На этом шаге мы поясним эти понятия.
В машинном обучении с учителем нам нужно построить модель на обучающих данных, а затем получить точные прогнозы для новых, еще не встречавшихся нам данных, которые имеют те же самые характеристики, что и использованный нами обучающий набор. Если модель может выдавать точные прогнозы на ранее не встречавшихся данных, мы говорим, что модель обладает способностью обобщать (generalize) результат на тестовые данные. Нам необходимо построить модель, которая будет обладать максимальной обобщающей способностью.
Обычно мы строим модель таким образом, чтобы она давала точные прогнозы на обучающем наборе. Если обучающий и тестовый наборы имеют много общего между собой, можно ожидать, что модель будет точной и на тестовом наборе. Однако в некоторых случаях этого не происходит. Например, если мы строим очень сложные модели, необходимо помнить, что на обучающей выборке можно получить произвольную правильность.
Давайте взглянем на выдуманный пример, чтобы проиллюстрировать этот тезис. Скажем, начинающий специалист по анализу данных хочет спрогнозировать покупку клиентом лодки на основе записей о клиентах, которые ранее приобрели лодку, и клиентах, которые не заинтересованы в покупке лодки. Цель состоит в том, чтобы отправить рекламные письма клиентам, которые, вероятно, хотят совершить покупку, и не беспокоить клиентов, не заинтересованных в покупке.
Предположим, у нас есть записи о клиентах, приведенные в таблице 1.
| Возраст | Количество автомобилей в собственности | Есть собственный дом | Количество детей | Семейное положение | Есть собака | Купил лодку |
|---|---|---|---|---|---|---|
| 66 | 1 | да | 2 | вдовец | нет | да |
| 52 | 2 | да | 3 | женат | нет | да |
| 22 | 0 | нет | 0 | женат | да | нет |
| 25 | 1 | нет | 1 | холост | нет | нет |
| 44 | 0 | нет | 2 | разведен | да | нет |
| 39 | 1 | да | 2 | женат | да | нет |
| 26 | 1 | нет | 2 | холост | нет | нет |
| 40 | 3 | да | 1 | женат | да | нет |
| 53 | 2 | да | 2 | разведен | нет | да |
| 64 | 2 | да | 3 | разведен | нет | нет |
| 58 | 2 | да | 2 | женат | да | да |
| 33 | 1 | нет | 1 | холост | нет | нет |
Поработав с данными некоторое время, наш начинающий специалист формулирует следующее правило "если клиент старше 45 лет, у него менее трех детей, либо у него трое и он женат, то он скорее всего купит лодку". Если спросить, насколько хорошо работает это правило, наш специалист воскликнет "оно дает 100%-ную правильность!" И в самом деле, для данных, приведенных в таблице, это правило демонстрирует идеальную правильность. Мы могли бы сформулировать массу правил, объясняющих покупку лодки. Значения возраста появляются в наборе данных лишь один раз, таким образом, мы могли бы сказать, что люди в возрасте 66, 52, 53 и 58 лет хотят купить лодку, тогда как все остальные не собираются ее покупать. Несмотря на то что можно сформулировать множество правил, которые хорошо работают для этих наблюдений, следует помнить о том, что нам не интересны прогнозы для этого набора данных, мы уже знаем ответы для этих клиентов. Мы хотим знать, могут ли новые клиенты купить лодку. Поэтому нам нужно правило, которое будет хорошо работать для новых клиентов, и достижение 100%-ной правильности на обучающей выборке не поможет нам в этом. Нельзя ожидать, что правило, сформулированное нашим специалистом, будет так же хорошо работать и для новых клиентов. Похоже, с этим у нас сложность, ведь у нас мало данных. Например, часть правила "либо трое и он женат" сформулировано по одному клиенту.
Единственный показатель качества работы алгоритма на новых данных - это использование тестового набора. Однако интуитивно мы ожидаем, что простые модели должны лучше обобщать результат на новые данные. Если бы правило звучало "люди старше 50 лет хотят купить лодку" и оно объясняло бы поведение всех клиентов, мы доверяли бы ему больше, чем правилу, которое помимо возраста включало бы количество детей и семейное положение. Поэтому нам всегда нужно искать самую простую модель. Построение модели, которая слишком сложна для имеющегося у нас объема информации (что и сделал наш начинающий специалист по анализу данных), называется переобучением (overfitting). Переобучение происходит, когда ваша модель слишком точно подстраивается под особенности обучающего набора и вы получаете модель, которая хорошо работает на обучающем наборе, но не умеет обобщать результат на новые данные. С другой стороны, если ваша модель слишком проста, скажем, вы сформулировали правило "все, у кого есть собственный дом, покупает лодку", вы, возможно, не смогли охватить все многообразие и изменчивость данных, и ваша модель будет плохо работать даже на обучающем наборе. Выбор слишком простой модели называется недообучением (underfitting).
Чем сложнее модель, тем лучше она будет работать на обучающих данных. Однако, если наша модель становится слишком сложной, мы начинаем уделять слишком много внимания каждой отдельной точке данных в нашем обучающем наборе, и эта модель не будет хорошо обобщать результат на новые данные.
Существует оптимальная точка, которая позволяет получить наилучшую обобщающую способность. Собственно это и есть модель, которую нам нужно найти.
Компромисс между переобучением и недообучением показан на рисунке 1.
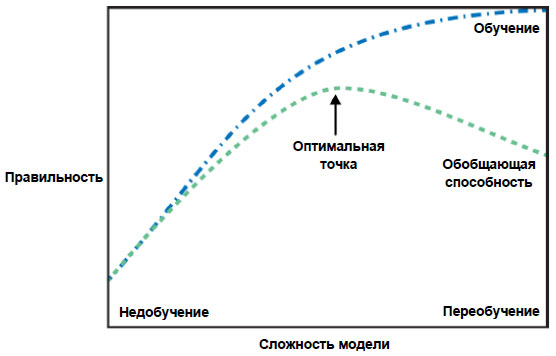
Рис.1. Компромисс между сложностью модели и правильностью на обучающей и тестовой выборках
На следующем шаге мы рассмотрим взаимосвязь между сложностью модели и размером набора данных.
