На этом шаге мы рассмотрим особенности использования такого конвейера.
Использование конвейера в объекте GridSearchCV аналогично использованию любой другой модели. Мы задаем сетку параметров для поиска и строим GridSearchCV на основе конвейера и сетки параметров. Однако теперь определение сетки параметров выглядит несколько иначе. Для каждого параметра нам нужно указать этап конвейера, к которому он относится. Оба параметра, которые мы хотим скорректировать, C и gamma являются параметрами SVC, то есть относятся ко второму этапу. Мы назвали этот этап "svm". Синтаксис, позволяющий настроить сетку параметров для конвейера, заключается в том, чтобы для каждого параметра указать имя этапа, затем символ двойного подчеркивания "__", а потом имя параметра. Чтобы выполнить поиск по параметру C для SVC, мы в качестве ключа (сетка параметров представляет собой словарь) должны задать "svm__C", затем ту же самую процедуру нужно выполнить для gamma:
[In 9]: param_grid = {'svm__C': [0.001, 0.01, 1, 10, 100], 'svm__gamma': [0.001, 0.01, 1, 10, 100]}
Задав сетку параметров, мы можем использовать GridSearchCV обычным образом:
[In 10]: grid = GridSearchCV(pipe, param_grid=param_grid, cv=5) grid.fit(X_train, y_train) print("Наил значение правильности перекр проверки: {:.2f}".format(grid.best_score_)) print("Правильность на тестовом наборе: {:.2f}".format(grid.score(X_test, y_test))) print("Наилучшие параметры: {}".format(grid.best_params_)) Наил значение правильности перекр проверки: 0.98 Правильность на тестовом наборе: 0.97 Наилучшие параметры: {'svm__C': 1, 'svm__gamma': 1}
В отличие от решетчатого поиска, выполненного ранее, теперь для каждого разбиения перекрестной проверки MinMaxScaler() выполняет масштабирование данных, используя лишь обучающие блоки разбиений, и теперь информация тестового блока не передается модели при поиске параметров. Сравните выполнение перекрестной проверки и итоговой оценки теперь (рисунок 1) и ранее (рисунок 1 из 169 шага):
[In 11]:
mglearn.plots.plot_proper_processing()
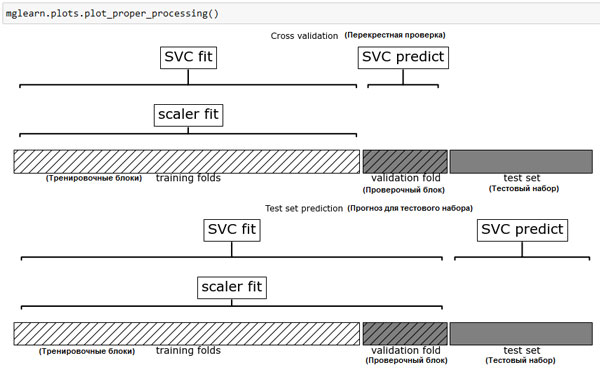
Рис.1. Использование данных: предварительная обработка внутри цикла перекрестной проверки, используется конвейер
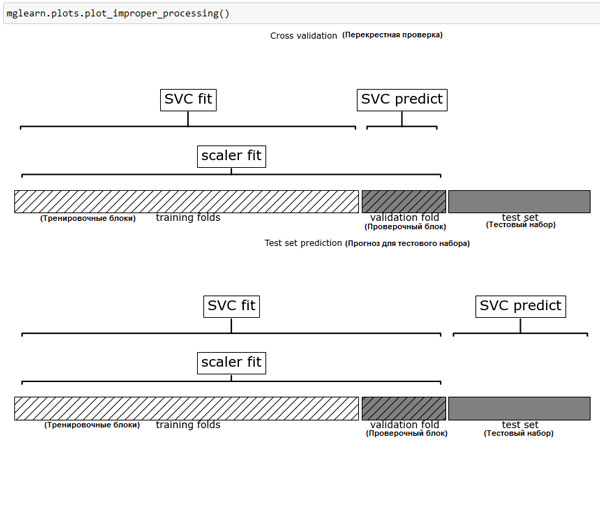
Рис.2. Использование данных: предварительная обработка вынесена за пределы цикла перекрестной проверки (рисунок 1 из 169 шага)
Последствия утечки информации, возникающей в ходе перекрестной проверки, обусловлены характером предварительной обработки. Масштабирование данных с использованием проверочного блока, как правило, не имеет серьезных последствий, в то время как использование проверочного блока для выделения и отбора признаков может привести к существенно различающимся результатам.
На следующем шаге мы рассмотрим пример утечки информации.
