На этом шаге мы рассмотрим, какие программные продукты используются для машинного обучения.
Отличный способ получить представление о текущей ситуации в использовании алгоритмов и инструментов машинного обучения - это конкурсный сайт Kaggle (https://www.kaggle.com/). Благодаря соревновательному характеру (в некоторых конкурсах участвуют тысячи соискателей, а призы составляют миллионы долларов США) и широкому разнообразию задач машинного обучения Kaggle помогает реально оценить, какие существуют подходы и насколько они успешны. Так какой же алгоритм уверенно выигрывает состязания? Какими инструментами пользуются победители?
В начале 2019 года у команд, которые начиная с 2017 года попадали в пятерку лучших в любом из соревнований Kaggle, поинтересовались, какой основной программный инструмент они использовали (рисунок 1).
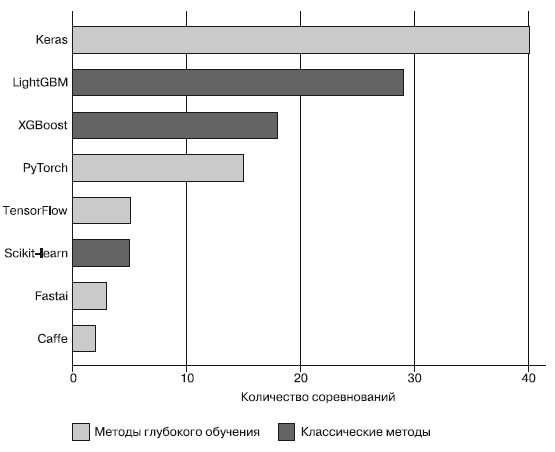
Рис.1. Инструменты машинного обучения, использовавшиеся командами, которые участвовали в конкурсах Kaggle
Как оказалось, ведущие команды отдавали предпочтение методам глубокого обучения (обычно с применением библиотеки Keras) или деревьям с градиентным бустингом (как правило, с использованием библиотеки LightGBM или XGBoost).
Впрочем, авторов исследования интересуют не только победители. Kaggle ежегодно проводит опрос среди специалистов по всему миру, профессионально занимающихся машинным обучением и обработкой данных. В нем участвуют десятки тысяч респондентов, поэтому он считается одним из самых надежных источников информации о состоянии отрасли. На рисунке 2 показан процент использования различных программных инструментов машинного обучения.
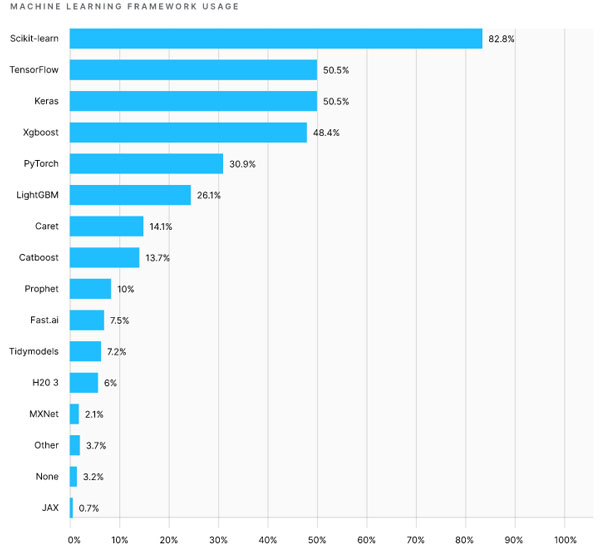
Рис.2. Использование инструментов в индустрии машинного обучения и обработки данных (источник: https://www.kaggle.com/kaggle-survey-2020)
С 2016 по 2020 год в индустрии машинного обучения и обработки данных главенствовали два подхода: метод градиентного бустинга и глубокое обучение. Метод градиентного бустинга, в частности, использовался для решения задач, где присутствовали структурированные данные, тогда как глубокое обучение применялось для решения задач распознавания, таких как классификация изображений.
Приверженцы градиентного бустинга почти всегда используют Scikit-learn, XGBoost или LightGBM. А подавляющее большинство специалистов, практикующих глубокое обучение, предпочитают библиотеку Keras, обычно в комбинации с фреймворком TensorFlow. Эти инструменты имеют одну общую черту - все они являются библиотеками на языке Python, широко используемым для решения задач машинного обучения и анализа данных.
Чтобы добиться успеха в применении машинного обучения, следует уделить особое внимание данным двум методам:
- методу градиентного бустинга (для задач поверхностного обучения) и
- глубокому обучению (для задач распознавания).
Со следующего шага мы начнем рассматривать причины, приведшие к использованию глубокого обучения.
