от последней она имеет дело с операциями умножения и деления.
QVariant Cell::evalTerm(const QString &str, int &pos) const
{
QVariant result = evalFactor(str, pos);
while (str[pos] != QChar::Null) {
QChar op = str[pos];
if (op != '*' && op != '/')
return result;
++pos;
QVariant factor = evalFactor(str, pos);
if (result.type() == QVariant::Double
&& factor.type() == QVariant::Double) {
if (op == '*') {
result = result.toDouble() * factor.toDouble();
} else {
if (factor.toDouble() == 0.0) {
result = Invalid;
} else {
result = result.toDouble() / factor.toDouble();
}
}
} else {
result = Invalid;
}
}
return result;
}В функции evalTerm() необходимо учитывать одну тонкость, а именно, нельзя допускать деление на нуль, так как это приводит к ошибке на некоторых процессорах. Хотя не рекомендуется проверять равенство чисел с плавающей точкой из-за ошибки округления, можно спокойно делать проверку на равенство значению 0.0 для предотвращения деления на нуль.
Функция evalFactor():
QVariant Cell::evalFactor(const QString &str, int &pos) const
{
QVariant result;
bool negative = false;
//начинаем с проверки, не является ли фактор отрицательным
if (str[pos] == '-') {
negative = true;
++pos;
}
//проверяем наличие открытой скобки
if (str[pos] == '(') {
++pos;
/*если она имеется, анализируем значение внутри скобок как выражение,
вызывая evalExpression(). При анализе выражения в скобках evalExpression()
вызывает функцию evalTerm(), которая вызывает функцию evalFactor(),
которая вновь вызывает функцию evalExpression(). Именно в этом месте
осуществляется рекурсия при синтаксическом анализе*/
result = evalExpression(str, pos);
if (str[pos] != ')')
result = Invalid;
++pos;
} else {
/*если фактором не является вложенное выражение, мы выделяем
следующую лексему (token), и она должна задавать обозначение ячейки или
быть числом*/
QRegExp regExp("[A-Za-z][1-9][0-9]{0,2}");
QString token;
while (str[pos].isLetterOrNumber() || str[pos] == '.') {
token += str[pos];
++pos;
}
/*если эта лексема удовлетворяет регулярному выражению в переменной QRegExp,
мы считаем, что она является ссылкой на ячейку, и вызываем функцию value()
для этой ячейки. Ячейка может располагаться в любом месте в электронной
таблице, и она может ссылаться на другие ячейки. Такая зависимость не
вызывает проблемы и просто приводит к дополнительным вызовам функции
value() и к дополнительному синтаксическому анализу ячеек с признаком
"dirty" для перерасчета значений всех зависимых ячеек*/
if (regExp.exactMatch(token)) {
int column = token[0].toUpper().unicode() - 'A';
int row = token.mid(1).toInt() - 1;
Cell *c = static_cast<Cell *>(
tableWidget()->item(row, column));
if (c) {
result = c->value();
} else {
result = 0.0;
}
} else {
//если лексема не является ссылкой на ячейку, рассматриваем ее как число
bool ok;
result = token.toDouble(&ok);
if (!ok)
result = Invalid;
}
}
if (negative) {
if (result.type() == QVariant::Double) {
result = -result.toDouble();
} else {
result = Invalid;
}
}
return result;
}Что произойдет, если ячейка А1 содержит формулу "=А1"? Или если ячейка А1 содержит "=А2", а ячейка А2 содержит "=А1"? Хотя нами не написан специальный программный код для обнаружения бесконечных циклов в рекурсивных зависимостях, парсер прекрасно справится с этой ситуацией и возвратит недопустимое значение переменной типа QVariant. Это даст нужный результат, поскольку мы устанавливаем флажок cachelsDirty на значение false и переменную cachedValue на значение Invalid в функции value() перед вызовом evalExpression(). Если evalExpression() рекурсивно вызывает функцию value() для той же ячейки, она немедленно возвращает значение Invalid, и тогда все выражение принимает значение Invalid.
Теперь мы завершили программу синтаксического анализа формул. Ее можно легко модифицировать для обработки стандартных функций электронной таблицы, например "sum()" и "avg()", расширяя грамматическое определение фактора. Можно также легко расширить эту реализацию, обеспечив возможность выполнения операции "+" над строковыми операндами (для их конкатенации); это не потребует внесения изменений в грамматику.
Файлы приложения Электронная таблица можно взять здесь.
На следующем шаге приступим к рассмотрению большого раздела, посвященного компьютерной графике, и начнем с классов геометрии.
