На этом шаге мы рассмотрим промежуточные и терминальные функции�
Ниже в таблице 1 приведены промежуточные функции, а в таблице 2 приведены терминальные функции.
| Функция� | Описание� |
|---|---|
| Stream<T> filter(Predicate<? super T> predicate) | Данная функция принимает предикат для отбора значений из потока, которые удовлетворяют этому предикату.� |
| <R> Stream<R> map(Function<? super T, ? extends R> mapper) | Принимает функцию и преобразовывает каждый элемент в другой объект при помощи этой функции.� |
| <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)� | Данная функция принимает функцию “маппер”, которая из элемента исходного потока создает новый поток. В результате полученные потоки объединяются в один. � |
| Stream<T> peek(Consumer<? super T> action) | Данная функция получает элемент потока, ничего с ним не делая, возвращает обратно в этот же поток. Полезна для отладки выполнения промежуточных функций.� |
| Stream<T> sorted() | Данная функция возвращает отсортированное представление потока. Элементы сортируются в обычном порядке.� |
| Stream<T> sorted(Comparator<? super T> comparator)� | Отличие от предыдущей функции в том, что данной функции передается компаратор для задания порядка сортировки.� |
| Stream<T> distinct() | Данная функция нужна для удаления дублирующий значений из потока.� |
| Stream<T> limit(long maxSize) | Функция принимает число элементов и выдает первые maxSize элементов потока. Если в данном потоке меньше элементов чем maxSize, то возвращается весь поток.� |
| Stream<T> skip(long n) | Функция принимает число элементов и пропускает первые n элементов потока. Если в данном потоке меньше элементов чем n, то возвращается пустой поток.� |
| Функция� | Описание� |
|---|---|
| void forEach(Consumer<? super T> action) | Функция для обхода каждого элемента. Применяет заданную функцию ко всем его элементам.� |
| Optional<T> findFirst() | Возвращает первое число, подходящее под заданное условие. Если такого элемента нет, возвращает null. Найденное значение (возможно null) будет упаковано в объекте класса Optional (про него мы поговорим позднее).� |
| Optional<T> findAny() | Отличается от предыдущей функции тем, что возвращает любой элемент из заданного потока удовлетворяющий условию. Найденное значение (возможно null) будет упаковано в объекте класса Optional.� |
| boolean allMatch(Predicate<? super T> predicate) | Функция принимает предикат и проверяет удовлетворяют ли все элементы потока этому предикату. Возвращает true, если все удовлетворяют, и false - в противном случае.� |
| boolean anyMatch(Predicate<? super T> predicate)� | Отличается от функции allMatch тем, что возвращает true, если есть элемент, который удовлетворяет предикату, и false - в противном случае.� |
| boolean noneMatch(Predicate<? super T> predicate)� | Отличается от функции allMatch тем, что возвращает true, если есть элемент, который не удовлетворяет предикату, и false - в противном случае.� |
| Optional<T> reduce(BinaryOperator<T> accumulator) | Сворачивает данный поток с помощью заданной операции accumulator. Причем на каждом элементе потока первым аргументом аккумулятора будет результат операции на предыдущем элементе. Полученное значение (возможно null) будет упаковано в объекте класса Optional.� |
| T reduce(T identity, BinaryOperator<T> accumulator) | То же что и предыдущая функция. Различие в том, что в качестве начального значения для первого элемента accumulator будет значение identity.� |
| <R, A> R collect(Collector<? super T, A, R> collector)� | Данная функция позволяет преобразовать поток с помощью заданного коллектора к новому типу данных (данную функцию мы рассмотрим позднее). |
| Optional<T> min(Comparator<? super T> comparator)� | Данная функция возвращает минимальное значение из потока, поиск которого происходит с помощью компаратора. Полученное значение (возможно null) будет упаковано в объекте класса Optional. |
| Optional<T> max(Comparator<? super T> comparator) | Данная функция возвращает максимальное значение из потока, поиск которого происходит с помощью компаратора. Полученное значение (возможно null) будет упаковано в объекте класса Optional.� |
| long count() | Данная функция возвращает количество элементов в потоке.� |
Приведем ниже несколько примеров использования Stream Api.
