Шаг 24.
Язык программирования Go.
Операции со строками
На этом шаге рассмотрим операции со строками в языке Go.
Строки в языке Go поддерживают обычные операторы сравнения (<, <=, ==, !=, >, >=). Сравнение строк этими операторами выполняется побайтно.
Строки могут сравниваться непосредственно, например на равенство, и косвенно, например когда оператор < используется для сравнения строк с целью сортировки содержимого среза []string. К сожалению, при выполнении сравнения могут возникать проблемы. Эти проблемы проявляются во всех языках программирования, поддерживающих строки Юникода, и не являются характерными только для языка Go.
Оператор [] извлечения среза без всяких ограничений может применяться только к строкам из 7-битных символов ASCII, во всех остальных случаях необходимо проявлять осторожность. Строки могут сравниваться с помощью стандартных операторов сравнения.
В таблице 1 перечислены операции работы со строками в Go.
Раскрыть/скрыть таблицу 1 Операции со строками.
Таблица 1. Операции со строками
| Операция |
Описание/результат |
| s += t |
Добавляет строку t в конец строки s |
| s + t |
Конкатенация строк s и t |
| s[n] |
Байт (значение типа uint8) в позиции n, в строке s |
| s[n:m] |
Подстрока, извлеченная из строки s, начиная с позиции n по m-1 |
| s[n:] |
Подстрока, извлеченная из строки s, начиная с позиции n по len(s)-1 |
| s[:m] |
Подстрока, извлеченная из строки s, начиная с позиции 0 по m-1 |
| len(s) |
Количество байт в строке s |
| len([]rune(s)) |
Количество символов в строке s; то же значение можно получить намного быстрее с помощью функции utf8.RuneCountInString() |
| []rune(s) |
Преобразует строку в срез кодовых пунктов Юникода |
| string (символы) |
Преобразует значение типа []rune или []int32 в строку; предполагается, что значения типа rune или int32 представляют кодовые пункты Юникода |
| []byte(s) |
Преобразует строку s типа string в срез байт без копирования; нет никакой гарантии, что байты будут допустимыми значениями в кодировке UTF-8 |
| string (байты) |
Преобразует значение типа []byte или []uint8 в строку типа string без копирования; не требуется, чтобы байты были допустимыми значениями в кодировке UTF-8 |
| string(i) |
Преобразует значение i любого целочисленного типа в значение типа string; предполагается, что i представляет кодовый пункт Юникода; например, если i == 65, программе будет возвращено значение "A" |
| strconv.Itoa(i) |
Вернет строковое представление числа i типа int и значение ошибки; например если i == 65, программе будут возвращены два значения ("65", nil)
|
| fmt.Sprint(x) |
Вернет строковое представление значения x любого типа; например если x является целым числом, равным 65, программе будет возвращена строка "65" |
Символы в языке Go могут быть представлены двумя разными (но взаимозаменяемыми) способами. Единственный символ может быть представлен значением типа rune (или int32). С этого момента термины "символ", "кодовый пункт", "символ Юникода" и "кодовый пункт Юникода" будут использоваться взаимозаменяемо для ссылки на значение типа rune (или int32), хранящее единственный символ. Строки в языке Go представлены последовательностями из нуля или более символов – каждый символ внутри строки представлен одним или более байт в кодировке UTF-8.
С помощью операции преобразования типа (string(символ)) единственный символ можно преобразовать в односимвольную строку. Например:
đs := ""
for _, char := range []rune{'đ', 0x111, 0421, 273, '\u0111'} {
fmt.Printf("[0x%X '%c'] ", char, char)
đs += string(char)
}
Этот фрагмент выведет строку, в которой текст [0x111 'đ'] повторяется пять раз, а после его выполнения переменная đs будет содержать строку, содержащую текст đđđđđ.
Преобразовать строку в срез со значениями типа rune (то есть кодовых пунктов) можно с помощью операции преобразования chars := []rune(s), где s – значение типа string. Значение chars в этом случае будет иметь тип []int32, поскольку тип rune является синонимом типа int32. Такая возможность может пригодиться, например, когда потребуется выполнить посимвольный анализ строки и при этом выбирать символы, стоящие перед и после текущего. Обратное преобразование выполняется так же просто: s := string(chars), где значение chars имеет тип []rune, или []int32, а значение s будет иметь тип string.
