На этом шаге рассмотрим типичные приемы моделирования исполняемой версии в UML.
Выпуск версий простого приложения не составляет труда – единственная исполняемая программа сбрасывается на диск, и пользователи просто запускают ее. Для подобных приложений диаграммы артефактов не требуются: там нечего визуализировать, специфицировать, конструировать и документировать.
Выпуск версий более сложных приложений все-таки предполагает трудозатраты, иногда немалые. Кроме главной исполняемой программы (обычно файла с расширением .exe), нужен ряд вспомогательных модулей (обычно это файлы с расширением .dll, если вы работаете в контексте COM+, либо .class или .jar – при работе с языком Java), баз данных, файлов подсказки и ресурсных файлов. Для распределенных систем, вероятно, понадобится несколько исполняемых программ и других файлов, разбросанных по разным узлам. Если вы работаете с системой приложений, одни артефакты могут оказаться уникальными, а другие будут использоваться в нескольких приложениях. По мере развития системы управление конфигурацией всего этого множества артефактов приобретает все большую важность и вместе с тем усложняется, поскольку изменение некоторых артефактов в одном приложении может отразиться на работе других.
По этой причине для визуализации, специфицирования, конструирования и документирования исполняемых версий (включая артефакты размещения, формирующие каждую версию, и связи между этими артефактами) используются диаграммы артефактов. Вы можете применять их для прямого проектирования новой системы и для обратного проектирования существующей.
Создавая диаграммы артефактов, подобные той, что изображена на рис. 1 шага 220, вы на самом деле просто моделируете часть сущностей и связей, которые представляют реализацию вашей системы. По этой причине каждая диаграмма артефактов должна сосредотачивать внимание только на одном текущем наборе артефактов.
Чтобы смоделировать исполняемую версию, необходимо:
- Идентифицировать набор артефактов, подлежащих моделированию. Обычно это выборка либо вся совокупность артефактов, размещенных на одном узле, или же ряд артефактов, распределенных по узлам системы.
- Рассмотреть стереотипы каждого артефакта в наборе. Для большинства систем обнаружится ограниченное число разных видов артефактов (таких как исполняемые программы, библиотеки, таблицы, файлы и документы). Для визуального представления этих стереотипов можно воспользоваться механизмами расширения UML.
- Для каждого артефакта в наборе рассмотреть его связь с окружающими его артефактами. Чаще всего это интерфейсы, которые экспортирует (реализует) один артефакт и импортируют (используют) другие. Если нужно раскрыть соединения в системе, – явно смоделировать эти интерфейсы. Если же необходимо представить модель на более высоком уровне абстракции, раскрыть эти связи, показывая только зависимости между артефактами.
В качестве примера на рис. 1 представлена модель части исполняемой версии автономного робота.
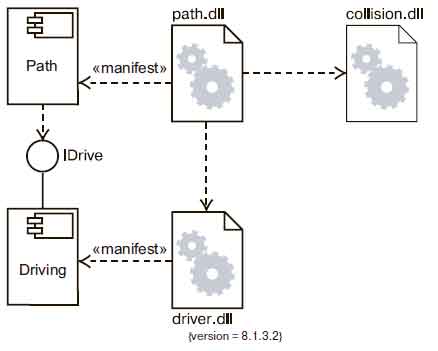
Рис.1. Моделирование исполняемой версии
Основное внимание обращено на артефакты размещения, ассоциированные с функциями перемещения робота и вычислительными операциями. Вы видите один артефакт – driver.dll, который материализует компонент Driving (Перемещение), экспортирующий интерфейс IDrive (), импортируемый компонентом Path (Путь), материализуемым другим артефактом, path.dll. Зависимость между компонентами Path и Driving указывает на зависимость между артефактами path.dll и driver.dll, которые реализуют их. На диаграмме присутствует еще один артефакт – collision.dll, который также материализует компонент, хотя эти подробности и скрыты (показана лишь прямая зависимость path.dll от collision.dll).
В данной системе участвует множество других артефактов. Однако диаграмма сосредоточена на тех артефактах размещения, которые непосредственно относятся к процессу движения робота. Заметьте, что при такой компонентной архитектуре вы могли бы заменить конкретную версию driver.dll на другую – при условии, что она реализует те же (и, возможно, какие-то дополнительные) интерфейсы, – и path.dll мог бы по-прежнему правильно работать.
На следующем шаге рассмотрим типичные приемы моделирования физической базы данных в UML.
