На этом шаге мы перечислим основные виды предварительной обработки.
В предыдущих шагах мы видели, что некоторые алгоритмы, например, нейронные сети и SVM, очень чувствительны к масштабированию данных. Поэтому обычной практикой является преобразование признаков с тем, чтобы итоговое представление данных было более подходящим для использования вышеупомянутых алгоритмов. Часто достаточно простого масштабирования признаков и корректировки данных. Программный код (рисунок 1) показывает простой пример:
[In 2]:
mglearn.plots.plot_scaling()
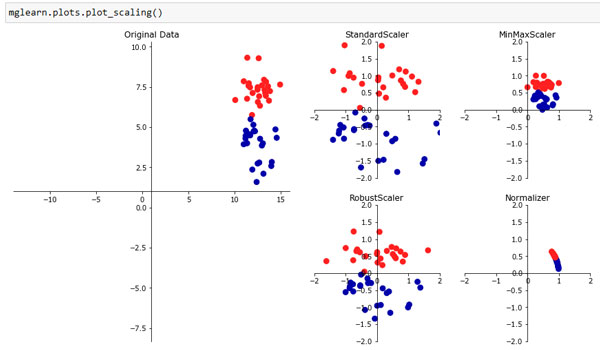
Рис.1. Различные способы масштабирования и предварительной обработки данных
Первый график на рисунке 1 соответствует синтетическому двуклассовому набору данных с двумя признаками. Первый признак (ось х) принимает значения в диапазоне от 10 до 15. Второй признак (ось у) принимает значения примерно в диапазоне от 1 до 9.
Следующие четыре графика показывают четыре различных способа преобразования данных, которые дают более стандартные диапазоны значений. Применение StandardScaler в scikit-learn гарантирует, что для каждого признака среднее будет равно 0, а дисперсия будет равна 1, в результате чего все признаки будут иметь один и тот же масштаб. Однако это масштабирование не гарантирует получение каких-то конкретных минимальных и максимальных значений признаков.
RobustScaler аналогичен StandardScaler в том плане, что в результате его применения признаки будут иметь один и тот же масштаб. Однако RobustScaler вместо среднего и дисперсии использует медиану и квартили.
 Медиана множества чисел - это такое число х, при котором половина значений множества меньше х, а другая половина значений больше х. Нижний квартиль - это число х,
ниже которого находится четверть значений, а верхний квартиль - это число х, выше которого находится четверть значений.
Медиана множества чисел - это такое число х, при котором половина значений множества меньше х, а другая половина значений больше х. Нижний квартиль - это число х,
ниже которого находится четверть значений, а верхний квартиль - это число х, выше которого находится четверть значений.
Это позволяет RobustScaler игнорировать точки данных, которые сильно отличаются от остальных (например, ошибки измерений). Эти странные точки данных еще называются выбросами (outliers) и могут стать проблемой для остальных методов масштабирования.
С другой стороны, MinMaxScaler сдвигает данные таким образом, что все признаки находились строго в диапазоне от 0 до 1. Для двумерного набора данных это означает, что все данные помещаются в прямоугольник, образованный осью х с диапазоном значений от 0 и 1 и осью у с диапазоном значений от 0 и 1.
И, наконец, Normalizer осуществляет совершенно иной вид масштабирования. Он масштабирует каждую точку данных таким образом, чтобы вектор признаков имел евклидову длину 1. Другими словами, он проецирует точку данных на окружность с радиусом 1 (или сферу в случае большого числа измерений). Вектор умножается на инверсию своей длины. Подобная нормализация используется тогда, когда важным является направление (но не длина) вектора признаков.
На следующем шаге мы рассмотрим применение преобразований данных.
