На этом шаге мы рассмотрим особенности такой обработки исключений.
В примере предыдущего шага в процессе выполнения программы генерировались исключения разных классов, но перехватывались и обрабатывались они в одном блоке. Другими словами, для обработки ошибок разных типов мы использовали один и тот же блок программного кода. Правда мы использовали объект исключения, что позволяло нам определить фактический класс сгенерированного исключения, но принципиально это мало что меняет: какая бы ошибка ни возникла, для обработки выполнялся один и тот же код. Но процесс перехвата и обработки исключений можно организовать более гибким способом. Мы можем для каждого типа ошибки предусмотреть персональный блок обработки. Делается это просто. После try-блока указывается не один, а несколько catch-блоков. В каждом catch-блоке указывается (в круглых скобках) тип ошибки, который обрабатывается этим блоком. При возникновении ошибки в try-блоке выполнение команд контролируемого кода прекращается и начинается просмотр catch-блоков на предмет того, совпадает ли класс сгенерированного исключения с классом ошибки, указанным в catch-блоке. Если совпадение найдено, соответствующий catch-блок используется для обработки исключения. Если все catch-блоки просмотрены и совпадение не найдено, ошибка остается необработанной.
 Совпадение класса сгенерированного исключения с классом исключения в catch-блоке понимается в том смысле, что классы должны совпадать или класс сгенерированного исключения должен
быть производным от класса, указанного в catch-блоке. Другими словами, в catch-блоке обрабатываются исключения, класс которых указан в описании catch-блока, а также
исключения всех производных классов. Поэтому, например, блок, в котором типом ошибки указан класс Exception, указывается последним в последовательности блоков, поскольку такой блок
обрабатывает все ошибки.
Совпадение класса сгенерированного исключения с классом исключения в catch-блоке понимается в том смысле, что классы должны совпадать или класс сгенерированного исключения должен
быть производным от класса, указанного в catch-блоке. Другими словами, в catch-блоке обрабатываются исключения, класс которых указан в описании catch-блока, а также
исключения всех производных классов. Поэтому, например, блок, в котором типом ошибки указан класс Exception, указывается последним в последовательности блоков, поскольку такой блок
обрабатывает все ошибки.
В описании catch-блока тип исключения указывается в круглых скобках после ключевого слова catch. При необходимости там же можно обозначить объект исключения и использовать его для получения информации о возникшем событии. В примере ниже представлена программа (которая является вариацией примера из предыдущего шага). В ней используется несколько catch-блоков для обработки исключений. Поскольку многие команды в программе должны быть вам уже знакомы, то для сокращения объема программного кода комментарии удалены.
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace pr223_1 { class Program { static void Main() { Random rnd = new Random(); int[] nums; int x; for (int k = 1; k < 10; k++) { Console.Write("[{0}] ", k); try { nums = new int[2 * rnd.Next(3) - 1]; x = 1 / rnd.Next(3); nums[rnd.Next(2) - 1] = x; nums[0] = Int32.Parse("ноль"); } catch (OverflowException) { Console.WriteLine("Ошибка №1: Неверный размер массива"); } catch (DivideByZeroException) { Console.WriteLine("Ошибка №2: Деление на ноль"); } catch (IndexOutOfRangeException) { Console.WriteLine("Ошибка №3: Неверный индекс элемента"); } catch (FormatException) { Console.WriteLine("Ошибка №4: Неверный формат числа"); } } // Задержка: Console.ReadLine(); } } }
С поправкой на использование генератора случайных чисел результат выполнения программы может быть следующим:
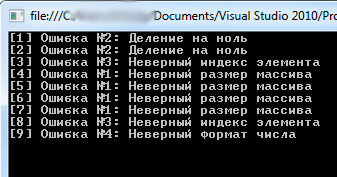
Рис.1. Результат выполнения программы
В данном случае мы отказались от переменной n, с помощью которой ранее запоминалась команда, вызывавшая ошибку. Принцип выполнения программного кода такой же, как и в предыдущем случае. Отличие лишь в том, что при возникновении ошибки (причины возникновения ошибок не изменились) обработка ошибки выполняется одним из четырех catch-блоков. Класс ошибки, обрабатываемой catch-блоком, указан в круглых скобках после ключевого слова catch. Объект ошибки при этом мы не объявляли (хотя могли бы), поскольку в процессе обработки ошибок он не используется. В зависимости от того, какого типа ошибка произошла, для обработки ошибки выполняется код соответствующего catch-блока.
Совсем не обязательно в индивидуальном порядке обрабатывать все ошибки. Другими словами, мы можем описать catch-блоки только для некоторых типов ошибок и предусмотреть catch-блок для ошибок всех прочих типов.
Делается это просто. Например, мы хотим, чтобы по отдельным алгоритмам обрабатывались исключения классов OverflowException и FormatException, а для всех других исключений
использовалась одна и та же схема обработки. В таком случае мы используем три catch-блока: сначала указываются блоки для ошибок типа OverflowException и FormatException,
а затем указывается catch-блок для обработки исключений класса Exception. При возникновении ошибки блоки проверяются в том порядке, как они указаны. Если исключение не будет
передано для обработки ни в первый, ни во второй блок, то оно будет обработано третьим блоком, поскольку в нем обрабатываются исключения всех классов, являющихся производными классами от
класса Exception.
На следующем шаге мы рассмотрим вложенные конструкции try-catch и блок finally.
