На этом шаге мы рассмотрим особенности выполнения этой операции.
Чтобы модель контролируемого обучения работала на тестовом наборе, важно преобразовать обучающий и тестовый наборы одинаковым образом. Следующий пример (рисунок 1) показывает, что произошло бы, если бы мы использовали минимальное значение и ширину диапазона, отдельно вычисленные для тестового набора:
[In 8]: from sklearn.datasets import make_blobs # создаем синтетические данные X, _ = make_blobs(n_samples=50, centers=5, random_state=4, cluster_std=2) # разбиваем их на обучающий и тестовый наборы X_train, X_test = train_test_split(X, random_state=5, test_size=.1) # размещаем на графике обучающий и тестовый наборы fig, axes = plt.subplots(1, 3, figsize=(13, 4)) axes[0].scatter(X_train[:, 0], X_train[:, 1], c=mglearn.cm2(0), label="Обучающий набор", s=60) axes[0].scatter(X_test[:, 0], X_test[:, 1], marker='^', c=mglearn.cm2(1), label="Тестовый набор", s=60) axes[0].legend(loc='upper left') axes[0].set_title("Исходные данные") # масштабируем данные с помощью MinMaxScaler scaler = MinMaxScaler() scaler.fit(X_train) X_train_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test) # визуализируем правильно масштабированные данные axes[1].scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=mglearn.cm2(0), label="Обучающий набор", s=60) axes[1].scatter(X_test_scaled[:, 0], X_test_scaled[:, 1], marker='^', c=mglearn.cm2(1), label="Тестовый набор", s=60) axes[1].set_title("Масштабированные данные") # масштабируем тестовый набор отдельно # чтобы в тестовом наборе min значение каждого признака было равно 0 # а max значение каждого признака равнялось 1 # НЕ ДЕЛАЙТЕ ТАК! Только в ознакомительных целях. test_scaler = MinMaxScaler() test_scaler.fit(X_test) X_test_scaled_badly = test_scaler.transform(X_test) # визуализируем неправильно масштабированные данные axes[2].scatter(X_train_scaled[:, 0], X_train_scaled[:, 1], c=mglearn.cm2(0), label="Обучающий набор", s=60) axes[2].scatter(X_test_scaled_badly[:, 0], X_test_scaled_badly[:, 1], marker='^', c=mglearn.cm2(1), label="Тестовый набор", s=60) axes[2].set_title("Неправильно масштабированные данные") for ax in axes: ax.set_xlabel("Признак 0") ax.set_ylabel("Признак 1")
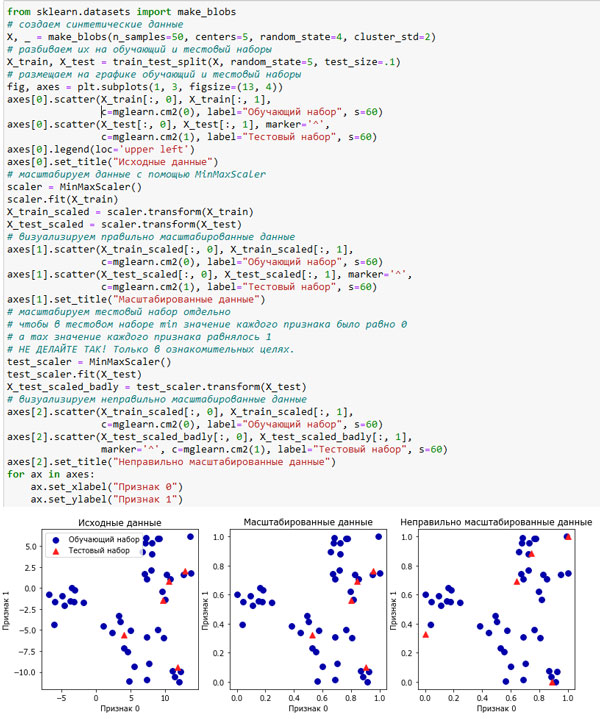
Рис.1. Результаты одинакового масштабирования обучающего и тестового наборов (центр) и отдельного масштабирования обучающего и тестового наборов (справа)
Первый график - это немасштабированный двумерный массив данных, наблюдения обучающего набора показаны кружками, а наблюдения тестового набора показаны треугольниками. Второй график - те же самые данные, но масштабированы с помощью MinMaxScaler. Здесь мы вызвали метод fit() для обучающего набора, а затем вызвали метод transform() для обучающего и тестового наборов. Как видите, набор данных на втором графике идентичен набору, приведенному на первом графике, изменились лишь метки осей. Теперь все признаки принимают значения в диапазоне от 0 до 1. Кроме того, видно, что минимальные и максимальные значения признаков в тестовом наборе (треугольники) не равны 0 и 1.
Третий график показывает, что произойдет, если отмасштабируем обучающий и тестовый наборы по отдельности. В этом случае минимальные и максимальные значения признаков в обучающем и тестовом наборах равны 0 и 1. Но теперь набор данных выглядит иначе. Тестовые точки причудливым образом сместились, поскольку масштабированы по-другому. Мы изменили расположение данных произвольным образом. Очевидно, это совсем не то. что нам нужно.
Еще один способ задуматься о неправильности этих действий заключается в том, что представить тестовый набор в виде одной точки. Не существует способа правильно масштабировать единственную точку данных, чтобы с помощью MinMaxScaler получить значения минимума и максимума. Однако размер тестового набора не должен влиять на обработку данных.

Быстрые и эффективные альтернативные способы подгонки моделей
Как правило, вам нужно сначала подогнать модель на некотором наборе данных с помощью метода fit(), а затем выполнить преобразование набора с помощью метода transform(). Это весьма распространенная задача, которую можно выполнить более эффективно, чем просто вызвать метод fit(), а затем вызвать метод transform(). Что касается вышеописанного случая, все модели, которые используют метод transform(), также позволяют воспользоваться методом fit_transform(). Ниже дан пример использования StandardScaler:
[In 9]: from sklearn.preprocessing import StandardScaler scaler = StandardScaler() # последовательно вызываем методы fit и transform (используем цепочку методов) X_scaled = scaler.fit(X).transform(X) # тот же самый результат, но более эффективный способ вычислений X_scaled_d = scaler.fit_transform(X)
На следующем шаге мы рассмотрим влияние предварительной обработки на машинное обучение с учителем.
