На этом шаге мы рассмотрим основные команды работы с индексами.
Записи в таблицах расположены в том порядке, в котором они были добавлены. Чтобы найти какие-либо данные, необходимо каждый раз просматривать все записи. Для ускорения выполнения запросов применяются индексы, или ключи. Индексированные поля всегда поддерживаются в отсортированном состоянии, что позволяет быстро найти необходимую запись, не просматривая все записи. Надо сразу заметить, что применение индексов приводит к увеличению размера базы данных, а также к затратам времени на поддержание индекса в отсортированном состоянии при каждом добавлении данных. По этой причине индексировать следует поля, которые очень часто используются в запросах типа:
SELECT <Список полей> FROM <Таблица> WHERE <Поле>=<Значение>;
В SQLite существуют следующие виды индексов:
- первичный ключ;
- уникальный индекс;
- обычный индекс.
Первичный ключ служит для однозначной идентификации каждой записи в таблице. Для создания индекса в инструкции CREATE TABLE используется ключевое слово PRIMARY KEY.
Ключевое слово можно указать после описания поля или после перечисления всех полей. Второй вариант позволяет указать в качестве первичного ключа сразу несколько полей.
Посмотреть, каким образом будет выполняться запрос и какие индексы будут использоваться, позволяет SQL-команда EXPLAIN. Формат SQL-команды:
EXPLAIN [QUERY PLAN] <SQL-Запрос>
Если ключевые слова QUERY PLAN не указаны, то выводится полный список параметров и их значений. Если ключевые слова указаны, то выводится информация об используемых индексах. Для примера попробуем выполнить запрос на извлечение записей из таблицы site. В первом случае поиск произведем в поле, являющемся первичным ключом, а во втором случае - в обычном поле:

Рис.1. Запрос на извлечение записей из таблицы
В первом случае фраза USING INTEGER PRIMARY KEY означает, что при поиске будет использован первичный ключ, а во втором случае никакие индексы не используются.
В одной таблице не может быть более одного первичного ключа. А вот обычных и уникальных индексов допускается создать несколько. Для создания индекса применяется SQL-команда CREATE INDEX. Формат команды:
CREATE [UNIQUE] INDEX [IF NOT EXISTS]
[<Название базы данных>.]<Название индекса> ON <Название таблицы>
(<Название поля> [ COLLATE <Функция сравнения>] [ ASC | DESC ][, ...])
Если между ключевыми словами CREATE и INDEX указано слово UNIQUE, то создается уникальный индекс, - в этом случае дублирование данных в поле не допускается. Если слово UNIQUE не указано, то создается обычный индекс.
Все сайты в нашем каталоге распределяются по рубрикам. Это означает, что при выводе сайтов, зарегистрированных в определенной рубрике, в инструкции WHERE будет постоянно выполняться условие:
WHERE id_rubr=<Hомep рубрики> .
Чтобы ускорить выборку сайтов по номеру рубрики, создадим обычный индекс для этого поля и проверим с помощью SQL-команды EXPLAIN, задействуется ли этот индекс:

Рис.2. Использование индекса
Обратите внимание на то, что после создания индекса добавилась фраза USING INDEX index_rubr. Это означает, что теперь при поиске будет задействован индекс, и поиск будет выполняться быстрее. При выполнении запроса название индекса явным образом указывать нет необходимости. Использовать индекс или нет, SQLite решает самостоятельно. Таким образом, SQL-запрос будет выглядеть обычным образом:

Рис.3. Пример SQL-запроса
B некоторых случаях необходимо пересоздать индексы. Для этого применяется SQL-команда REINDEX. Формат команды:
REINDEX [<Название базы данных>. ]<Название таблицы или индекса>
Если указано название таблицы, то пересоздаются все существующие индексы в таблице. При задании названия индекса пересоздается только указанный индекс.
Удалить обычный и уникальный индексы позволяет SQL-команда DROP INDEX. Формат команды:
DROP INDEX [IF EXISTS] [<Название базы данных>.]<Название индекса>
Удаление индекса приводит к фрагментации файла с базой данных, в результате чего в нем появляется неиспользуемое свободное пространство. Чтобы удалить его, можно воспользоваться SQL-командой VACUUM.
Вся статистическая информация об индексах хранится в специальной таблице sqlite_stat1. Пока в ней нет никакой информации. Чтобы собрать статистическую информацию и поместить ее в эту таблицу, предназначена SQL-команда ANALYZE. Формат команды:
ANALYZE [[<Название базы данных>.]<Название таблицы>];
Выполним SQL-команду ANALYZE и выведем содержимое таблицы sqlite_stat1:
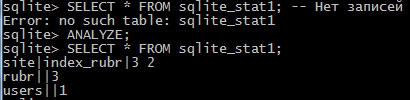
Рис.4. Пример выполнения команды ANALYZE
На следующем шаге мы рассмотрим вложенные запросы.
