На этом шаге мы рассмотрим особенности передачи данных от всех процессоров всем процессорам сети.
Операция передачи данных от всех процессоров всем процессорам сети является естественным обобщением одиночной операции рассылки, двойственная ей операция - прием сообщений на каждом процессоре от всех процессоров сети. Подобные операции широко используются, например, при реализации матричных вычислений.
Возможный способ реализации операции множественной рассылки состоит в выполнении соответствующего набора операций одиночной рассылки. Однако такой подход не является оптимальным для многих топологий сети, поскольку часть необходимых операций одиночной рассылки потенциально может быть выполнена параллельно.
Передача сообщений. Для кольцевой топологии каждый процессор может инициировать рассылку своего сообщения одновременно (в каком-либо выбранном направлении по кольцу). В любой момент каждый процессор выполняет прием и передачу данных, завершение операции множественной рассылки произойдет через p-1 цикл передачи данных. Длительность выполнения операции рассылки оценивается соотношением:
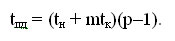
Для топологии типа решетка-тор множественная рассылка сообщений может быть выполнена при помощи алгоритма, получаемого обобщением способа передачи данных для кольцевой структуры сети. Схема обобщения состоит в следующем. На первом этапе организуется передача сообщений раздельно по всем процессорам сети, располагающимся на одних и тех же горизонталях решетки (в результате на каждом процессоре одной и той же горизонтали формируются укрупненные сообщения размера m, умноженное на корень квадратный из p, объединяющие все сообщения горизонтали). Время выполнения этапа:
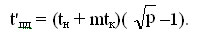
На втором этапе рассылка данных выполняется по процессорам сети, образующим вертикали решетки. Длительность этого этапа:
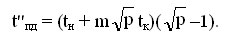
Общая длительность операции рассылки определяется соотношением:
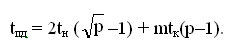
Для гиперкуба алгоритм множественной рассылки сообщений может быть получен путем обобщения ранее описанного способа передачи данных для топологии типа решетки на размерность гиперкуба N. В результате такого обобщения схема коммуникации состоит в следующем. На каждом этапе i, 1<=i<=N, выполнения алгоритма функционируют все процессоры сети, которые обмениваются своими данными со своими соседями по i-й размерности и формируют объединенные сообщения. Время операции рассылки может быть получено при помощи выражения:
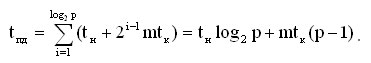
Передача пакетов. Применение более эффективного для кольцевой структуры и топологии типа решетка-тор метода передачи данных не приводит к какому-либо улучшению времени выполнения операции множественной рассылки, поскольку обобщение алгоритмов выполнения операции одиночной рассылки на случай множественной рассылки приводит к перегрузке каналов передачи данных (т.е. к существованию ситуаций, когда в один и тот же момент для передачи по одной и той же линии имеется несколько ожидающих пересылки пакетов данных). Перегрузка каналов приводит к задержкам при пересылках данных, что и не позволяет проявиться всем преимуществам метода передачи пакетов.
Широко распространенным примером операции множественной рассылки является задача редукции, которая определяется в общем виде как процедура выполнения той или иной обработки данных, получаемых на каждом процессоре в ходе множественной рассылки (в качестве примера такой задачи может быть рассмотрена проблема вычисления суммы значений, находящихся на разных процессорах, и рассылки полученной суммы по всем процессорам сети). Способы решения задачи редукции могут состоять в следующем:
- Непосредственный подход заключается в выполнении операции множественной рассылки и последующей затем обработке данных на каждом процессоре в отдельности.
- Более эффективный алгоритм может быть получен в результате применения операции одиночного приема данных на отдельном процессоре, выполнения на этом процессоре действий по обработке данных и рассылки полученного результата обработки всем процессорам сети.
- Наилучший же способ решения задачи редукции состоит в совмещении процедуры множественной рассылки и действий по обработке данных,
когда каждый процессор сразу же после приема очередного сообщения реализует требуемую обработку полученных данных (например, выполняет
сложение полученного значения с имеющейся на процессоре частичной суммой). Время решения задачи редукции при таком алгоритме реализации в
случае, например, когда размер пересылаемых данных имеет единичную длину (m=1) и топология сети имеет структуру гиперкуба, определяется выражением:
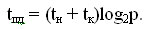
Другим типовым примером использования операции множественной рассылки является задача нахождения частных сумм последовательности значений Si:
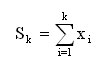
(будем предполагать, что количество значений совпадает с количеством процессоров, значение xi располагается на i-м процессоре и результат Sk должен получаться на процессоре с номером k).
Алгоритм решения данной задачи также может быть получен при помощи конкретизации общего способа выполнения множественной операции рассылки, когда процессор выполняет суммирование полученного значения (но только в том случае, если процессор-отправитель значения имеет меньший номер, чем процессор-получатель).
На следующем шаге мы продолжим изучение этого вопроса.