Несмотря на удобство, оператор += обеспечивает не самый эффективный способ наращивания строк в циклах. Более удачный способ заключается в заполнении среза со строками ([]string) с последующим объединением его элементов вызовом функции strings.Join().
Цикл for ...range можно использовать для итераций по символам строки. В этом случае в каждой итерации программе становятся доступны индекс текущей позиции в строке и кодовый пункт в этой позиции. Ниже приводится пример использования этой версии цикла и посимвольный вывод строки написанной на греческом языке и означающей "Язык программирования". Результат работы приложения представлен на рисунке 1.
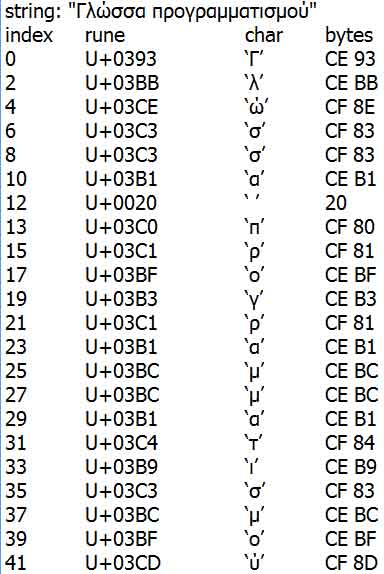
Рис.1. Результат работы приложения
Раскрыть/скрыть решение и комментарии.
phrase := "Γλώσσα προγραμματισμού"
fmt.Printf("string: \"%s\"\n", phrase)
fmt.Println("index\trune\t\tchar\tbytes")
for index, char := range phrase {
fmt.Printf("%-2d\t%U\t\t'%c'\t% X\n", index, char, char, []byte(string(char)))
}
В начале фрагмента создается строковый литерал phrase и в следующей строке выводится на экран. Затем выполняются итерации по символам в строке – в языке Go цикл for ...range автоматически декодирует байты UTF-8 в кодовые пункты Юникода (значения типа rune), поэтому нет необходимости беспокоиться о внутреннем их представлении. Для каждого символа выводится номер его позиции, значение кодового пункта (в форме записи, принятой в стандарте Юникода), сам символ и соответствующие ему байты в кодировке UTF-8.
Чтобы получить список байтов, кодовые пункты (значения char типа rune) преобразуются в строку (содержащую единственный символ, который состоит из одного или более байтов в кодировке UTF-8). Затем эта односимвольная строка преобразуется в значение типа []byte, то есть в срез с байтами, благодаря чему появляется возможность доступа к фактическим байтам. Преобразование []byte(string) выполняется очень быстро (O(1)), так как []byte просто ссылается на внутреннее представление строки string, без необходимости копировать какие-либо данные. То же справедливо и для обратного преобразования string([]byte) – здесь байты внутреннего представления строки также никуда не копируются, поэтому данное преобразование тоже имеет сложность O(1).
Архив примера можно взять здесь.
Раскрыть/скрыть Нотация O(...).
Нотация O(…) используется в теории сложности алгоритмов для описания эффективности и потребления памяти конкретными алгоритмами. В большинстве случаев в скобках указываются значения в пропорциях к n – числу обрабатываемых элементов или длине обрабатываемого элемента. В скобках также может указываться мера потребления памяти или время обработки.
Запись O(1) означает постоянное время, то есть время обработки не зависит от величины n.
Запись O(log n) означает увеличение времени по логарифмическому закону – это очень быстрый алгоритм, время работы которого пропорционально log n.
Запись O(n) означает линейное увеличение времени – это довольно быстрый алгоритм, время работы которого пропорционально n.
Запись O(n2) означает увеличение времени по квадратичному закону – это медленный алгоритм, время работы которого пропорционально n2.
Запись O(nm) означает увеличение времени по полиномиальному закону – скорость работы такого алгоритма падает очень быстро с ростом n, особенно при значениях m ≥ 3.
Запись O(n!) означает увеличение времени по факториальному закону – даже при маленьких значениях n такой алгоритм становится слишком медленным, чтобы иметь практическую ценность.
На следующем шаге рассмотрим индексирование строки в Go.
Предыдущий шаг  Содержание
Следующий шаг
Содержание
Следующий шаг