На этом шаге мы рассмотрим методы, использующиеся для загрузки частей документа.
Первый и самый простой пример использования технологии AJAX, который мы рассматривали на 91 шаге, запрашивал фрагмент разметки HTML и вставлял его в страницу. Однако иногда на сервере уже имеется необходимый нам код HTML, но он заключен в страницу HTML, которая нам не нужна. Когда на стороне сервера нет возможности реализовать передачу данных в желаемом нами формате, библиотека jQuery может оказать нам помощь на стороне клиента.
Рассмотрим случай, напоминающий наш первый пример, но в отличие от него документ, содержащий словарные статьи, представляет собой законченную страницу HTML, как показано ниже:
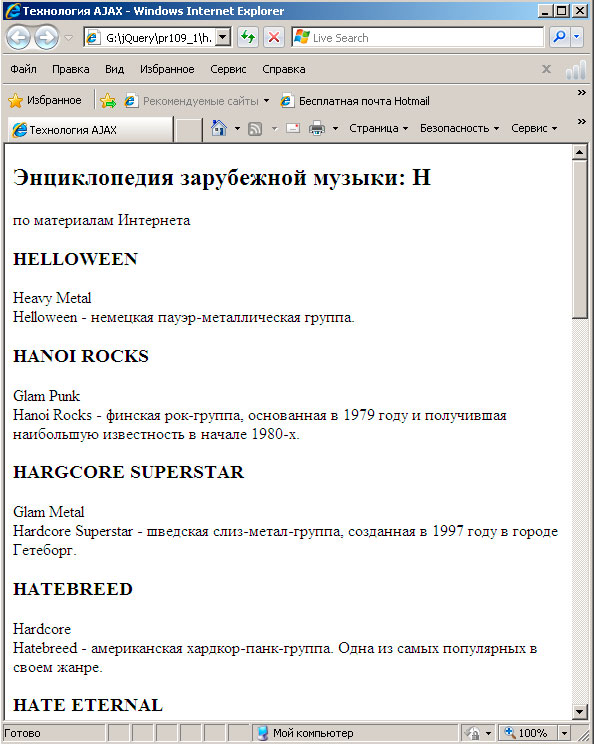
Рис.1. Вид страницы в браузере
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=win-1251"/>
<title>Технология AJAX</title>
<link rel="stylesheet" href="dictionary.css" type="text/css" media="screen" />
</head>
<body>
<div id="container">
<div id="header">
<h2>Энциклопедия зарубежной музыки: H</h2>
<div class="author">по материалам Интернета</div>
</div>
<div id="dictionary">
<div class="entry">
<h3 class="term">HELLOWEEN</h3>
<div class="part">Heavy Metal</div>
<div class="definition">
Helloween - немецкая пауэр-металлическая группа.
</div>
</div>
<div class="entry">
<h3 class="term">HANOI ROCKS</h3>
<div class="part">Glam Punk</div>
<div class="definition">
Hanoi Rocks - финская рок-группа, основанная в 1979 году и
получившая наибольшую известность в начале 1980-х.
</div>
</div>
</div>
</body>
</html>
Мы можем загрузить страницу целиком, используя программный код, написанный ранее:
$(document).ready(function() {
$('#letter-h a').click(function() {
$('#dictionary').load('h.html');
return false;
});
});
Однако это породит странный эффект из-за наличия частей страницы HTML, которые нам не нужны, как показано на рисунке 1 (щелкните по ссылке H).
Рис.1. Повторение некоторых фрагментов
Полный текст этого примера можно взять здесь.Чтобы удалить эти лишние части, мы можем задействовать новую для нас особенность метода load(). Вместе с адресом URL загружаемого документа можно указать селектор jQuery. При наличии селектора он используется для выделения частей загруженного документа. Благодаря этому в страницу будут вставлены только те части, которые соответствуют селектору. В данном случае мы применим этот прием, чтобы извлечь из документа и вставить только словарные статьи:
$(document).ready(function() {
$('#letter-h a').click(function() {
$('#dictionary').load('h.html .entry');
return false;
});
});
Теперь ненужные части документа не попадут в страницу, как показано на рисунке 2.
Рис.1. Вставка только словарных статей
Полный текст этого примера можно взять здесь.Со следующего шага мы начнем рассматривать работу с таблицами.
