На этом шаге мы рассмотрим пример исследования данных.
Перед тем как строить модель машинного обучения, неплохо было бы исследовать данные, чтобы понять, можно ли легко решить поставленную задачу без машинного обучения или содержится ли нужная информация в данных.
Кроме того, исследование данных - это хороший способ обнаружить аномалии и особенности. Например, вполне возможно, что некоторые из ваших ирисов измерены в дюймах, а не в сантиметрах. В реальном мире нестыковки в данных и неожиданности очень распространены.
Один из лучших способов исследовать данные - визуализировать их. Это можно сделать, используя диаграмму рассеяния (scatter plot). В диаграмме рассеяния один признак откладывается по оси х, а другой признак - по оси у, каждому наблюдению соответствует точка. К сожалению, экран компьютера имеют только два измерения, что позволяет разместить на графике только два (или, возможно, три) признака одновременно. Таким образом, трудно разместить на графике наборы данных с более чем тремя признаками. Один из способов решения этой проблемы - построить матрицу диаграмм рассеяния (scatterplot matrix) или парные диаграммы рассеяния (pair plots), на которых будут изображены все возможные пары признаков. Если у вас есть небольшое число признаков, например, четыре, как здесь, то использование матрицы диаграмм рассеяния будет вполне разумным. Однако, вы должны помнить, что матрица диаграмм рассеяния не показывает взаимодействие между всеми признаками сразу, поэтому некоторые интересные аспекты данных не будут выявлены с помощью этих графиков.
Рисунок 1 представляет собой матрицу диаграмм рассеяния для признаков обучающего набора. Точки данных окрашены в соответствии с сортами ириса, к которым они относятся. Чтобы построить диаграммы, мы сначала преобразовываем массив NumPy в DataFrame (основный тип данных в библиотеке pandas). В pandas есть функция для создания парных диаграмм рассеяния под названием scatter_matrix. По диагонали этой матрицы располагаются гистограммы каждого признака:
[In 18]: import numpy as np import matplotlib.pyplot as plt %matplotlib inline import pandas as pd import mglearn from IPython.display import display plt.rc('font', family='Verdana') # создаем data frame из данных в массиве X_train # маркируем столбцы, используя строки в iris_dataset.feature_names iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names) # создаем матрицу рассеяния из data frame, цвет точек задаем с помощью y_train grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
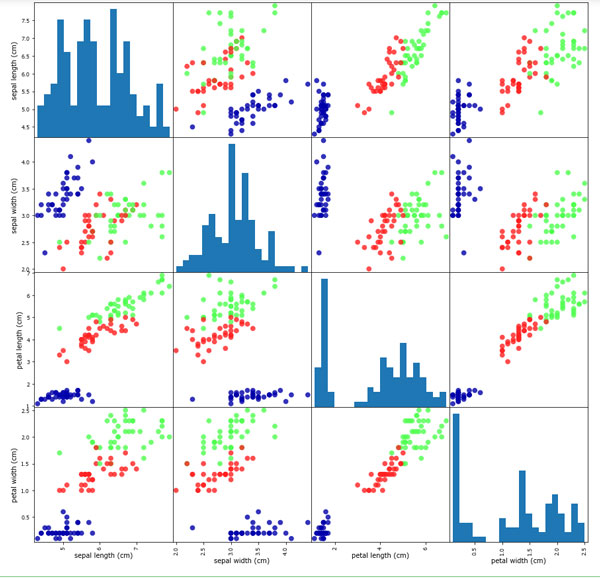
Рис.1. Матрица диаграмм рассеяния для набора данных Iris, цвет точек данных определяется метками классов
Взглянув на график, мы можем увидеть, что, похоже, измерения чашелистиков и лепестков позволяют относительно хорошо разделить три класса. Это означает, что модель машинного обучения, вероятно, сможет научиться разделять их.
На следующем шаге мы рассмотрим использование метода k ближайщих соседей.
