На этом шаге мы проанализируем полученные результаты.
И, наконец, давайте посмотрим чуть более детально на информацию, полученную с помощью модели логистической регрессии. Поскольку у нас имеется большое количество признаков (27271 после удаления малоинформативных слов), мы не можем посмотреть все коэффициенты сразу. Однако мы можем посмотреть на коэффициенты, получившие максимальные значения, а также сопоставить их словам. Мы воспользуемся последней построенной моделью на основе признаков tf-idf.
Следующая гистограмма (рисунок 1) показывает 40 наибольших и 40 наименьших коэффициентов модели логистической регрессии, каждый столбик соответствует величине коэффициента:
[In 26]: mglearn.tools.visualize_coefficients( grid.best_estimator_.named_steps["logisticregression"].coef_[1], feature_names, n_top_features=40)
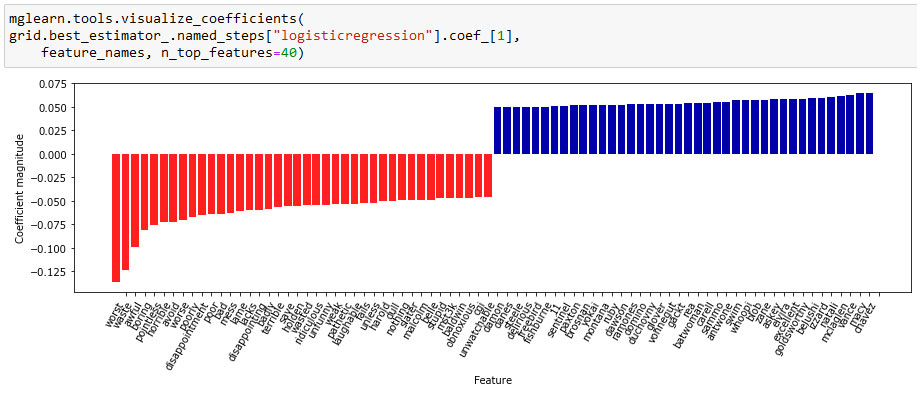
Рис.1. Наибольшие и наименьшие значения коэффициентов логистической регрессии, построенной на основе признаков tf-idf (изображение кликабельно)
Отрицательные коэффициенты, расположенные в левой части гистограммы, относятся к словам, которые в соответствии с моделью указывают на негативные отзывы, а положительные коэффициенты, расположенные в правой части гистограммы, принадлежат словам, которые означают положительные отзывы. Большая часть терминов интуитивно понятна, например, слова "worst", "waste", "disappointment" и "laughable" указывают на плохие киноотзывы, в то время как слова "excellent", "wonderful", "enjoyable" и "refreshing" свидетельствуют о положительных киноотзывах. Что касается слов типа "bit", "job" и "today", их связь с тональностью киноотзыва менее ясна, но они могут быть частью фразы, например, "good job" или "best today".
На следующем шаге мы рассмотрим модель "мешка слов" для последовательностей из нескольких слов [n-грамм].
