На этом шаге мы рассмотрим структуру этого интерфейса.
Класс Pipeline не ограничивается предварительной обработкой и классификацией, с его помощью можно объединить любое количество моделей. Например, можно создать конвейер, включающий в себя выделение признаков, отбор признаков, масштабирование и классификацию, в общей сложности четыре этапа. Кроме того, последним этапом вместо классификации может быть регрессия или кластеризация.
Единственное требование, предъявляемое к моделям в конвейере, заключается в том, что все этапы, кроме последнего, должны использовать метод transform(), таким образом, они позволяют сгенерировать новое представление данных, которое можно использовать на следующем этапе.
Во время вызова Pipeline.fit() конвейер поочередно вызывает метод fit(), а затем метод transform() каждого этапа, вводная информация представляет собой вывод метода transform() для предыдущего этапа. Для последнего этапа конвейера просто вызывается метод fit().
Опустив некоторые мелкие детали, все вышесказанное можно реализовать с помощью программного кода, приведенного ниже. Следует помнить, что pipeline.steps является списком кортежей, поэтому pipeline.steps [0][1] является первой моделью, а line.steps[1][1] - второй моделью и так далее:
[In 16]: def fit(self, X, y): X_transformed = X for name, estimator in self.steps[:-1]: # перебираем все этапы, кроме последнего # подгоняем и преобразуем данные X_transformed = estimator.fit_transform(X_transformed, y) # осуществляем подгонку на последнем этапе self.steps[-1][1].fit(X_transformed, y) return self
При прогнозировании с помощью конвейера мы одинаковым образом преобразуем данные на всех этапах, кроме последнего, а затем вызываем метод predict() на последнем этапе:
[In 17]: def predict(self, X): X_transformed = X for step in self.steps[:-1]: # перебираем все этапы, кроме последнего # преобразуем данные X_transformed = step[1].transform(X_transformed) # получаем прогнозы на последнем этапе return self.steps[-1][1].predict(X_transformed)
На рисунке 1 проиллюстрирован конвейер, включающий два модификатора T1 и T2 и классификатор (Classifier).
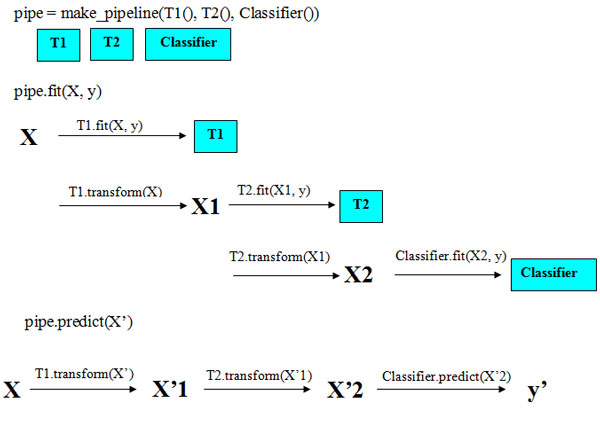
Рис.1. Схема конвейера, предназначенного для обучения и получения прогнозов
На самом деле конвейер может иметь более общий вид. Использование predict() на последнем этапе конвейера не является обязательным требованием и мы могли бы создать конвейер, который содержит scaler и PCA. Затем, поскольку последний шаг (PCA) использует метод transform(), мы могли бы вызвать метод transform() конвейера, чтобы получить вывод PCA.transform(), примененный к данным, которые были обработаны на предыдущем этапе. Последний этап конвейера требуется только для применения метода fit().
На следующем шаге мы рассмотрим способ построения конвейеров с помошью функции make_pipeline().
