На этом шаге мы рассмотрим понятие плотной выборки.
Глубокое обучение действительно хорошо подходит для изучения многообразий, однако способность к обобщениям является скорее следствием естественной структуры данных, а не какого-либо свойства модели. Возможность обобщения появится только тогда, когда данные образуют множество, в котором получится интерполировать точки. Чем информативнее признаки и чем менее они зашумлены, тем проще вам будет обобщать информацию (поскольку пространство исходных данных будет проще и лучше структурировано). Курирование данных и конструирование признаков чрезвычайно важны для обобщения.
Кроме того, поскольку глубокое обучение - это подгонка кривой, то, чтобы получить надежную модель, ее необходимо обучать на плотной выборке из входного пространства. Под плотной выборкой здесь подразумевается плотное покрытие обучающими данными всей входной совокупности (рисунок 1).
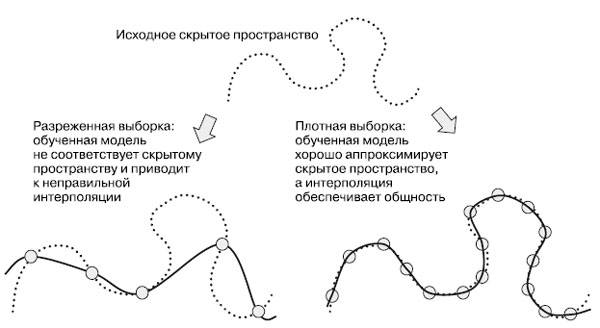
Рис.1. Чтобы получить модель, способную к точному обобщению, необходима плотная выборка
Это особенно верно вблизи границ принятия решений. При достаточно плотной выборке появляется возможность оценивать новые входные данные путем интерполяции между предыдущими входными данными без необходимости использовать здравый смысл, абстрактные рассуждения или внешние знания о мире - все то, чего не имеют модели машинного обучения.
Поэтому вы всегда должны помнить, что самый надежный способ улучшить модель глубокого обучения - это обучить ее на большом количестве данных или на более точных данных (разумеется, добавление чрезмерно зашумленных или неточных данных повредит общности). Более плотный охват входного многообразия даст модель, обладающую лучшей способностью к обобщению. Не следует ожидать, что модель глубокого обучения будет способна на что-то большее, чем простая интерполяция между обучающими образцами, поэтому старайтесь сделать все возможное, чтобы максимально интерполяцию упростить. В модели глубокого обучения вы найдете только то, что в нее вложите: априорные значения, закодированные в ее архитектуре, и данные, на которых она была обучена.
Когда получить больше данных невозможно, следующим лучшим шагом будет изменение объема информации, хранимого моделью, или добавление ограничений на гладкость кривой модели. Если сеть может позволить себе запомнить только небольшое количество закономерностей или только простые закономерности, то процесс оптимизации заставит ее сосредоточиться на наиболее выделяющихся закономерностях, которые имеют больше шансов на хорошее обобщение. Такой способ борьбы с переобучением называется регуляризацией. Мы рассмотрим методы регуляризации чуть позже.
Прежде чем приступить к настройке модели и улучшить ее общность, вы должны найти некоторый способ, который поможет оценить работу модели в данный момент. Начиная со следующего шага, вы узнаете, как наблюдать за изменением общности модели во время ее разработки.
Со следующего шага мы приступим к изучению оценки моделей машинного обучения.
