На этом шаге мы рассмотрим организацию такого анализа.
Часто бывает полезно визуализировать результаты перекрестной проверки, чтобы понять, как обобщающая способность зависит от искомых параметров. Поскольку выполнение решетчатого поиска довольно затратно с вычислительной точки зрения, целесообразно начинать поиск с простой и небольшой сетки параметров. Затем мы можем проверить результаты решетчатого поиска, использовав перекрестную проверку, и, возможно, расширить наш поиск. Результаты решетчатого поиска можно найти в атрибуте cv_results, который является словарем, хранящим все настройки поиска. Как вы можете увидеть в выводе, приведенном ниже, словарь содержит множество деталей и принимает более привлекательный вид после преобразования в пандасовский DataFrame.
[In 30]: import pandas as pd # преобразуем в DataFrame results = pd.DataFrame(grid_search.cv_results_) # показываем первые 5 строк display(results.head()) mean_fit_time std_fit_time mean_score_time std_score_time param_C 0 0.0018 7.483665e-04 0.0008 3.999710e-04 0.001 1 0.0112 1.890398e-02 0.0012 1.469763e-03 0.001 2 0.0020 1.168008e-07 0.0010 6.324097e-04 0.001 3 0.0028 7.484047e-04 0.0010 1.168008e-07 0.001 4 0.0022 7.483028e-04 0.0010 9.536743e-08 0.001 param_gamma params split0_test_score split1_test_score 0 0.001 {'C': 0.001, 'gamma': 0.001} 0.347826 0.347826 1 0.01 {'C': 0.001, 'gamma': 0.01} 0.347826 0.347826 2 0.1 {'C': 0.001, 'gamma': 0.1} 0.347826 0.347826 3 1 {'C': 0.001, 'gamma': 1} 0.347826 0.347826 4 10 {'C': 0.001, 'gamma': 10} 0.347826 0.347826 split2_test_score split3_test_score split4_test_score 0 0.363636 0.363636 0.409091 1 0.363636 0.363636 0.409091 2 0.363636 0.363636 0.409091 3 0.363636 0.363636 0.409091 4 0.363636 0.363636 0.409091 mean_test_score std_test_score rank_test_score 0 0.366403 0.022485 22 1 0.366403 0.022485 22 2 0.366403 0.022485 22 3 0.366403 0.022485 22 4 0.366403 0.022485 22
Каждая строка в results соответствует одной конкретной комбинации параметров. Для каждой комбинации записываются результаты всех разбиений перекрестной проверки, а также среднее значение и стандартное отклонение по всем разбиениям. Поскольку мы осуществляли поиск на основе двумерной сетки параметров (C и gamma), наилучший способ визуализировать этот процесс, представить его в виде тепловой карты (рисунок 1). Сначала мы извлечем средние значения правильности перекрестной проверки, затем изменим форму массива со значениями так, чтобы оси соответствовали C и gamma:
[In 31]: scores = np.array(results.mean_test_score).reshape(6, 6) # строим теплокарту средних значений правильности перекрестной проверки mglearn.tools.heatmap(scores, xlabel='gamma', xticklabels=param_grid['gamma'], ylabel='C', yticklabels=param_grid['C'], cmap="viridis")
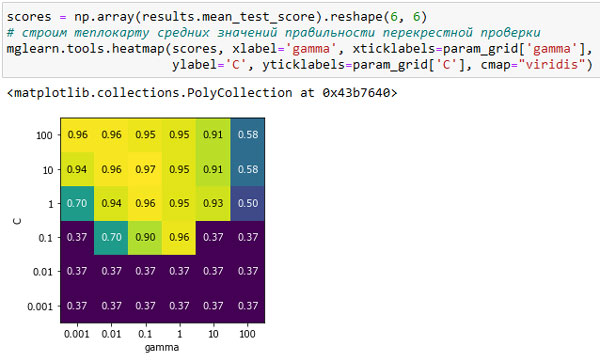
Рис.1. Тепловая карта для усредненной правильности перекрестной проверки, выраженной в виде функции двух параметров С и gamma
Каждое значение тепловой карты соответствует средней правильности перекрестной проверки для конкретной комбинации параметров. Цвет передает правильность перекрестной проверки, светлые тона соответствуют высокой правильности, темные тона - низкой правильности. Видно, что SVC очень чувствителен к настройке параметров. Для большинства настроек параметров правильность составляет около 40%, что довольно плохо; для остальных параметров правильность составляет около 96%. Из этого графика мы можем вынести несколько моментов. Во-первых, параметры, которые мы корректировали, очень важны для получения хорошей обобщающей способности. Оба параметра (C и gamma) имеют большое значение, поскольку их корректировка позволяет повысить правильность с 40% до 96%. Кроме того, интервалы значений, которые мы выбрали для параметров, представляют собой диапазоны, в которых мы видим существенные изменения результатов. Кроме того, важно отметить, что диапазоны параметров достаточно велики: оптимальные значения для каждого параметра расположены не по краям, а по центру графика.
Теперь давайте посмотрим еще на несколько графиков (показаны на рисунке 2), где результат получился менее идеальным, поскольку диапазоны поиска не были подобраны правильно:
[In 32]: fig, axes = plt.subplots(1, 3, figsize=(13, 5)) param_grid_linear = {'C': np.linspace(1, 2, 6), 'gamma': np.linspace(1, 2, 6)} param_grid_one_log = {'C': np.linspace(1, 2, 6), 'gamma': np.logspace(-3, 2, 6)} param_grid_range = {'C': np.logspace(-3, 2, 6), 'gamma': np.logspace(-7, -2, 6)} for param_grid, ax in zip([param_grid_linear, param_grid_one_log, param_grid_range], axes): grid_search = GridSearchCV(SVC(), param_grid, cv=5) grid_search.fit(X_train, y_train) scores = grid_search.cv_results_['mean_test_score'].reshape(6, 6) # строим теплокарту средних значений правильности перекрестной проверки scores_image = mglearn.tools.heatmap( scores, xlabel='gamma', ylabel='C', xticklabels=param_grid['gamma'], yticklabels=param_grid['C'], cmap="viridis", ax=ax) plt.colorbar(scores_image, ax=axes.tolist())
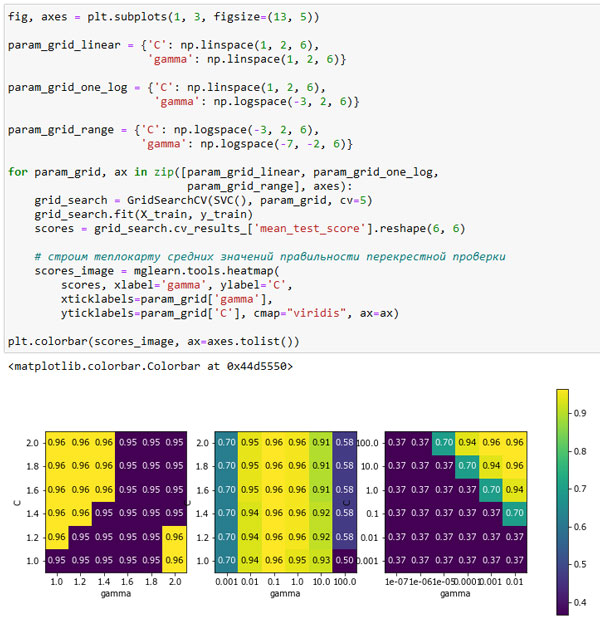
Рис.2. Теплокарты для неправильно подобранных диапазонов поиска
Первый график показывает, что независимо от выбранных параметров никакого изменения правильности не происходит, все значения правильности выделены одним и тем же цветом. В данном случае это вызвано неправильным масштабированием и диапазоном значений параметров C и gamma. Однако, если различные настройки параметров не приводят к видимому изменению правильности, это еще может указывать на то, что данный параметр просто не важен. Как правило, сначала лучше задать крайние значения, чтобы посмотреть, меняется ли правильность в результате корректировки параметра.
Второй график показывает значения правильности, сгруппированные в виде вертикальных полос. Данный факт указывает на то, что лишь изменение параметра gamma влияет на правильность. Это может означать, что для параметра gamma заданы более интересные значения, чем для параметра С, либо это означает, что параметр C не важен.
Третья панель показывает изменения правильности для обеих параметров. Однако мы видим, что в левой нижней части графика ничего интересного не происходит. Вероятно, в будущем мы можем исключить из поиска очень малые значения. Оптимальная комбинация параметров находится в правом верхнем углу. Поскольку оптимальное значение находится на границе графика, можно ожидать, что, вероятно, за пределами этой границы существуют лучшие значения, и мы могли бы изменить наш диапазон поиска, чтобы включить большее количество значений в этой области.
Настройка сетки параметров с помощью перекрестной проверки - это хороший способ исследовать важность различных параметров. Однако, как мы уже обсуждали ранее, значения различных параметров не должны проверяться на итоговом тестовом наборе, качество модели на тестовом наборе должно оцениваться лишь один раз, когда мы точно знаем, какую модель хотим использовать.
На следующем шаге мы рассмотрим экономичный решетчатый поиск.
