На этом шаге мы рассмотрим алгоритм создания такого представления.
Один из самых простых, но эффективных и широко используемых способов подготовки текста для машинного обучения - это представление текстовой информации в виде "мешка слов" (bag-of-words). Используя это представление, мы удаляем структуру исходного текста, например, главы, параграфы, предложения, форматирование, и лишь подсчитываем частоту встречаемости каждого слова в каждом документе корпуса. Удаление структуры и подсчет частоты каждого слова позволяет получить образное представление текста в виде "мешка слов". Получение представления "мешок слов" включает следующие три этапов:
- Токенизация (tokenization). Разбиваем каждый документ на слова, которые встречаются в нем (токены), например, с помощью пробелов и знаков пунктуации.
- Построение словаря (vocabulary building). Собираем словарь всех слов, которые появляются в любом из документов, и пронумеровываем их (например, в алфавитном порядке).
- Создание разреженной матрицы (sparse matrix encoding). Для каждого документа подсчитываем, как часто каждое из слов, занесенное в словарь, встречается в документе.
Этапы 1 и 2 имеют некоторые нюансы, которые мы обсудим подробнее чуть ниже. Сейчас давайте посмотрим, как мы можем применить обработку данных "мешок слов", используя scikit-learn. Рисунок 1 иллюстрирует процесс на примере строки "This is how you get ants". В итоге каждый документ можно представить в виде вектора частот слов. Для каждого слова, записанного в словаре, мы подсчитываем частоту его встречаемости в каждом документе. Это означает, что в нашем числовом представлении каждый признак соответствуют каждому уникальному слову набора данных. Обратите внимание, порядок слов в исходной строке абсолютно не имеет никакого значения для представления признаков "мешок слов".
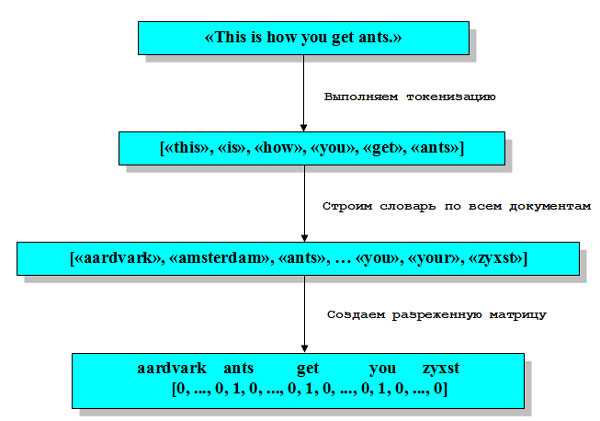
Рис.1. Обработка "мешок слов"
На следующем шаге мы рассмотрим применение модели "мешка слов" к синтетическому набору ланных.