1 пример. С помощью интерфейса Supplier получить первое число Фибоначчи, которое больше миллиона.
import java.util.function.Supplier; import java.util.stream.Stream; public class Main { public static final int MILLION = 1_000_000; public static void main(String[] args) { // С помощью данного стрима мы находим первое число Фибоначчи большее 1000000 Stream.generate(new SupplierFibonacci()) .filter(v -> v > MILLION) // находим числа большие 1000000 .limit(1) // берем первое из них .forEach(System.out::println); } /** * Класс для получения очередного числа Фибоначчи */ private static class SupplierFibonacci implements Supplier<Integer> { private int prev = 0; private int next = 1; @Override public Integer get() { int current = next; next += prev; prev = current; return current; } } }
Проект можно взять здесь
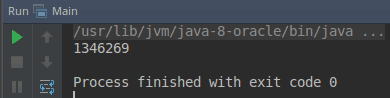
Рис. 1. Вывод программы
2 пример. Считать текст из файла (путь к файлу передается через командную строку). Провести поиск первых 10 различных слов, в которых содержится заданная буква (передается через командную строку). Длина слов должна быть не менее 5 символов. Слова должны быть отсортированы в алфавитном порядке (перед установкой лимита) и приведены к нижнему регистру. Если таких слов меньше чем 10, то получить сколько есть, но если таких слов нет, то сообщить это.
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class Main { /** * Функция для проверки требуемых аргументов программы * * @param args аргументы программы */ private static boolean checkArgs(String[] args) { if (args.length == 0) { System.out.println("Передайте путь к файлу"); return false; } if (args.length == 1 || args[args.length - 1].length() > 1) { System.out.println("Передайте букву для поиска"); return false; } return true; } /** * Функция удаляем все знаки препинания в конце слова * * @param word Слово * @return слово без знаков препинания */ private static String removeSymbols(String word) { word = word.replace(",", ""); word = word.replace("!", ""); word = word.replace(":", ""); word = word.replace("?", ""); word = word.replace(".", ""); return word; } public static void main(String[] args) throws IOException { if (!checkArgs(args)) { return; } String fileName = args[0]; String symbol = args[1]; System.out.println("Список слов удовлетворяющие условию задачи"); List<String> words = Files.lines(Paths.get(fileName)) // будем читать с файла // делаем разбиение на слова. Делителем будем считать пробельный символ .map(line -> line.split("\\s+")) // преобразуем полученный массив слов в поток и объединяем эти потоки в один .flatMap(Arrays::stream) // удаляем знаки препинания .map(Main::removeSymbols) // фильтруем так чтобы остались только слова, длина которых не меньше 5 .filter(word -> word.length() >= 5) // из оставшихся слов выбираем только те, которые содержат заданную букву .filter(word -> word.contains(symbol)) // сортируем слова в алфавитном порядке .sorted() // убираем дублирубщие слова .distinct() // берем первые 10 слов .limit(10) // приводим к нижниму регистру .map(String::toLowerCase) // перемещаем полученные слова из потока в список .collect(Collectors.toList()); if (words.size() == 0) { System.out.println("В файле нет требуемых слов"); } else { words.forEach(System.out::println); // выводим найденные слова } } }
Проект можно взять здесь
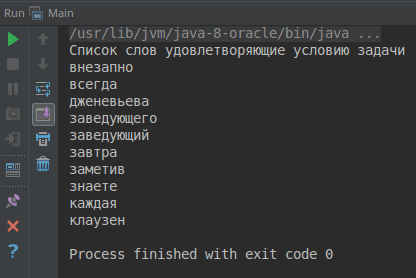
Рис. 2. Вывод программы
На следующем шаге мы рассмотрим интерфейсы IntStream, LongStream, DoubleStream�
