На этом шаге мы рассмотрим ошибки, допускаемые при выполнении этой операции.
Теперь предположим, мы хотим найти более оптимальные параметры для SVC с помощью GridSearchCV. Как нам выполнить это? Наивный подход может выглядеть следующим образом:
[In 4]: from sklearn.model_selection import GridSearchCV # только в иллюстративных целях, не используйте этот код! param_grid = {'C': [0.001, 0.01, 1, 10, 100], 'gamma': [0.001, 0.01, 1, 10, 100]} grid = GridSearchCV(SVC(), param_grid=param_grid, cv=5) grid.fit(X_train_scaled, y_train) print("Наил знач правильности перекр проверки: {:.2f}".format(grid.best_score_)) print("Наил знач правильности на тесте: {:.2f}".format(grid.score(X_test_scaled, y_test))) print("Наил параметры: ", grid.best_params_) Наил знач правильности перекр проверки: 0.98 Наил знач правильности на тесте: 0.97 Наил параметры: {'C': 1, 'gamma': 1}
Здесь мы запустили решетчатый поиск по параметрам SVC, использовав масштабированные данные. Однако нюанс заключается в том, как мы сейчас это сделали. При масштабировании данных мы использовали все данные обучающего набора, чтобы вычислить минимальные и максимальные значения признаков. Затем мы используем масштабированные обучающие данные, чтобы запустить наш решетчатый поиск с использованием перекрестной проверки. При каждом разбиении перекрестной проверки определенная часть исходного обучающего набора становится тренировочными блоками, а другая часть - проверочным блоком. Проверочный блок используется для оценки работы обученной модели на новых данных. Однако мы уже использовали информацию, содержащуюся в проверочном блоке, когда масштабировали данные. Вспомним, что проверочный блок в каждом разбиении перекрестной проверки является частью обучающего набора, а мы использовали информацию всего обучающего набора для поиска правильного масштаба данных. Мы получим совершенно другое представление новых данных в модели. Новые данные (скажем, представленные в виде тестового набора) не будут использованы при масштабировании обучающих данных и могут иметь значения минимума и максимума, отличающиеся от значений минимума и максимума для обучающих данных. Следующий пример (рисунок 1) показывает различие между обработкой данных в ходе перекрестной проверки и итоговой оценкой:
[In 5]:
mglearn.plots.plot_improper_processing()
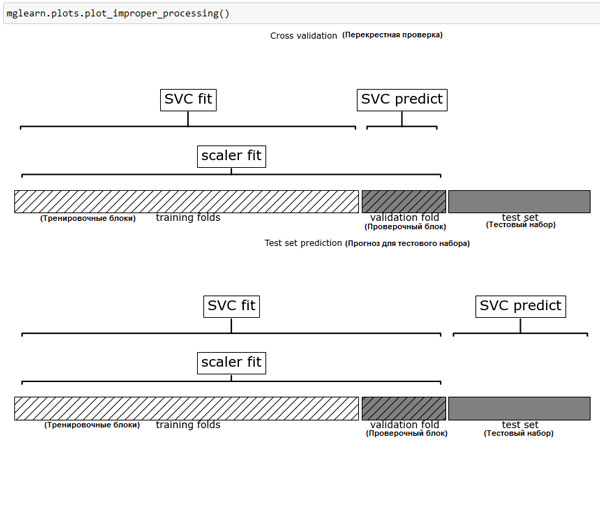
Рис.1. Использование данных: предварительная обработка вынесена за пределы цикла перекрестной проверки
Таким образом, разбиения перекрестной проверки не позволяют больше адекватно моделировать новые данные. Мы уже "поделились" информацией, содержащейся в этих блоках, с моделью. Это приведет к чрезмерно оптимистичным результатам перекрестной проверки, и, возможно, к выбору субоптимальных параметров.
Чтобы обойти эту проблему, разбиения набора данных во время перекрестной проверки должны быть выполнены перед предварительной обработкой данных. Любой процесс, извлекающий знания из данных, должен осуществляться на обучающей части набора данных, и поэтому его следует разместить внутри цикла перекрестной проверки.
Для решения этой задачи в библиотеке scikit-learn наряду с функцией cross_val_score() и функцией GridSearchCV мы можем воспользоваться классом Pipeline. Класс Pipeline позволяет "склеивать" вместе несколько операций обработки данных в единую модель scikit-learn. Класс Pipeline предусматривает методы fit(), predict() и score() и имеет все те же свойства, что и любая модель scikit- learn. Чаще всего класс Pipeline используется для объединения операций предварительной обработки (например, масштабирования данных) с моделью контролируемого машинного обучения типа классификатора.
На следующем шаге мы рассмотрим построение конвейеров.
