На этом шаге мы рассмотрим оптимизацию работы с глобальной памятью.
Поскольку глобальная память обладает столь высокой латентностью, то крайне важным являются понимание способов доступа к ней и соответствующей оптимизации доступа.
Обращение к глобальной памяти происходит через чтение/запись 32/64/128-битовых слов. Крайне важным является то, что адрес, по которому происходит доступ, должен быть выровнен по размеру слова, то есть, кратен размеру слова в байтах.
Рассмотрим рисунок 1. Если происходит чтение 32-битового слова по адресу 0, то потребуется одно обращение к памяти. Если же чтение будет происходить с адреса 1, то потребуются два обращения к памяти, каждое из которых будет выровнено (первое читает по адресу 0, а второе - по адресу 4).
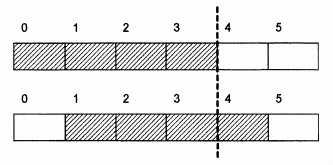
Рис. 1. Пример выровненного (сверху) и невыровненного (внизу) 4-байтового блока
Хотя все функции, выделяющие глобальную память, выделяют ее выровненной по 256 байт, тем не менее, проблемы с выравниванием могут возникать и в этом случае. Пусть у нас есть массив из следующих структур, выделенный в глобальной памяти:
struct vec3{ float x, y, z; };
Хотя каждый элемент массива (длиной в 12 байт) полностью помещается в 16 байтах, но даже если адрес первого элемента массива и выровнен по 16 байтам, то адрес следующего элемента уже не будет выровнен по 16 байтам, и его чтение потребует двух обращений.
Поэтому, если элементы этого массива читаются нитями, то каждое второе обращение к массиву будет осуществляться в два обращения, то есть будет заметный проигрыш в скорости.
Проще всего это исправить - обеспечить выравнивание элементов массива, которое можно достигнуть следующим способом (или добавить один фиктивный элемент):
struct __align__(16) vec3{ float x, y, z; };
Теперь все элементы массива будут находиться на адресах, кратных 16, что обеспечит чтение одного элемента за один раз. Таким образом, хотя мы и увеличили объем выделяемой и читаемой памяти, но работа с этой памятью будет происходить заметно быстрее.
Крайне важным для оптимизации работы с глобальной памятью является использование возможности GPU объединить несколько запросов к глобальной памяти в один (coalescing). Правильное использование этой возможности позволяет почти 16-кратное ускорение при работе с глобальной памятью.
Все обращения мультипроцессора к памяти происходят независимо для каждой половины warp'a. Поэтому максимальное объединение - это когда все запросы одного полу-warp'a удается объединить в один большой запрос на чтение непрерывного блока памяти.
Для того чтобы это произошло, необходимо выполнение ряда условий, при этом эти условия независимо применяются к каждой половине warp'a. Сами условия зависят от используемого GPU, а точнее от его compute capability.
Чтобы GPU с compute capabillity 1.0 или 1.1 произвел объединение запросов нитей половины warp'a необходимо, чтобы были выполнены следующие условия:
- все нити обращаются к 32-битовым словам, давая в результате один 64-байтовый блок, или все нити обращаются к 64-битовым словам, давая в результате один 128-байтовый блок;
- получившийся блок выровнен по своему размеру, то есть адрес получающегося 64-байтового блока кратен 64, а адрес получающегося 128-байтового блока кратен 128;
- все 16 слов, к которым обращаются нити, лежат в пределах этого блока;
- нити обращаются к словам последовательно - k-ая нить должна обращаться к k-му слову (при этом допускается, что отдельные нити пропустят обращение к соответствующим словам).
Если нити полу-warp'a не удовлетворяют какому-либо из данных условий, то каждое обращение к памяти происходит как отдельная транзакция.
На следующих рисунках приводятся типичные паттерны обращения, дающие объединения и не дающие объединения.
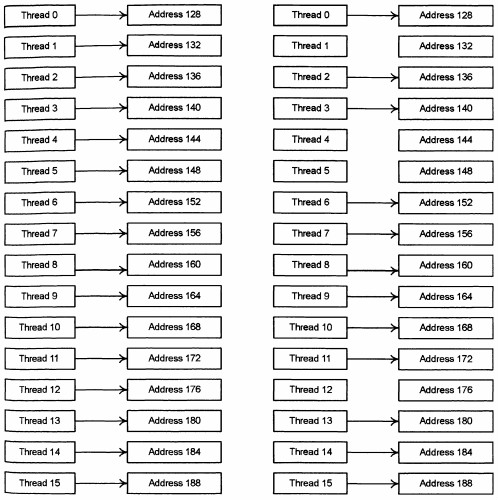
Рис. 2. Паттерны обращения к памяти, дающие объединение
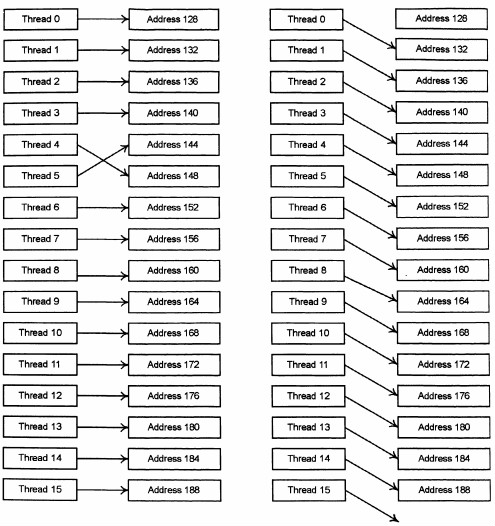
Рис. 3. Паттерны обращения к памяти, не дающие объединения
Еще одним моментом работы с глобальной памятью является то, что гораздо эффективнее с точки объединения запросов к памяти, использование не массивов структур, а структуры массивов (отдельных компонент исходной структуры).
struct A __align__(16){ float x, y, z; }; A array[1024]; .... A a = array[threadIdx.x];
В приведенном выше примере чтение структуры каждой нитью не даст объединения обращения к памяти, и на доступ к каждому элементу массива А понадобится отдельная транзакция. Однако если вместо одного массива А можно сделать три массива его компонент, то ситуация полностью изменится:
float a[1024]; float b[1024]; uint c[1024]; .... float fa = a[threadIdx.x]; float fb = b[threadIdx.x]; uint uc = c[threadIdx.x];
В результате такого разбиения каждый из трех запросов к очередной компоненте исходной структуры приведет к объединению запросов всех запросов нитей полу-warp'a, и в результате нам понадобится всего три транзакции на полу-warp (вместо 16 транзакций ранее).
На следующем шаге мы рассмотрим константную память.
