На этом шаге мы рассмотрим реализацию этой головоломки.
Головоломка "Поиск слова" - это сетка букв со скрытыми словами, расположенными по строкам, столбцам и диагоналям. Разгадывая ее, игрок пытается найти скрытые слова, внимательно рассматривая сетку. Поиск мест для размещения слов таким образом, чтобы все они помещались в сетку, является своего рода задачей с ограничениями. Здесь переменные - это слова, а области определения - возможные их положения (рисунок 1).
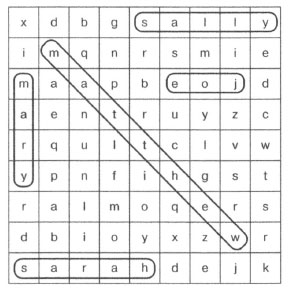
Рис.1. Классическая головоломка по поиску слов, которую можно найти в детской книге головоломок
Из соображения целесообразности поиск слов не будет включать в себя перекрывающиеся слова. Вы можете его улучшить, чтобы учесть перекрывающиеся слова.
Сетка данной задачи не очень отличается от лабиринтов, описанных ранее. Некоторые из представленных далее типов данных должны выглядеть знакомо.
from typing import NamedTuple, List, Dict, Optional from random import choice from string import ascii_uppercase from csp import CSP, Constraint Grid = List[List[str]] #вводим псевдоним для сеток class GridLocation(NamedTuple): row: int column: int
Вначале заполним сетку буквами английского алфавита (ascii_uppercase). Нам также понадобится функция для отображения сетки:
def generate_grid(rows: int, columns: int) -> Grid: # инициализируем сетку случайными буквами return [[choice(ascii_uppercase) for c in range(columns)] for r in range(rows)] def display_grid(grid: Grid) -> None: for row in grid: print("".join(row))
Чтобы выяснить, где можно расположить слова в сетке, сгенерируем их области определения. Область определения слова - это список списков возможных положений всех его букв (List [ List [GridLocation]]). Однако слова не могут располагаться где попало. Они должны находиться в пределах строки, столбца или диагонали в пределах сетки. Иначе говоря, они не должны выходить за пределы сетки. Цель функции generate_domain() - создание таких списков для каждого слова:
def generate_domain(word: str, grid: Grid) -> List[List[GridLocation]]: domain: List[List[GridLocation]] = [] height: int = len(grid) width: int = len(grid[0]) length: int = len(word) for row in range(height): for col in range(width): columns: range = range(col, col + length + 1) rows: range = range(row, row + length + 1) if col + length <= width: # слева направо domain.append([GridLocation(row, c) for c in columns]) # по диагонали снизу направо if row + length <= height: domain.append([GridLocation(r, col + (r - row)) for r in rows]) if row + length <= height: # сверху вниз domain.append([GridLocation(r, col) for r in rows]) # по диагонали снизу налево if col - length >= 0: domain.append([GridLocation(r, col - (r - row)) for r in rows]) return domain
Для определения диапазона потенциальных положений слова (вдоль строки, столбца или по диагонали) списочные выражения преобразуют диапазон в список GridLocation с помощью конструктора этого класса. Поскольку для каждого слова generate_domain() перебирает все ячейки сетки от верхней левой до нижней правой, требуется большое количество вычислений. Можете ли вы придумать способ сделать это более эффективно? Что, если одновременно просматривать все слова одинаковой длины внутри цикла?
Чтобы проверить, является ли потенциальное решение допустимым, мы должны реализовать пользовательское ограничение для поиска слова. Метод satisfied() в WordSearchConstraint просто проверяет, совпадают ли какие-то положения, предложенные для одного слова, с положением, предложенным для другого слова. Это делается с помощью set. Преобразование list в set исключит все дубликаты. Если в set, преобразованном из list, окажется меньше элементов, чем было в исходном list, это означает, что исходный list содержал несколько дубликатов. Чтобы подготовить данные для этой проверки, воспользуемся несколько более сложным генератором списков, чтобы объединить несколько подсписков положений каждого слова в присваивании в один большой список положений:
class WordSearchConstraint(Constraint[str, List[GridLocation]]): def __init__(self, words: List[str]) -> None: super().__init__(words) self.words: List[str] = words def satisfied(self, assignment: Dict[str, List[GridLocation]]) -> bool: # наличие дубликатов положений сетки означает наличие совпадения all_locations = [locs for values in assignment.values() for locs in values] return len(set(all_locations)) == len(all_locations)
Наконец-то мы готовы запустить программу. Для примера есть пять слов в сетке 9x9. Решение, которое получим, должно содержать соответствия между каждым словом и местами, где составляющие его буквы могут поместиться в сетке:
if __name__ == "__main__": grid: Grid = generate_grid(9, 9) words: List[str] = ["МАТТНЕW", "JOE", "MARY", "SARAН", "SALLY"] locations: Dict[str, List[List[GridLocation]]] = {} for word in words: locations[word] = generate_domain(word, grid) csp: CSP[str, List[GridLocation]] = CSP(words, locations) csp.add_constraint(WordSearchConstraint(words)) solution: Optional[Dict[str, List[GridLocation]]] = csp.backtracking_search() if solution is None: print("Решение не найдено!") else: for word, grid_locations in solution.items(): # в половине случаев случайным выбором - задом наперед if choice([True, False]): grid_locations.reverse() for index, letter in enumerate(word): (row, col) = (grid_locations[index].row, grid_locations[index].column) grid[row][col] = letter display_grid(grid)
В коде есть последний штрих, заполняющий сетку словами. Некоторые слова, выбранные случайным образом, располагаются задом наперед. Это корректно, поскольку данный пример не допускает наложения слов. Конечный результат должен выглядеть примерно так. Сможете ли вы найти здесь имена Matthew, Joe, Mary, Sarah, и Sally?
МАТТНЕWKY MARYNSJPE TTBOSAYXO LDVCDRLKJ QGQUDALQZ HGYTPНATT PIFVCGSNB FIVJPXADS FKPQGJLEH
На следующем шаге мы рассмотрим арифметическую головоломку.
