На этом шаге мы рассмотрим конструкции, применяемые для реализации замены в строке.
Метод sub() ищет все совпадения с шаблоном и заменяет их указанным значением. Если совпадения не найдены, возвращается исходная строка. Метод имеет следующий формат:
sub(<Hoвый фрагмент или ссылка на функцию>, <Строка для замены>
[, <Максимальное количество замен>])
Внутри нового фрагмента можно использовать обратные ссылки \номер группы, \g<номер группы> и \g<название группы>. Для примера поменяем два тега местами:
>>> import re >>> p = re.compile(r'<(?P<tag1>[a-z]+)><(?P<tag2>[a-z]+)>') >>> p.sub(r"<\2><\1>","<br><hr>") # \номер '<hr><br>' >>> p.sub(r"<\g<2>><\g<1>>","<br><hr>") # \g<номер> '<hr><br>' >>> p.sub(r"<\g<tag2>><\g<tag1>>","<br><hr>") # \g<название> '<hr><br>'
# -*- coding: utf-8 -*- import re def repl(m): """ Функция для замены, m - объект Match """ x = int(m.group(0)) x += 10 return "{0}".format(x) p = re.compile(r"[0-9]+") # Заменяем все вхождения print(p.sub(repl, "2008, 2009, 2010, 2011")) # Заменяем только первые два вхождения print(p.sub(repl, "2008, 2009, 2010, 2011", 2)) input()
Результат выполнения:
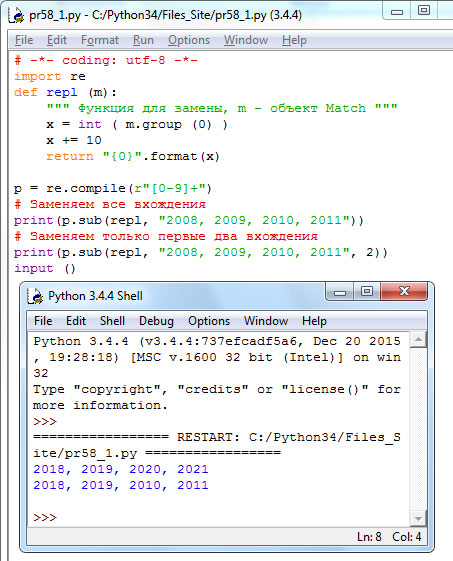
Рис.1. Результат выполнения программы
Замечание. Название функции указывается без круглых скобок.
Вместо метода sub() можно воспользоваться функцией sub(). Формат функции:
re.sub(<Шаблон>, <Новый фрагмент или ссылка на функцию>,
<Строка для замены> [, <Максимальное количество замен>[, flags=0]])
В качестве параметра <Шаблон> можно указать строку с регулярным выражением или скомпилированное регулярное выражение. Поменяем два тега местами, а также изменим регистр букв:
# -*- coding: utf-8 -*- import re def repl(m): """ Функция для замены, m - объект Match """ tag1 = m.group("tag1").upper() tag2 = m.group("tag2").upper() return "<{0}><{1}>".format(tag2, tag1) p = r"<(?P<tag1>[a-z]+)><(?P<tag2>[a-z]+)>" print(re.sub(p, repl, "<br><hr>")) input()
Результат выполнения:
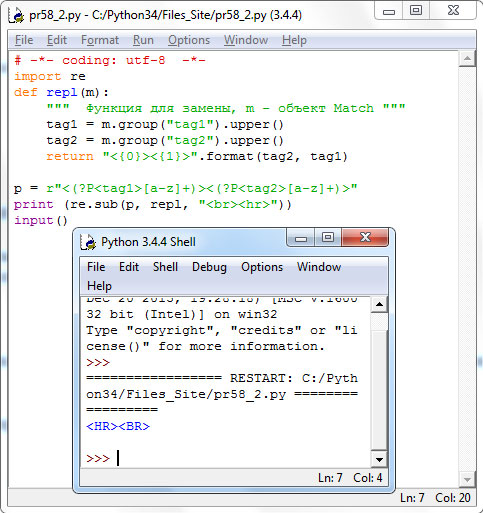
Рис.2. Результат выполнения программы
Метод subn () аналогичен методу sub (), но возвращает не строку, а кортеж из двух элементов: измененной строки и количества произведенных замен. Метод имеет следующий формат:
subn(<Новый фрагмент или ссылка на функцию>, <Строка для замены>
[, <Максимальное количество замен>])
Заменим все числа в строке на 0:
>>> p = re.compile(r'[0-9]+') >>> p.subn("0", "2007, 2008, 2009, 2010, 2011") ('0, 0, 0, 0, 0', 5)
Вместо метода subn() можно воспользоваться функцией subn(). Формат функции:
re.subn(<Шаблон>, <Новый фрагмент или ссылка на функцию>,
<Строка для замены>[, <Максимальное количество замен>[, flags=0]])
В качестве параметра <Шаблон> можно указать строку с регулярным выражением или скомпилированное регулярное выражение. Пример:
>>> p = r"200[79]" >>> re.subn(p, "2001", "2007, 2008, 2009, 2010") ('2001, 2008, 2001, 2010', 2)
Для выполнения замен также можно использовать метод expand (), поддерживаемый объектом Match. Формат метода:
expand(<Шаблон>)
Внутри указанного шаблона можно использовать обратные ссылки: \номер группы, \g<номер группы> и \g<название группы>. Пример:
>>> p = re.compile(r'<(?P<tag1>[a-z]+)><(?P<tag2>[a-z]+)>') >>> m = p.search("<br><hr>") >>> m.expand(r"<\2><\1>") # \номер '<hr><br>' >>> m.expand(r"<\g<2>><\g<1>>") # \g<номер> '<hr><br>' >>> m.expand(r"<\g<tag2>><\g<tag1>>") # \g<название> '<hr><br>'
На следующем шаге мы рассмотрим прочие функции и методы.
