На этом шаге рассмотрим типичные приемы моделирования исходного кода в UML.
При разработке программ на языке Java исходный код обычно сохраняется в файлах с расширением .java. Программы, написанные на C++, обычно хранят исходный код в заголовочных файлах с расширением .h и файлах реализации с расширением .cpp. При использовании языка IDL для разработки приложений COM+ или CORBA, единственный, с точки зрения проектирования, интерфейс распадается на четыре исходных файла: сам интерфейс, клиентский заместитель (proxy), серверную заглушку (stub) и класс-мост (bridge). По мере роста объема приложения, на каком бы языке оно ни было написано, эти файлы приходится организовывать в группы. Затем, на стадии сборки приложения, вы, вероятно, станете создавать различные варианты одних и тех же файлов для каждой новой промежуточной версии и захотите поместить все это в систему управления конфигурацией.
В большинстве случаев нет необходимости моделировать данный аспект системы непосредственно. Вместо этого вы позволите среде разработки отслеживать эти файлы и их связи. Иногда, однако, небесполезно визуализировать исходные файлы и связи между ними с помощью диаграмм артефактов. Применяемые таким образом диаграммы артефактов обычно содержат только артефакты – рабочие продукты со стереотипами файлов – вместе с их зависимостями. Например, вы могли бы выполнить обратное проектирование набора исходных файлов для визуализации сложной системы зависимостей между ними при компиляции. Можно пойти и в другом направлении, специфицировав связи между исходными файлами и затем передав эту модель на вход инструменту компиляции, такому как программа make в UNIX. Аналогично можно использовать диаграммы артефактов для визуализации истории набора исходных файлов, хранящихся в системе управления конфигурацией. Получая из этой системы информацию (например, о том, сколько раз некий файл извлекался для редактирования на протяжении определенного периода времени), вы можете использовать ее для "раскраски" диаграммы артефактов, что поможет выявить среди исходных файлов "горячие точки", в которых архитектура системы чаще всего подвергается модификациям.
Чтобы смоделировать исходный код системы, необходимо:
- Применяя прямое или обратное проектирование, идентифицировать набор представляющих интерес файлов исходного кода и смоделировать их как артефакты со стереотипом file.
- Для крупных систем использовать пакеты, чтобы показать группы исходных файлов.
- Рассмотреть возможность показа с помощью помеченных значений такой информации, как номер версии файла, его автор, дата последнего изменения. Для управления этими значениями применять инструментальные средства.
- Смоделировать зависимости компиляции между исходными файлами с помощью связей зависимости. Опять же, для того чтобы сгенерировать эти зависимости и управлять ими, понадобятся инструментальные средства.
В качестве примера на рис. 1 показаны пять файлов исходного кода.
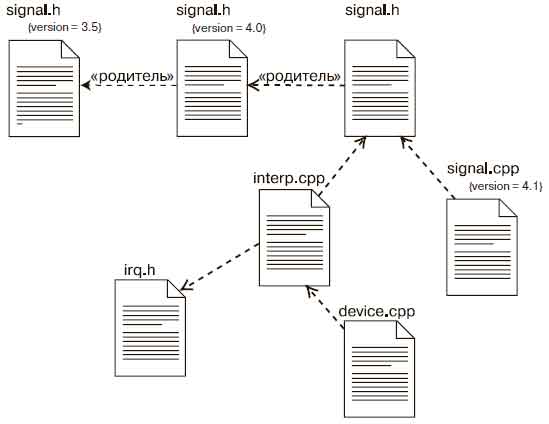
Рис.1. Моделирование исходного кода
Файл signal.h – заголовочный. Представлены три его версии, начиная с последней и заканчивая первой. Каждая версия помечена значением, указывающим ее номер.
Заголовочный файл signal.h используется двумя другими – interp.cpp и signal.cpp. Первый из них при компиляции зависит от другого заголовочного файла, irq.h. В свою очередь, файл device.cpp зависит от interp.cpp. Имея перед глазами такую диаграмму, легко проследить, что произойдет в случае изменений. В частности, изменение исходного файла signal.h потребует перекомпиляции трех других файлов – signal.cpp, interp.cpp и, как следствие, device.cpp. Из той же диаграммы видно, что irq.h не коснутся преобразования.
Подобные диаграммы легко генерируются путем обратного проектирования на основе информации, хранящейся в системе управления конфигурацией среды разработки.
На следующем шаге рассмотрим типичные приемы моделирования исполняемой версии в UML.
